数据分析-04数据分析之Pandas(二)(转)
一、Pandas统计计算和描述
示例代码:
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randn(5,4), columns = ['a', 'b', 'c', 'd'])
print(df)
运行结果:
a b c d
0 1.469682 1.948965 1.373124 -0.564129
1 -1.466670 -0.494591 0.467787 -2.007771
2 1.368750 0.532142 0.487862 -1.130825
3 -0.758540 -0.479684 1.239135 1.073077
4 -0.007470 0.997034 2.669219 0.742070
1、常用的统计计算
sum, mean, max, min…
axis=0 按列统计,axis=1按行统计
skipna 排除缺失值, 默认为True
示例代码:
print('--------sum-------')
print(df.sum())
print('--------max-------')
print(df.max())
print('--------min------')
print(df.min(axis=1, skipna=False))
运行结果:
2、常用的统计描述
describe 产生多个统计数据
示例代码:
print('----describe-------')
print(df.describe())
运行结果:
----describe-------
a b c d
count 5.000000 5.000000 5.000000 5.000000
mean 0.110632 0.306937 -0.081782 -0.382677
std 1.578243 0.767683 0.902212 1.251316
min -1.491773 -0.682076 -1.475137 -2.151721
25% -0.946890 0.020311 -0.478508 -0.619704
50% 0.091479 0.068958 0.275529 -0.543112
75% 0.290808 0.845925 0.595664 0.106920
max 2.609536 1.281567 0.673540 1.294231
常用的方法说明:

二、Pandas分组与聚合
(一)、分组 (groupby)
- 对数据集进行分组,然后对每组进行统计分析
- SQL能够对数据进行过滤,分组聚合
- pandas能利用groupby进行更加复杂的分组运算
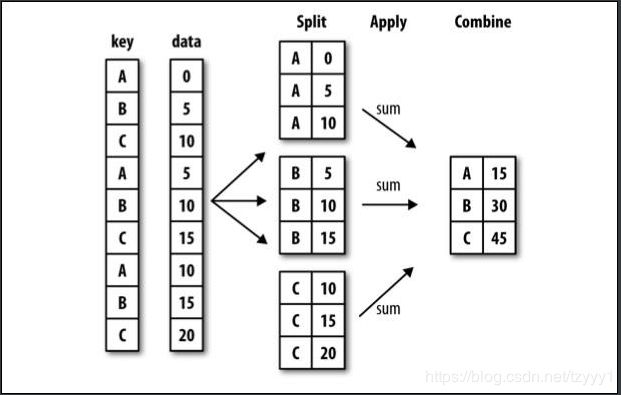
- 分组运算过程:split->apply->combine
- 拆分:进行分组的根据
- 应用:每个分组运行的计算规则
- 合并:把每个分组的计算结果合并起来
示例代码:
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randn(8),
'data2': np.random.randn(8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
运行结果:
data1 data2 key1 key2
0 0.974685 -0.672494 a one
1 -0.214324 0.758372 b one
2 1.508838 0.392787 a two
3 0.522911 0.630814 b three
4 1.347359 -0.177858 a two
5 -0.264616 1.017155 b two
6 -0.624708 0.450885 a one
7 -1.019229 -1.143825 a three
1、GroupBy对象:
DataFrameGroupBy,SeriesGroupBy
1.1. 分组操作
groupby()进行分组,GroupBy对象没有进行实际运算,只是包含分组的中间数据
按列名分组:obj.groupby(‘label’)
示例代码:
# dataframe根据key1进行分组
print(type(df_obj.groupby('key1')))
# dataframe的 data1 列根据 key1 进行分组
print(type(df_obj['data1'].groupby(df_obj['key1'])))
运行结果:
<class 'pandas.core.groupby.DataFrameGroupBy'>
<class 'pandas.core.groupby.SeriesGroupBy'>
1.2. 分组运算
对GroupBy对象进行分组运算/多重分组运算,如mean()
非数值数据不进行分组运算
示例代码:
# 分组运算
grouped1 = df_obj.groupby('key1')
print(grouped1.mean())
grouped2 = df_obj['data1'].groupby(df_obj['key1'])
print(grouped2.mean())
运行结果:
data1 data2
key1
a 0.437389 -0.230101
b 0.014657 0.802114
key1
a 0.437389
b 0.014657
Name: data1, dtype: float64
size() 返回每个分组的元素个数
示例代码:
# size
print(grouped1.size())
print(grouped2.size())
运行结果:
key1
a 5
b 3
dtype: int64
key1
a 5
b 3
dtype: int64
1.3. 按自定义的key分组
obj.groupby(self_def_key)
自定义的key可为列表或多层列表
obj.groupby([‘label1’, ‘label2’])->多层dataframe
示例代码:
# 按自定义key分组,列表
self_def_key = [0, 1, 2, 3, 3, 4, 5, 7]
print(df_obj.groupby(self_def_key).size())
# 按自定义key分组,多层列表
self_key = [df_obj['key1'], df_obj['key2']]
print(df_obj.groupby(self_key).size())
# 按多个列多层分组
grouped2 = df_obj.groupby(['key1', 'key2'])
print(grouped2.size())
# 多层分组按key的顺序进行
grouped3 = df_obj.groupby(['key2', 'key1'])
print(grouped3.mean())
# unstack可以将多层索引的结果转换成单层的dataframe
print(grouped3.mean().unstack())
2、GroupBy对象支持迭代操作
每次迭代返回一个元组 (group_name, group_data)
可用于分组数据的具体运算
2.1. 单层分组
示例代码:
# 单层分组,根据key1
for name, data in grouped1:
print(name)
print(data)
运行结果:
a
data1 data2 key1 key2
0 0.974685 -0.672494 a one
2 1.508838 0.392787 a two
4 1.347359 -0.177858 a two
6 -0.624708 0.450885 a one
7 -1.019229 -1.143825 a three
b
data1 data2 key1 key2
