论文分享:2020小样本学习综述
目录
- 题目与文章脉络
- S1 介绍
- 1.1 FSL
- 1.2 FSL应用场景
- 1.3 FSL术语定义
- S2 概述
- 2.1 定义&分类&应用
- 2.2 相关机器学习问题
- 2.3 FSL核心问题
- 2.4 FSL方法分类
- 2.5 FSL方法研究现状
- S3 数据
- 3.1 数据扩充方法
- 3.2 数据扩充方法的GAP
- S4 模型
- 4.1 模型选择方法
- 4.2 模型选择方法的GAP
- S5 算法
- 5.1 优化算法方法
- 5.2 优化算法方法的GAP
- S6 未来工作
- 6.1 问题场景
- 6.2 技术
- 6.3 应用
- 6.4 理论
- S7 结论
- 参考
题目与文章脉络
- 题目:《Generalizing from a Few Examples: A Survey on Few-Shot Learning》
- 时间:2020.03.29
- 机构:香港科技大学
- 行文安排:
Section1:介绍(背景,术语)
Section2:概述(FSL定义,相关机器学习问题,核心问题,方法分类)
Section3:数据(数据增强,使FSL可行)
Section4:模型(减小假设空间大小,使FSL可行)
Section5:算法(改变算法搜索策略,使FSL可行)
Section6:未来工作(FSL在问题的设置、技术、应用、理论方面的发展方向)
Section7:结论
S1 介绍
1.1 FSL
Few-Shot Learning
1.2 FSL应用场景
(1)少样本角度:
字符生成
机器人模仿(1次性模仿,多臂强盗,视觉导航,连续控制)
药物的临床效果(隐私,安全,伦理)
FSL翻译,冷启动推荐
(2)大样本角度:
减轻标签数据收集和计算负担
1.3 FSL术语定义

S2 概述
2.1 定义&分类&应用
- 机器学习的定义:

大样本:围棋游戏需要3000万标签数据
-
小样本学习的定义:
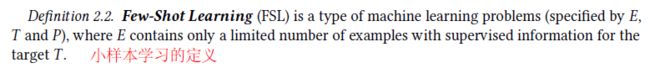
-
FSL问题分类:
(1)小样本分类
N-way-K-shot classification: N个类别,每个类K个样本
(2)小样本回归
(3)小样本强化 -
FSL典型应用场景:
(1)模仿人类学习
(2)罕见案例学习
(3)减少数据收集和计算成本。
先验:“学习器在看到例子之前对未知函数的所有信息"
prior:“any information the learner has about the unknown function before seeing the examples"
FSL的典型例子:贝叶斯学习
- 一次学习&零次学习:
one-shot learning & zero-shot learning

2.2 相关机器学习问题
(1)弱监督学习
定义: 不完整、不准确、有噪声的监督信息
分类:
- 半监督——同时使用少量有标签和大量无标签样本学习)
- 主动——无标签样本发给oracle(业务专家,贵&慢),打标签
特点:
- 分类、回归
- 利用无标签样本,作为附加信息
FSL和弱监督学习的区别:

(2)不平衡学习
定义:从经验中学y的偏态分布
特点: 训练和测试,都要覆盖所有可能的y
FSL和不平衡学习的区别:

(3)迁移学习
定义:知识丰富的域,迁到知识匮乏的域
特点:在FSL中广泛使用
(4)元学习
定义: 跨任务提取元知识(一般、本质的信息),用于改进新任务
特点: 归纳FSL的先验
四类问题和FSL的区别与联系从各自的特点分析
2.3 FSL核心问题
经验风险最小化不可靠
真实风险:
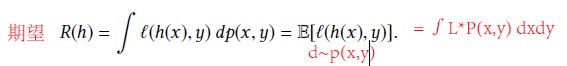
估计风险:
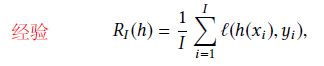
大样本和小样本学习误差对比:



