每日一题算法:2020年6月25日 单词拆分 wordBreak
2020年6月25日 单词拆分 wordBreak
默认格式:
class Solution {
public boolean wordBreak(String s, List<String> wordDict) {
}
}
解题思路:
之前做过类似的题目,这道题的难点就在于如何区分字符有部分内容重复的情况。比如下面这样
dogsxxxxxxxx…,[dog,dogs,xxxx,xxxx,…] 当你读取到dog的时候,你无法确定应该选择dog或者dogs来作为拆分开的单词,所以为了考虑到所有的情况这里需要用遍历,去判断所有符合当前条件的单词。
这样就会产生两条分支,而分支之下还能产生新的分支,所以这种情况应该使用递归的方式。
最后,如果某一条分支得到的结果是错误的,那么应该结束当前分支,返回上一次开始分支的节点开始下一次分支,这种情况需要使用回溯的算法。
既然是用到了递归,那就写一下递归需要的那些参数和实现的功能。
传入参数:数组下标、字符数组、单词链表
(这里使用字符下标+数组的组合比创建一个新的字符串更节省时间和空间)
返回值:boolean
过程:
如何匹配字符串和单词也是一个难点。
新建一个链表,第一次比较第一个字符是否相等,如果相等从单词表中取出,形成一个新的链表
然后遍历该链表中的所有字母,如果和当前字母不相等了,直接在链表中删除
如果和当前字符相等,判断是否已经达到了该字符的结尾处,如果达到了,对剩下的数组进行递归,并且在递归结束后判断结果,如果没有成功,那么在链表中删除该字母。
递归结束:
循环直到链表为空时结束,如果链表已经空了但是没有找到正确的字母,直接返回false
如果一个字母匹配时,位置已经到达了字符数组的末尾,返回true。
代码实现:
实际上还是直接使用了字符串来进行计算,因为链表里的都是字符串,如果我一边用字符串计算一边用字符数组计算就会很奇怪。
public boolean wordBreak(String s, List<String> wordDict) {
//如果数组已经为空
if (s.equals(""))
return true;
List<String> matchWordDict=new LinkedList<>();
//第一次循环,遍历这个单词数组,找出第一个字符匹配的单词
for (int i=0;i<wordDict.size();i++){
//如果第一个字符相等,并且长度必须小于s
if (wordDict.get(i).charAt(0)==s.charAt(0)&&wordDict.get(i).length()<=s.length()){
matchWordDict.add(wordDict.get(i));
}
}
//在第一个字符匹配的单词数组中找到第二个字符匹配的单词 ,从第二个字符开始
for (int i=1;matchWordDict.size()!=0;i++){
List<String> nowList=new LinkedList<>();
//遍历剩下的数组
for (String now:matchWordDict){
//字符匹配而且长度匹配
if (i==now.length()-1&&now.charAt(i)==s.charAt(i)){
//截取这个新的字符串
String newS=s.substring(i+1);
if (wordBreak(newS,wordDict)){
return true;
}
}
//如果单词长度只有1
else if (now.length()==1) {
//截取这个新的字符串
String newS=s.substring(1);
if (wordBreak(newS,wordDict)){
return true;
}
}
//剩下的情况就是长度还不够到达的情况,将其加入新的数组
else if (now.charAt(i)==s.charAt(i))
nowList.add(now);
}
matchWordDict=nowList;
}
return false;
}

那我就先对集合进行处理,删除掉哪些能够被集合中本身字母给替代的字母。
for (String now:wordDict){
List<String> nowList=new LinkedList<>(wordDict);
nowList.remove(now);
if (wordBreak(now, nowList)){
wordDict=nowList;
}
}
emmm好像更复杂了。还是找其他的优化方式吧。
我发现我这个算法在保存有效单词的时候有很多的LinkedList的创建很浪费时间,思前想后决定使用HashSet来存整个单词集,这样在查找的时候还可以直接用hashcode去查找。
public boolean wordBreak(String s, List<String> wordDict) {
//如果数组已经为空
if (s.equals(""))
return true;
for (String now:wordDict){
//不出现数组溢出的必要条件,长度相等
if (now.length()<=s.length()&&s.substring(0,now.length()).equals(now)){
if(wordBreak(s.substring(now.length()), wordDict))
return true;
}
}
return false;
}
最终改版:

List<String> newWordDict=new ArrayList<>();
public boolean wordBreak(String s, List<String> wordDict){
newWordDict.addAll(wordDict);
for (String now:wordDict){
newWordDict.remove(now);
//如果除了该单词以外,其他单词不能够组成该单词,则将其加回来
if (!wordBreak2(now,newWordDict)){
newWordDict.add(now);
}
}
return wordBreak2(s,newWordDict );
}
public boolean wordBreak2(String s, List<String> wordDict) {
//如果数组已经为空
if (s.equals(""))
return true;
//遍历整个集合,看一看当前字符串的开头是否存在匹配的情况。
for (String now:wordDict){
//不出现数组溢出的必要条件,长度相等
if (now.length()<=s.length()&&s.substring(0,now.length()).equals(now)){
// System.out.println(s.substring(now.length()).length());
if(wordBreak2(s.substring(now.length()), wordDict))
return true;
}
}
return false;
}
我认为我是钻进了思维的牛角尖了,还是看一下别人的解决方案吧。
精彩!!!
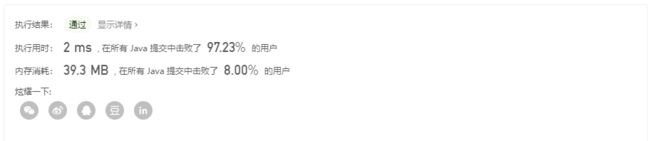
虽然不是什么很高端的算法,和我之前的做法几乎一模一样,但是通过一个简单的方案就解决了我这么长时间的困扰,用备忘录。
构建一个备忘录,记录某个节点时是否已经进行过遍历,如果已经遍历过了,那么当前这次的递归就没有做的必要了,因为结果必定是一样的,所以将其记录在备忘录中,在进行递归的过程中,查看备忘录,如果当前节点已经被判断过了,那么直接返回false.
boolean[] bs;
public boolean wordBreak(String s, List<String> wordDict) {
//初始化备忘录
if (bs==null){
bs=new boolean[s.length()];
}
//如果数组已经为空
if (s.equals(""))
return true;
//如果已经记录过该长度的字符串是无法通过的,直接返回false
if (bs[s.length()-1]){
return false;
}
//遍历整个集合,看一看当前字符串的开头是否存在匹配的情况。
for (String now:wordDict){
//不出现数组溢出的必要条件,长度相等
if (now.length()<=s.length()&&s.substring(0,now.length()).equals(now)){
if(wordBreak(s.substring(now.length()), wordDict)){
return true;
}
}
}
//到达这里说明该长度的字符串是错误的,记录下来
bs[s.length()-1]=true;
return false;
}