1 -0.214324 0.758372 b one
3 0.522911 0.630814 b three
5 -0.264616 1.017155 b two
2.2. 多层分组
示例代码:
# 多层分组,根据key1 和 key2
for group_name, group_data in grouped2:
print(group_name)
print(group_data)
运行结果:
('a', 'one')
data1 data2 key1 key2
0 0.974685 -0.672494 a one
6 -0.624708 0.450885 a one
('a', 'three')
data1 data2 key1 key2
7 -1.019229 -1.143825 a three
('a', 'two')
data1 data2 key1 key2
2 1.508838 0.392787 a two
4 1.347359 -0.177858 a two
('b', 'one')
data1 data2 key1 key2
1 -0.214324 0.758372 b one
('b', 'three')
data1 data2 key1 key2
3 0.522911 0.630814 b three
('b', 'two')
data1 data2 key1 key2
5 -0.264616 1.017155 b two
3、GroupBy对象转换成列表或字典
示例代码:
# GroupBy对象转换list
print(list(grouped1))
# GroupBy对象转换dict
print(dict(list(grouped1)))
运行结果:
[('a', data1 data2 key1 key2
0 0.974685 -0.672494 a one
2 1.508838 0.392787 a two
4 1.347359 -0.177858 a two
6 -0.624708 0.450885 a one
7 -1.019229 -1.143825 a three),
('b', data1 data2 key1 key2
1 -0.214324 0.758372 b one
3 0.522911 0.630814 b three
5 -0.264616 1.017155 b two)]
{'a': data1 data2 key1 key2
0 0.974685 -0.672494 a one
2 1.508838 0.392787 a two
4 1.347359 -0.177858 a two
6 -0.624708 0.450885 a one
7 -1.019229 -1.143825 a three,
'b': data1 data2 key1 key2
1 -0.214324 0.758372 b one
3 0.522911 0.630814 b three
5 -0.264616 1.017155 b two}
3.1. 按列分组、按数据类型分组
示例代码:
# 按列分组
print(df_obj.dtypes)
# 按数据类型分组
print(df_obj.groupby(df_obj.dtypes, axis=1).size())
print(df_obj.groupby(df_obj.dtypes, axis=1).sum())
运行结果:
data1 float64
data2 float64
key1 object
key2 object
dtype: object
float64 2
object 2
dtype: int64
float64 object
0 0.302191 a one
1 0.544048 b one
2 1.901626 a two
3 1.153725 b three
4 1.169501 a two
5 0.752539 b two
6 -0.173823 a one
7 -2.163054 a three
3.2. 其他分组方法
示例代码:
df_obj2 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['A', 'B', 'C', 'D', 'E'])
df_obj2.ix[1, 1:4] = np.NaN
print(df_obj2)
运行结果:
a b c d e
A 7 2.0 4.0 5.0 8
B 4 NaN NaN NaN 1
C 3 2.0 5.0 4.0 6
D 3 1.0 9.0 7.0 3
E 6 1.0 6.0 8.0 1
3.3. 通过字典分组
示例代码:
# 通过字典分组
mapping_dict = {'a':'Python', 'b':'Python', 'c':'Java', 'd':'C', 'e':'Java'}
print(df_obj2.groupby(mapping_dict, axis=1).size())
print(df_obj2.groupby(mapping_dict, axis=1).count()) # 非NaN的个数
print(df_obj2.groupby(mapping_dict, axis=1).sum())
运行结果:
C 1
Java 2
Python 2
dtype: int64
C Java Python
A 1 2 2
B 0 1 1
C 1 2 2
D 1 2 2
E 1 2 2
C Java Python
A 5.0 12.0 9.0
B NaN 1.0 4.0
C 4.0 11.0 5.0
D 7.0 12.0 4.0
E 8.0 7.0 7.0
3.4. 通过函数分组,函数传入的参数为行索引或列索引
示例代码:
# 通过函数分组
df_obj3 = pd.DataFrame(np.random.randint(1, 10, (5,5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['AA', 'BBB', 'CC', 'D', 'EE'])
#df_obj3
def group_key(idx):
"""
idx 为列索引或行索引
"""
#return idx
return len(idx)
print(df_obj3.groupby(group_key).size())
# 以上自定义函数等价于
#df_obj3.groupby(len).size()
运行结果:
1 1
2 3
3 1
dtype: int64
3.5. 通过索引级别分组
示例代码:
# 通过索引级别分组
columns = pd.MultiIndex.from_arrays([['Python', 'Java', 'Python', 'Java', 'Python'],
['A', 'A', 'B', 'C', 'B']], names=['language', 'index'])
df_obj4 = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)
print(df_obj4)
# 根据language进行分组
print(df_obj4.groupby(level='language', axis=1).sum())
# 根据index进行分组
print(df_obj4.groupby(level='index', axis=1).sum())
运行结果:
language Python Java Python Java Python
index A A B C B
0 2 7 8 4 3
1 5 2 6 1 2
2 6 4 4 5 2
3 4 7 4 3 1
4 7 4 3 4 8
language Java Python
0 11 13
1 3 13
2 9 12
3 10 9
4 8 18
index A B C
0 9 11 4
1 7 8 1