2.4 FSL方法分类
- 根据先验增强途径不同,分为三类:
(1)数据(section3)
利用先验知识,增加样本数量——》减小估计误差
(2)模型(section4)
利用先验知识,缩小假设空间,使小样本数据对目前H是足够的——》
(3)算法(section5)
利用先验知识,改变搜索策略,提供好的初始化/搜索方向——》减小估计误差
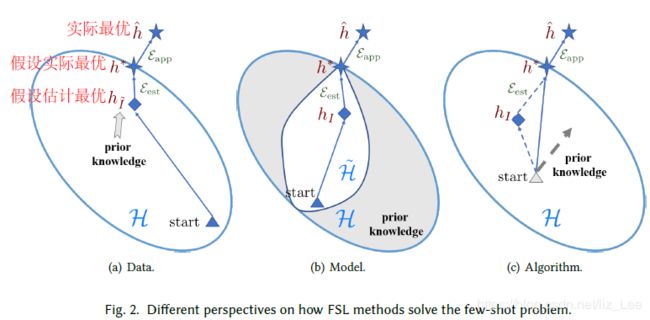
2.5 FSL方法研究现状

(1)数据
- 从训练集转变样本
- 从弱标签或无标签数据集转变样本
- 从相似数据集转变样本
(2)模型
-
多任务学习:
参数共享
参数绑定 -
嵌入学习:
特定任务嵌入
任务不变嵌入
混合嵌入 -
基于外部记忆学习:
完善表示
完善参数 -
生成式建模:
成分分解
分组共享先验
推断网络参数
(3)算法
-
完善已有参数:
通过正则化微调已有参数
聚集一系列参数
用新参数微调已有参数 -
完善元学习参数:
-
学习优化器:
S3 数据
利用先验知识扩充数据
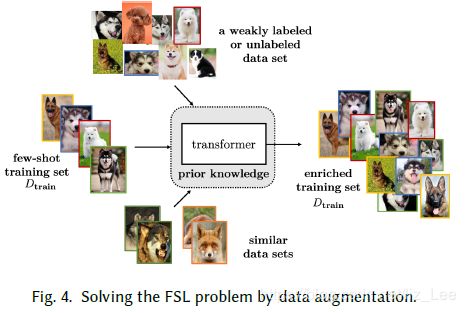
3.1 数据扩充方法
分为两类:
(1)人工方法
预处理阶段
GAP:依赖领域知识,需要昂贵劳动力成本,只针对特定数据集,应用困难
本质缺陷:人类不可能枚举所有可能不变性,不能完全解决FSL的问题
(2)自动方法

- 基于训练数据转换样本
(x,y)——》将x经过转换t,变成t(x) ——》(t(x),y) - 基于弱/无标注数据转换样本
(x,-)——》通过算法t,预测产生t(x),当做y ——》(x,t(x)) - 基于类似数据集转换样本
(x,y)——》 将相似数据集的数据经过转换t,变成当前任务所需的数据 ——》(t(x),t(y))
3.2 数据扩充方法的GAP
数据扩充一般是为数据集量身定制的,不能用在跨域数据集上
有些类型数据(文本,音频)生成后难以评价好坏(图像这类数据人眼能够辨别)
S4 模型
4.1 模型选择方法
分为四类:

(1)多任务学习
先验=其他任务,其他数据集
假设空间约束=参数共享/参数绑定
- 参数共享:
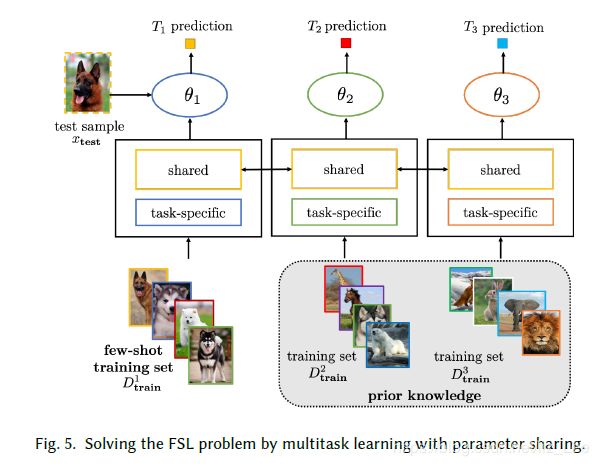
- 参数绑定:

(2)嵌入学习
先验=从/和其他任务进行嵌入学习
假设空间约束=样本投影到更小的嵌入空间(相似,不相似的样本都更容易区分)
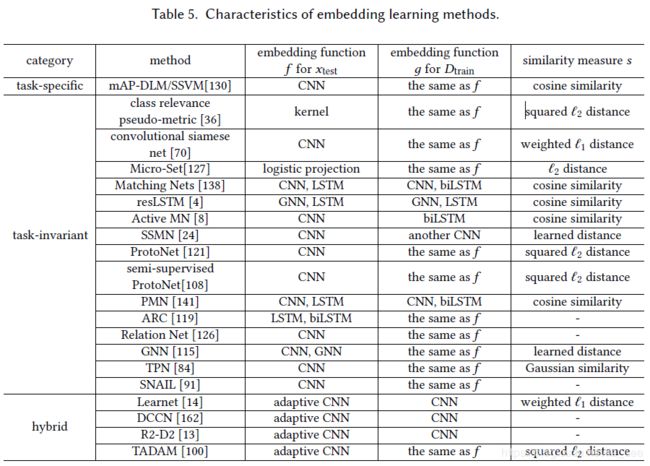
-
特定任务嵌入:
很多模型是用元学习方法学得的——MatchingNet,ProtoNet,SNAIL

-
任务不变嵌入:
-
混合嵌入:
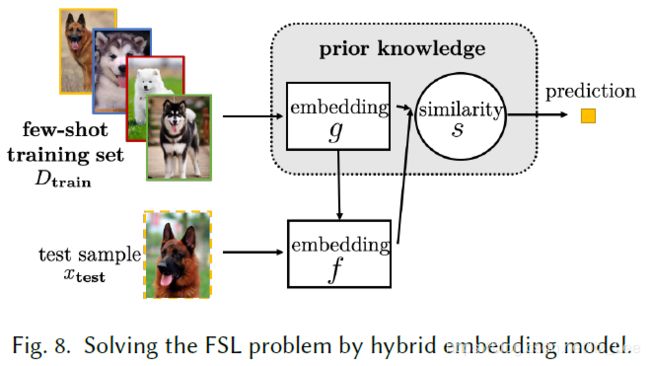
(3)基于外部记忆学习
先验=从/和其他任务进行嵌入学习,和内存交互
假设空间约束=通过内存中的键值对,完善样本

-
完善表示:
-
完善参数:
(4)生成建模
先验=从其他任务学习
假设空间约束=限制分布形式
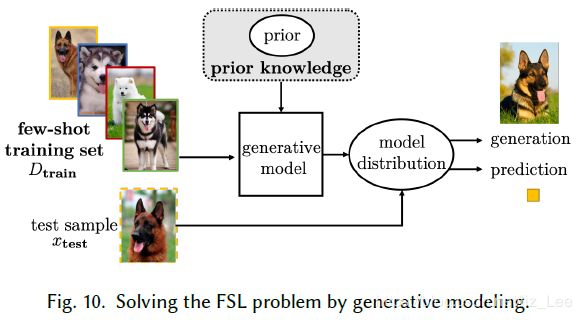
-
成分分解:
-
分组共享先验:
-
推断网络参数:
4.2 模型选择方法的GAP
(1)多任务学习
需要所有任务的联合训练,面对新的少样本任务需要重新训练,昂贵且缓慢,不适用。
(2)嵌入学习
要求任务间相关,在少样本任务和其他任务相关性不强时,不适用。
(3)基于外部内存学习
可以精心设计小内存网络,有额外内存和计算成本,外部内存有限,不适用。
(4)生成学习
需要从其他数据集学先验,推理成本高,比确定性模型更难推导
S5 算法
5.1 优化算法方法
分为三类:

(1)完善已有参数
先验=学习初始化θ
如何搜索最优假设的θ = 利用训练数据集,细化θ
- 通过正则化微调已有参数:

- 聚集一系列参数:

- 用新参数微调已有参数:
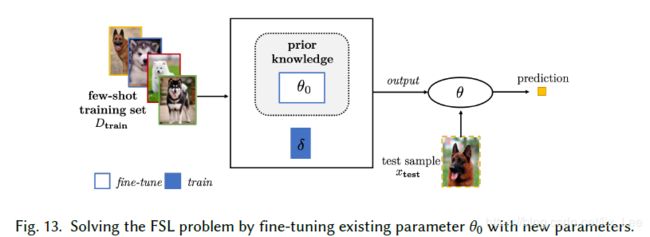
(2)完善元学习参数
先验=元学习器
如何搜索最优假设的θ = 利用训练数据集,细化θ

(3)学习优化器
先验=元学习器
如何搜索最优假设的θ = 使用元学习器提供的搜索步骤

5.2 优化算法方法的GAP
(1)参数类
参数是从不同于当前任务的其他任务中学得的,可能会牺牲精度换取速度
(2)元学习类
存在跨不同粒度学习、负迁移两方面问题
(不同粒度:动物的粗粒度,犬类的细粒度)
S6 未来工作
6.1 问题场景
目前FSL使用的先验来自单一模态
灭绝动物研究:图像信息少,文本信息多
多模态信息互补
不同模式可能包含不同结构:图像需要位置,文本需要句法
不同结构的多模态设计
6.2 技术
元学习需要任务同分布
现实中,任务数量多,但相关性未知或难以确定
目前元学习分布是静态固定的
实际上,任务分布是动态的,新任务不断到达,也应该纳入任务分布中
避免动态环境的灾难性遗忘
目前假设空间和搜索策略是认为设计的
实际上,我们期望任务感知和模型自动设计,这结合自动化特征工程,模型选择,神经结构搜索
6.3 应用
(1)计算机视觉
字符识别,图像分类,对象识别,字体样式迁移,词组接地,图像检索,对象跟踪,特定对象计数,位置识别,手势识别,零件标注,图像生成,图像跨域翻译,3D视图重建,图像字幕,视觉问答
视频:运动预测,视频分类,动作定位,人重新识别,事件监测,对象分割
(2)机器人技术
模仿:单个演示下学习机器人手臂的运动,几个演示中学习纠正动作
互动改进自己行为:多臂抢到,视觉导航,连续控制,动态环境
(3)自然语言处理
翻译示例:解析,句子填空,情绪分类,用户意图分类,刑事指控预测,词相似任务,多标签文本分类
(4)声音信号处理
一个例子的口语单词识别,语音合成,从音频样本中克隆声音,模仿父母语音讲故事,从一个用户到另一个用户的语音转换(一次性语音或文本,跨不同语言)
(5)其他
少注射药物发现,曲线拟合,通过逻辑推理理解数字类比来计算
6.4 理论
(1)样本复杂性理论
样本复杂性:获得具有高概率的小经验风险的模型所需的训练样本数量
FSL方法:利用先验知识,扩充数据,约束假设空间,改变搜索策略,降低所需的样本复杂度,弥补监督信息的缺失
(2)域适应问题
通过微调前馈神经网络可以获得更好的风险界限
考虑一个任务训练的模型转移到另一个任务的风险
(3)收敛性分析
梯度下降,元学习方法的充分条件
元学习器学习网络的底层,学习器学习最后一层
S7 结论
FSL旨在弥合人工智能和人类学习之间的差距
FSL可以通过合并历史知识,在只有几个例子下学习新任务
FSL:人工智能的试验台,罕见案例学习,工业应用中的数据负担
参考
https://zhuanlan.zhihu.com/p/138235979utm_source=wechat_session&utm_medium=social&utm_oi=1018998695244787712