2 10 6 5
3 11 5 3
4 11 11 4
(二)、聚合 (aggregation)
- 数组产生标量的过程,如mean()、count()等
- 常用于对分组后的数据进行计算
示例代码:
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1,10, 8),
'data2': np.random.randint(1,10, 8)}
df_obj5 = pd.DataFrame(dict_obj)
print(df_obj5)
运行结果:
data1 data2 key1 key2
0 3 7 a one
1 1 5 b one
2 7 4 a two
3 2 4 b three
4 6 4 a two
5 9 9 b two
6 3 5 a one
7 8 4 a three
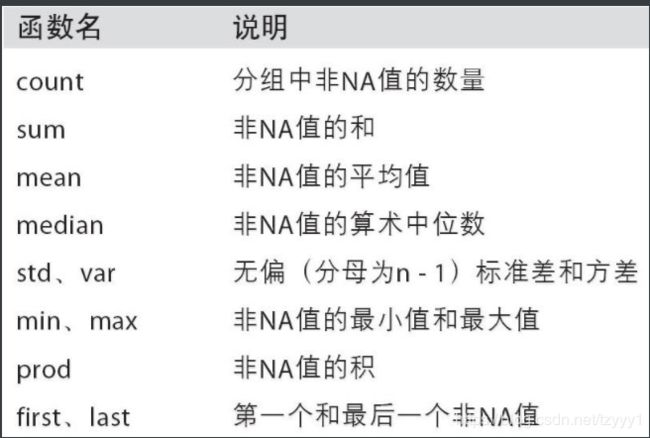
1. 内置的聚合函数
sum(), mean(), max(), min(), count(), size(), describe()
示例代码:
print(df_obj5.groupby('key1').sum())
print(df_obj5.groupby('key1').max())
print(df_obj5.groupby('key1').min())
print(df_obj5.groupby('key1').mean())
print(df_obj5.groupby('key1').size())
print(df_obj5.groupby('key1').count())
print(df_obj5.groupby('key1').describe())
运行结果:
data1 data2
key1
a 27 24
b 12 18
data1 data2 key2
key1
a 8 7 two
b 9 9 two
data1 data2 key2
key1
a 3 4 one
b 1 4 one
data1 data2
key1
a 5.4 4.8
b 4.0 6.0
key1
a 5
b 3
dtype: int64
data1 data2 key2
key1
a 5 5 5
b 3 3 3
data1 data2
key1
a count 5.000000 5.000000
mean 5.400000 4.800000
std 2.302173 1.303840
min 3.000000 4.000000
25% 3.000000 4.000000
50% 6.000000 4.000000
75% 7.000000 5.000000
max 8.000000 7.000000
b count 3.000000 3.000000
mean 4.000000 6.000000
std 4.358899 2.645751
min 1.000000 4.000000
25% 1.500000 4.500000
50% 2.000000 5.000000
75% 5.500000 7.000000
max 9.000000 9.000000
2. 可自定义函数,传入agg方法中
grouped.agg(func)
func的参数为groupby索引对应的记录
示例代码:
# 自定义聚合函数
def peak_range(df):
"""
返回数值范围
"""
#print type(df) #参数为索引所对应的记录
return df.max() - df.min()
print(df_obj5.groupby('key1').agg(peak_range))
print(df_obj.groupby('key1').agg(lambda df : df.max() - df.min()))
运行结果:
data1 data2
key1
a 5 3
b 8 5
data1 data2
key1
a 2.528067 1.594711
b 0.787527 0.386341
In [25]:
3. 应用多个聚合函数
同时应用多个函数进行聚合操作,使用函数列表
示例代码:
# 应用多个聚合函数
# 同时应用多个聚合函数
print(df_obj.groupby('key1').agg(['mean', 'std', 'count', peak_range])) # 默认列名为函数名
print(df_obj.groupby('key1').agg(['mean', 'std', 'count', ('range', peak_range)])) # 通过元组提供新的列名
运行结果:
data1 data2
mean std count peak_range mean std count peak_range
key1
a 0.437389 1.174151 5 2.528067 -0.230101 0.686488 5 1.594711
b 0.014657 0.440878 3 0.787527 0.802114 0.196850 3 0.386341
data1 data2
mean std count range mean std count range
key1
a 0.437389 1.174151 5 2.528067 -0.230101 0.686488 5 1.594711
b 0.014657 0.440878 3 0.787527 0.802114 0.196850 3 0.386341
4. 对不同的列分别作用不同的聚合函数,使用dict
示例代码:
# 每列作用不同的聚合函数
dict_mapping = {'data1':'mean',
'data2':'sum'}
print(df_obj.groupby('key1').agg(dict_mapping))
dict_mapping = {'data1':['mean','max'],
'data2':'sum'}
print(df_obj.groupby('key1').agg(dict_mapping))
运行结果:
data1 data2
key1
a 0.437389 -1.150505
b 0.014657 2.406341
data1 data2
mean max sum
key1
a 0.437389 1.508838 -1.150505
b 0.014657 0.522911 2.406341
5. 常用的内置聚合函数
(三)、数据的分组运算
示例代码:
import pandas as pd
import numpy as np
dict_obj = {'key1' : ['a', 'b', 'a', 'b',
'a', 'b', 'a', 'a'],
'key2' : ['one', 'one', 'two', 'three',
'two', 'two', 'one', 'three'],
'data1': np.random.randint(1, 10, 8),
'data2': np.random.randint(1, 10, 8)}
df_obj = pd.DataFrame(dict_obj)
print(df_obj)
# 按key1分组后,计算data1,data2的统计信息并附加到原始表格中,并添加表头前缀
k1_sum = df_obj.groupby('key1').sum().add_prefix('sum_')
print(k1_sum)
运行结果:
data1 data2 key1 key2
0 5 1 a one
1 7 8 b one
2 1 9 a two
3 2 6 b three
4 9 8 a two
5 8 3 b two
6 3 5 a one
7 8 3 a three
sum_data1 sum_data2
key1
a 26 26
b 17 17
聚合运算后会改变原始数据的形状,
如何保持原始数据的形状?
1. merge
使用merge的外连接,比较复杂
示例代码:
# 方法1,使用merge
k1_sum_merge = pd.merge(df_obj, k1_sum, left_on='key1', right_index=True)
print(k1_sum_merge)
运行结果:
data1 data2 key1 key2 sum_data1 sum_data2
0 5 1 a one 26 26
2 1 9 a two 26 26
4 9 8 a two 26 26
6 3 5 a one 26 26
7 8 3 a three 26 26
1 7 8 b one 17 17
3 2 6 b three 17 17
5 8 3 b two 17 17
2. transform
transform的计算结果和原始数据的形状保持一致,
如:grouped.transform(np.sum)
示例代码:
# 方法2,使用transform
k1_sum_tf = df_obj.groupby('key1').transform(np.sum).add_prefix('sum_')
df_obj[k1_sum_tf.columns] = k1_sum_tf
print(df_obj)
运行结果:
data1 data2 key1 key2 sum_data1 sum_data2 sum_key2
0 5 1 a one 26 26 onetwotwoonethree
1 7 8 b one 17 17 onethreetwo
2 1 9 a two 26 26 onetwotwoonethree
3 2 6 b three 17 17 onethreetwo
4 9 8 a two 26 26 onetwotwoonethree
5 8 3 b two 17 17 onethreetwo
6 3 5 a one 26 26 onetwotwoonethree
7 8 3 a three 26 26 onetwotwoonethree
也可传入自定义函数,
示例代码:
# 自定义函数传入transform
def diff_mean(s):
"""
返回数据与均值的差值
"""
return s - s.mean()
print(df_obj.groupby('key1').transform(diff_mean))
运行结果:
data1 data2 sum_data1 sum_data2
0 -0.200000 -4.200000 0 0
1 1.333333 2.333333 0 0
2 -4.200000 3.800000 0 0
3 -3.666667 0.333333 0 0
4 3.800000 2.800000 0 0
5 2.333333 -2.666667 0 0
6 -2.200000 -0.200000 0 0
7 2.800000 -2.200000 0 0
3、groupby.apply(func)
func函数也可以在各分组上分别调用,最后结果通过pd.concat组装到一起(数据合并)
示例代码:
import pandas as pd
import numpy as np
dataset_path = './starcraft.csv'
df_data = pd.read_csv(dataset_path, usecols=['LeagueIndex', 'Age', 'HoursPerWeek',
'TotalHours', 'APM'])
def top_n(df, n=3, column='APM'):
"""
返回每个分组按 column 的 top n 数据
"""
return df.sort_values(by=column, ascending=False)[:n]
print(df_data.groupby('LeagueIndex').apply(top_n))
运行结果:
LeagueIndex Age HoursPerWeek TotalHours APM
LeagueIndex
1 2214 1 20.0 12.0 730.0 172.9530
2246 1 27.0 8.0 250.0 141.6282
1753 1 20.0 28.0 100.0 139.6362
2 3062 2 20.0 6.0 100.0 179.6250
3229 2 16.0 24.0 110.0 156.7380
1520 2 29.0 6.0 250.0 151.6470
3 1557 3 22.0 6.0 200.0 226.6554
484 3 19.0 42.0 450.0 220.0692
2883 3 16.0 8.0 800.0 208.9500
4 2688 4 26.0 24.0 990.0 249.0210
1759 4 16.0 6.0 75.0 229.9122
2637 4 23.0 24.0 650.0 227.2272
5 3277 5 18.0 16.0 950.0 372.6426
93 5 17.0 36.0 720.0 335.4990
202 5 37.0 14.0 800.0 327.7218
6 734 6 16.0 28.0 730.0 389.8314
2746 6 16.0 28.0 4000.0 350.4114
1810 6 21.0 14.0 730.0 323.2506
7 3127 7 23.0 42.0 2000.0 298.7952
104 7 21.0 24.0 1000.0 286.4538
1654 7 18.0 98.0 700.0 236.0316
8 3393 8 NaN NaN NaN 375.8664
3373 8 NaN NaN NaN 364.8504
3372 8 NaN NaN NaN 355.3518
1 产生层级索引:外层索引是分组名,内层索引是df_obj的行索引
示例代码:
# apply函数接收的参数会传入自定义的函数中
print(df_data.groupby('LeagueIndex').apply(top_n, n=2, column='Age'))
运行结果:
LeagueIndex Age HoursPerWeek TotalHours APM
LeagueIndex
1 3146 1 40.0 12.0 150.0 38.5590
3040 1 39.0 10.0 500.0 29.8764
2 920 2 43.0 10.0 730.0 86.0586
2437 2 41.0 4.0 200.0 54.2166
3 1258 3 41.0 14.0 800.0 77.6472
2972 3 40.0 10.0 500.0 60.5970
4 1696 4 44.0 6.0 500.0 89.5266
1729 4 39.0 8.0 500.0 86.7246
5 202 5 37.0 14.0 800.0 327.7218
2745 5 37.0 18.0 1000.0 123.4098
6 3069 6 31.0 8.0 800.0 133.1790
2706 6 31.0 8.0 700.0 66.9918
7 2813 7 26.0 36.0 1300.0 188.5512
1992 7 26.0 24.0 1000.0 219.6690
8 3340 8 NaN NaN NaN 189.7404
3341 8 NaN NaN NaN 287.8128
2. 禁止层级索引, group_keys=False
示例代码:
print(df_data.groupby('LeagueIndex', group_keys=False).apply(top_n))
运行结果:
LeagueIndex Age HoursPerWeek TotalHours APM
2214 1 20.0 12.0 730.0 172.9530
2246 1 27.0 8.0 250.0 141.6282
1753 1 20.0 28.0 100.0 139.6362
3062 2 20.0 6.0 100.0 179.6250
3229 2 16.0 24.0 110.0 156.7380
1520 2 29.0 6.0 250.0 151.6470
1557 3 22.0 6.0 200.0 226.6554
484 3 19.0 42.0 450.0 220.0692
2883 3 16.0 8.0 800.0 208.9500
2688 4 26.0 24.0 990.0 249.0210
1759 4 16.0 6.0 75.0 229.9122
2637 4 23.0 24.0 650.0 227.2272
3277 5 18.0 16.0 950.0 372.6426
93 5 17.0 36.0 720.0 335.4990
202 5 37.0 14.0 800.0 327.7218
734 6 16.0 28.0 730.0 389.8314
2746 6 16.0 28.0 4000.0 350.4114
1810 6 21.0 14.0 730.0 323.2506
3127 7 23.0 42.0 2000.0 298.7952
104 7 21.0 24.0 1000.0 286.4538
1654 7 18.0 98.0 700.0 236.0316
3393 8 NaN NaN NaN 375.8664
3373 8 NaN NaN NaN 364.8504
3372 8 NaN NaN NaN 355.3518
apply可以用来处理不同分组内的缺失数据填充,填充该分组的均值。
三、数据清洗
- 数据清洗是数据分析关键的一步,直接影响之后的处理工作
- 数据需要修改吗?有什么需要修改的吗?数据应该怎么调整才能适用于接下来的分析和挖掘?
- 是一个迭代的过程,实际项目中可能需要不止一次地执行这些清洗操作
- 处理缺失数据:pd.fillna(),pd.dropna()
1、数据连接(pd.merge)
- pd.merge
- 根据单个或多个键将不同DataFrame的行连接起来
- 类似数据库的连接操作
示例代码:
import pandas as pd
import numpy as np
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data2' : np.random.randint(0,10,3)})
print(df_obj1)
print(df_obj2)
运行结果:
data1 key
data1 key
0 8 b
1 8 b
2 3 a
3 5 c
4 4 a
5 9 a
6 6 b
data2 key
0 9 a
1 0 b
2 3 d
1. 默认将重叠列的列名作为“外键”进行连接
示例代码:
# 默认将重叠列的列名作为“外键”进行连接
print(pd.merge(df_obj1, df_obj2))
运行结果:
data1 key data2
0 8 b 0
1 8 b 0
2 6 b 0
3 3 a 9
4 4 a 9
5 9 a 9
2. on显示指定“外键”
示例代码:
# on显示指定“外键”
print(pd.merge(df_obj1, df_obj2, on='key'))
运行结果:
data1 key data2
0 8 b 0
1 8 b 0
2 6 b 0
3 3 a 9
4 4 a 9
5 9 a 9
3. left_on,左侧数据的“外键”,right_on,右侧数据的“外键”
示例代码:
# left_on,right_on分别指定左侧数据和右侧数据的“外键”
# 更改列名
df_obj1 = df_obj1.rename(columns={'key':'key1'})
df_obj2 = df_obj2.rename(columns={'key':'key2'})
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2'))
运行结果:
data1 key1 data2 key2
0 8 b 0 b
1 8 b 0 b
2 6 b 0 b
3 3 a 9 a
4 4 a 9 a
5 9 a 9 a
默认是“内连接”(inner),即结果中的键是交集
how指定连接方式
4. “外连接”(outer),结果中的键是并集
示例代码:
# “外连接”
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='outer'))
运行结果:
data1 key1 data2 key2
0 8.0 b 0.0 b
1 8.0 b 0.0 b
2 6.0 b 0.0 b
3 3.0 a 9.0 a
4 4.0 a 9.0 a
5 9.0 a 9.0 a
6 5.0 c NaN NaN
7 NaN NaN 3.0 d
5. “左连接”(left)
示例代码:
# 左连接
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='left'))
运行结果:
data1 key1 data2 key2
0 8 b 0.0 b
1 8 b 0.0 b
2 3 a 9.0 a
3 5 c NaN NaN
4 4 a 9.0 a
5 9 a 9.0 a
6 6 b 0.0 b
6. “右连接”(right)
示例代码:
# 右连接
print(pd.merge(df_obj1, df_obj2, left_on='key1', right_on='key2', how='right'))
运行结果:
data1 key1 data2 key2
0 8.0 b 0 b
1 8.0 b 0 b
2 6.0 b 0 b
3 3.0 a 9 a
4 4.0 a 9 a
5 9.0 a 9 a
6 NaN NaN 3 d
7. 处理重复列名
suffixes,默认为_x, _y
示例代码:
# 处理重复列名
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'key': ['a', 'b', 'd'],
'data' : np.random.randint(0,10,3)})
print(pd.merge(df_obj1, df_obj2, on='key', suffixes=('_left', '_right')))
运行结果:
data_left key data_right
0 9 b 1
1 5 b 1
2 1 b 1
3 2 a 8
4 2 a 8
5 5 a 8
8. 按索引连接
left_index=True或right_index=True
示例代码:
# 按索引连接
df_obj1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1' : np.random.randint(0,10,7)})
df_obj2 = pd.DataFrame({'data2' : np.random.randint(0,10,3)}, index=['a', 'b', 'd'])
print(pd.merge(df_obj1, df_obj2, left_on='key', right_index=True))
运行结果:
data1 key data2
0 3 b 6
1 4 b 6
6 8 b 6
2 6 a 0
4 3 a 0
5 0 a 0
2、数据合并(pd.concat)
- 沿轴方向将多个对象合并到一起
1. NumPy的concat
np.concatenate
示例代码:
import numpy as np
import pandas as pd
arr1 = np.random.randint(0, 10, (3, 4))
arr2 = np.random.randint(0, 10, (3, 4))
print(arr1)
print(arr2)
print(np.concatenate([arr1, arr2]))
print(np.concatenate([arr1, arr2], axis=1))
运行结果:
# print(arr1)
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]]
# print(arr2)
[[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2]))
[[3 3 0 8]
[2 0 3 1]
[4 8 8 2]
[6 8 7 3]
[1 6 8 7]
[1 4 7 1]]
# print(np.concatenate([arr1, arr2], axis=1))
[[3 3 0 8 6 8 7 3]
[2 0 3 1 1 6 8 7]
[4 8 8 2 1 4 7 1]]
2. pd.concat
- 注意指定轴方向,默认axis=0
- join指定合并方式,默认为outer
- Series合并时查看行索引有无重复
1) index 没有重复的情况
示例代码:
# index 没有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(0,5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(5,9))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(9,12))
print(ser_obj1)
print(ser_obj2)
print(ser_obj3)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
运行结果:
# print(ser_obj1)
0 1
1 8
2 4
3 9
4 4
dtype: int64
# print(ser_obj2)
5 2
6 6
7 4
8 2
dtype: int64
# print(ser_obj3)
9 6
10 2
11 7
dtype: int64
# print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
0 1
1 8
2 4
3 9
4 4
5 2
6 6
7 4
8 2
9 6
10 2
11 7
dtype: int64
# print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1))
0 1 2
0 1.0 NaN NaN
1 5.0 NaN NaN
2 3.0 NaN NaN
3 2.0 NaN NaN
4 4.0 NaN NaN
5 NaN 9.0 NaN
6 NaN 8.0 NaN
7 NaN 3.0 NaN
8 NaN 6.0 NaN
9 NaN NaN 2.0
10 NaN NaN 3.0
11 NaN NaN 3.0
2) index 有重复的情况
示例代码:
# index 有重复的情况
ser_obj1 = pd.Series(np.random.randint(0, 10, 5), index=range(5))
ser_obj2 = pd.Series(np.random.randint(0, 10, 4), index=range(4))
ser_obj3 = pd.Series(np.random.randint(0, 10, 3), index=range(3))
print(ser_obj1)
print(ser_obj2)
print(ser_obj3)
print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
运行结果:
# print(ser_obj1)
0 0
1 3
2 7
3 2
4 5
dtype: int64
# print(ser_obj2)
0 5
1 1
2 9
3 9
dtype: int64
# print(ser_obj3)
0 8
1 7
2 9
dtype: int64
# print(pd.concat([ser_obj1, ser_obj2, ser_obj3]))
0 0
1 3
2 7
3 2
4 5
0 5
1 1
2 9
3 9
0 8
1 7
2 9
dtype: int64
# print(pd.concat([ser_obj1, ser_obj2, ser_obj3], axis=1, join='inner'))
# join='inner' 将去除NaN所在的行或列
0 1 2
0 0 5 8
1 3 1 7
2 7 9 9
3) DataFrame合并时同时查看行索引和列索引有无重复
示例代码:
df_obj1 = pd.DataFrame(np.random.randint(0, 10, (3, 2)), index=['a', 'b', 'c'],
columns=['A', 'B'])
df_obj2 = pd.DataFrame(np.random.randint(0, 10, (2, 2)), index=['a', 'b'],
columns=['C', 'D'])
print(df_obj1)
print(df_obj2)
print(pd.concat([df_obj1, df_obj2]))
print(pd.concat([df_obj1, df_obj2], axis=1, join='inner'))
运行结果:
# print(df_obj1)
A B
a 3 3
b 5 4
c 8 6
# print(df_obj2)
C D
a 1 9
b 6 8
# print(pd.concat([df_obj1, df_obj2]))
A B C D
a 3.0 3.0 NaN NaN
b 5.0 4.0 NaN NaN
c 8.0 6.0 NaN NaN
a NaN NaN 1.0 9.0
b NaN NaN 6.0 8.0
# print(pd.concat([df_obj1, df_obj2], axis=1, join='inner'))
A B C D
a 3 3 1 9
b 5 4 6 8
3、数据重构
1. stack
- 将列索引旋转为行索引,完成层级索引
- DataFrame->Series
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame(np.random.randint(0,10, (5,2)), columns=['data1', 'data2'])
print(df_obj)
stacked = df_obj.stack()
print(stacked)
运行结果:
# print(df_obj)
data1 data2
0 7 9
1 7 8
2 8 9
3 4 1
4 1 2
# print(stacked)
0 data1 7
data2 9
1 data1 7
data2 8
2 data1 8
data2 9
3 data1 4
data2 1
4 data1 1
data2 2
dtype: int64
2. unstack
- 将层级索引展开
- Series->DataFrame
- 认操作内层索引,即level=-1
示例代码:
# 默认操作内层索引
print(stacked.unstack())
# 通过level指定操作索引的级别
print(stacked.unstack(level=0))
运行结果:
# print(stacked.unstack())
data1 data2
0 7 9
1 7 8
2 8 9
3 4 1
4 1 2
# print(stacked.unstack(level=0))
0 1 2 3 4
data1 7 7 8 4 1
data2 9 8 9 1 2
4、数据转换
4.1、 处理重复数据
1 duplicated() 返回布尔型Series表示每行是否为重复行
示例代码:
import numpy as np
import pandas as pd
df_obj = pd.DataFrame({'data1' : ['a'] * 4 + ['b'] * 4,
'data2' : np.random.randint(0, 4, 8)})
print(df_obj)
print(df_obj.duplicated())
运行结果:
# print(df_obj)
data1 data2
0 a 3
1 a 2
2 a 3
3 a 3
4 b 1
5 b 0
6 b 3
7 b 0
# print(df_obj.duplicated())
0 False
1 False
2 True
3 True
4 False
5 False
6 False
7 True
dtype: bool
2 drop_duplicates() 过滤重复行
默认判断全部列
可指定按某些列判断
示例代码:
print(df_obj.drop_duplicates())
print(df_obj.drop_duplicates('data2'))
运行结果:
# print(df_obj.drop_duplicates())
data1 data2
0 a 3
1 a 2
4 b 1
5 b 0
6 b 3
# print(df_obj.drop_duplicates('data2'))
data1 data2
0 a 3
1 a 2
4 b 1
5 b 0
3. 根据map传入的函数对每行或每列进行转换
- Series根据
map传入的函数对每行或每列进行转换
示例代码:
ser_obj = pd.Series(np.random.randint(0,10,10))
print(ser_obj)
print(ser_obj.map(lambda x : x ** 2))
运行结果:
# print(ser_obj)
0 1
1 4
2 8
3 6
4 8
5 6
6 6
7 4
8 7
9 3
dtype: int64
# print(ser_obj.map(lambda x : x ** 2))
0 1
1 16
2 64
3 36
4 64
5 36
6 36
7 16
8 49
9 9
dtype: int64
4.2、数据替换
replace根据值的内容进行替换
示例代码:
# 单个值替换单个值
print(ser_obj.replace(1, -100))
# 多个值替换一个值
print(ser_obj.replace([6, 8], -100))
# 多个值替换多个值
print(ser_obj.replace([4, 7], [-100, -200]))
运行结果:
# print(ser_obj.replace(1, -100))
0 -100
1 4
2 8
3 6
4 8
5 6
6 6
7 4
8 7
9 3
dtype: int64
# print(ser_obj.replace([6, 8], -100))
0 1
1 4
2 -100
3 -100
4 -100
5 -100
6 -100
7 4
8 7
9 3
dtype: int64
# print(ser_obj.replace([4, 7], [-100, -200]))
0 1
1 -100
2 8
3 6
4 8
5 6
6 6
7 -100
8 -200
9 3
dtype: int64
四、补充知识点
1、时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式,很多统计数据以及数据的规律也都和时间序列有着非常重要的联系
而且在pandas中处理时间序列是非常简单的
pd.to_datetime( )
**pandas中的to_datetime( )有和datetime( )类似的功能。**
**(1)获取指定的时间和日期。**
eg:


**(2)将Str和Unicode转化为时间格式**
eg:
**
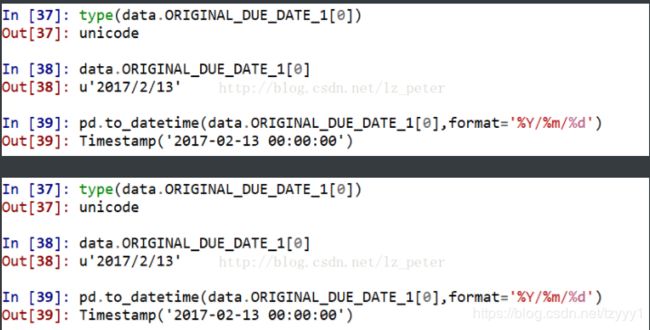
datetime 格式定义
| 代码 | 说明 |
|---|---|
| %Y | 4位数的年 |
| %y | 2位数的年 |
| %m | 2位数的月[01,12] |
| %d | 2位数的日[01,31] |
| %H | (24小时制)[00,23] |
| %l | 时(12小时制)[01,12] |
| %M | 2位数的分[00,59] |
| %S | 秒[00,61]有闰秒的存在 |
| %w | 用整数表示的星期几[0(星期天),6] |
| %F | %Y-%m-%d简写形式例如,2017-06-27 |
| %D | %m/%d/%y简写形式 |
2、读取数据
1、读取csv文件中的数据
#使用read_csv方法
pd.read_csv(file_path)
2、读取Mysql数据
要读取Mysql中的数据,首先要安装Mysqldb包。假设我数据库安装在本地,用户名位myusername,密码为mypassword,要读取mydb数据库中的数据,那么对应的代码如下:
import pandas as pd
import MySQLdb
mysql_cn= MySQLdb.connect(host='localhost', port=3306,user='myusername', passwd='mypassword', db='mydb')
df = pd.read_sql('select * from test;', con=mysql_cn)
mysql_cn.close()
上面的代码读取了test表中所有的数据到df中,而df的数据结构为Dataframe。
3、读取mongodb中的数据
#导入相应的包
import pymongo
import pandas as pd
from pandas import Series,DataFrame
#连接数据库
client = pymongo.MongoClient('localhost',27017)
ganji = client['ganji']
info = ganji['info']
#加载数据
data = DataFrame(list(info.find()))
3、set_index设置索引
DataFrame可以通过set_index方法,可以设置单索引和复合索引。
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
append添加新索引,drop为False,inplace为True时,索引将会还原为列
4、pandas之字符串的方法
temp_list = df["title"].str.split(": ").tolist()
五、案列讲解
案列一(星巴克店铺的统计数据)、
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
思路:遍历一遍,每次加1 ???
数据来源:https://www.kaggle.com/starbucks/store-locations/data
import pandas as pd
from matplotlib import pyplot as plt
from matplotlib import font_manager
my_font = font_manager.FontProperties(fname='C:\Windows\Fonts\simhei.ttf')
file_path = "./starbucks_store_worldwide.csv"
df = pd.read_csv(file_path)
df = df[df["Country"]=="CN"]
#使用matplotlib呈现出店铺总数排名前10的国家
#准备数据
data1 = df.groupby(by="City").count()["Brand"].sort_values(ascending=False)[:25]
_x = data1.index
_y = data1.values
#画图
plt.figure(figsize=(20,12),dpi=80)
# plt.bar(range(len(_x)),_y,width=0.3,color="orange")
plt.barh(range(len(_x)),_y,height=0.3,color="orange")
plt.yticks(range(len(_x)),_x,fontproperties=my_font)
plt.show()
案列二、
现在我们有全球排名靠前的10000本书的数据,那么请统计一下下面几个问题:
不同年份书的数量
不同年份书的平均评分情况
收据来源:https://www.kaggle.com/zygmunt/goodbooks-10k
代码
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./books.csv"
#读取csv文件中的数据
df = pd.read_csv(file_path)
#不同年份书的平均评分情况
#去除original_publication_year列中nan的行
data1 = df[pd.notnull(df["original_publication_year"])]
# 按年份进行分组,求平均值
grouped = data1["average_rating"].groupby(by=data1["original_publication_year"]).mean()
#返回一个Series类型的数据
print(type(grouped))
# 定义X,Y轴的数据
_x = grouped.index
_y = grouped.values
#画图
#定义图片大小
plt.figure(figsize=(20,8),dpi=80)
# 画图
plt.plot(range(len(_x)),_y)
# print(len(_x))
#设定x轴的刻度 astype:转换数组的数据类型。
plt.xticks(list(range(len(_x)))[::10],_x[::10].astype(int),rotation=45)
plt.show()
案列三、
现在我们有2015到2017年25万条911的紧急电话的数据,请统计出出这些数据中不同类型的紧急情况的次数,如果我们还想统计出不同月份不同类型紧急电话的次数的变化情况,应该怎么做呢?
数据来源:https://www.kaggle.com/mchirico/montcoalert/data
代码:
按类型分类
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
print(df.head(5))
#获取分类
# print()df["title"].str.split(": ")
temp_list = df["title"].str.split(": ").tolist()
cate_list = [i[0] for i in temp_list]
df["cate"] = pd.DataFrame(np.array(cate_list).reshape((df.shape[0],1)))
# print(df.head(5))
print(df.groupby(by="cate").count()["title"])
按月份进行统计
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv("./911.csv")
df["timeStamp"] = pd.to_datetime(df["timeStamp"])
df.set_index("timeStamp",inplace=True)
#统计出911数据中不同月份电话次数的
count_by_month = df.resample("M").count()["title"]
print(count_by_month)
#画图
_x = count_by_month.index
_y = count_by_month.values
# for i in _x:
# print(dir(i))
# break
_x = [i.strftime("%Y%m%d") for i in _x]
plt.figure(figsize=(20,8),dpi=80)
plt.plot(range(len(_x)),_y)
plt.xticks(range(len(_x)),_x,rotation=45)
plt.show()
count_by_month = df.resample("M").count()["title"]参数:
B business day frequency
C custom business day frequency (experimental)
D calendar day frequency
W weekly frequency
M month end frequency
BM business month end frequency
CBM custom business month end frequency
MS month start frequency
BMS business month start frequency
CBMS custom business month start frequency
Q quarter end frequency
BQ business quarter endfrequency
QS quarter start frequency
BQS business quarter start frequency
A year end frequency
BA business year end frequency
AS year start frequency
BAS business year start frequency
BH business hour frequency
H hourly frequency
T minutely frequency
S secondly frequency
L milliseonds
U microseconds
N nanoseconds
案列四、
现在我们有北上广、深圳、和沈阳5个城市空气质量数据,请绘制出5个城市的PM2.5随时间的变化情况
观察这组数据中的时间结构,并不是字符串,这个时候我们应该怎么办?
数据来源: https://www.kaggle.com/uciml/pm25-data-for-five-chinese-cities