阿里巴巴-口碑-上海-Java一面部分面试题
阿里巴巴-口碑-上海-Java一面部分面试题
面试 java 基础知识
- 阿里巴巴-口碑-上海-Java一面部分面试题
- 1. Jdk1.8中的HashMap实现原理?
- 2. 问: 小灰,你来说说,数据库索引为什么要使用树结构存储呢?
- 3.什么是B+树?
- 4. 如何用程序判断出链表是有环链表?
- 5. 进程和线程的区别?
- 6. 简述浏览器访问一个网页的过程?
1. Jdk1.8中的HashMap实现原理?
答:在Java8中,采用数组+链表+红黑树。HashMap的数据结构,在Jdk7中采用的是数组+链表的形式。 当hashMap 单个链表的长度超过8的时候,就会将链表转换为红黑树。加入红黑树的主要目的就在于提高在数据量很大的时候hashMap增删改查的效率。我们都知道,链表的查找效率是O(n),而在红黑树中是O(log(n))。 hashMap 中的哈希桶数组的长度为16,负载影子为0.75。 当整个哈希桶的数量超过阈值(16*0.75)时,就会进行扩容,将整个hashmap的容量扩展2倍。所有的容量都是2的倍数,这样设计的考虑主要是为了在计算key中的索引值的时候,能够取代取模运算。在hashmap中根据key的hashcode的,的高16与低16位进行与或操作。这样设计的目的就是,希望在hashmap的长度不是很长的时候,高位的bit位也能参与运算,同时性能消耗也不大。HashMap的取值运算 先做与或运算再求与。 在JDK8 中对hashMap的值进行统计了,在resize中的时候,不需要重新计算hashcode。由前面可以看到,哈希桶的索引计算如下。
000000000000010 100111000101101 由key计算hashcode
000000000000010 高位16
100111000101001 和低16
100111000101011 与或
000000000001011 与索引16相与
当需要扩展的时候,我们只需要计算在32位相与的时候新增加的位是0还是1,如果0,则保持不变,如果为1,则扩展到新的位置。新位置为原始位置+16
00000000000 1011
00000000001 1111具体参考链接。
来源程序员小灰
2. 问: 小灰,你来说说,数据库索引为什么要使用树结构存储呢?
答:这还不简单,树的查询效率高,而且可以保持有序。
问:既然这样,为什么索引没有使用二叉查找树来实现呢?
答:呃,这我就不明白了..二叉查找树查询的时间复杂度是 O(log(n)) O ( l o g ( n ) ) ,性能已经足够高了啊,难道B树可以比它更快?
问:其实从算法逻辑上来讲,二叉查找树的查找速度和比较次数都是最小的。但是,我们不得不考虑一个现实问题:
磁盘IO。数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个G甚至更多。当我们利用索引查询的时候,能把整个索引全部加载到内存吗?显然不可能。能做的只有逐一加载每一个磁盘页,这里的磁盘页对应着索引树的节点。

如果采用二叉树来存储索引的话,相同节点的二叉树高度相对于B树的高度更高,而高度就代表了磁盘的索引的次数。而IO的访问次数限制了数据库加载的速度。所以,二叉树的的性能并不比矮胖的B树这种多路平衡查找树效果好。B树的每一个节点最多包含k个孩子,k被称为B树的阶。k的大小取决于磁盘页的大小。
具体的B树介绍查看链接
3.什么是B+树?
B+树是基于B-树的一种变体,有着比B-树更高的查询性能。
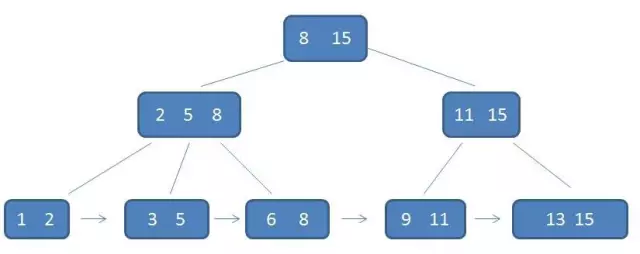
B+树的几个特点。首先,每一个父节点的元素都出现在子节点中,是子节点的最大(或最小)元素。

在上面这棵树中,根节点元素8是子节点2,5,8的最大元素,也是叶子节点6,8的最大元素。需要注意的是,根节点的最大元素(这里是15),也就等同于整个B+树的最大元素。以后无论插入删除多少元素,始终要保持最大元素在根节点当中。至于叶子节点,由于父节点的元素都出现在子节点,因此所有叶子节点包含了全量元素信息。
并且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序链表。

具体实现参考链接
4. 如何用程序判断出链表是有环链表?

方法一:简单的暴力一点的,每次遍历一个新的结点的时候,就从头结点到该结点所有的所有元素都遍历一遍,如果存在相同的元素,则说明,该元素之间存在环。时间复杂度为 O(log(n2)) O ( l o g ( n 2 ) ) 。
方法二:首先创建一个以节点ID为键的HashSet集合,用来存储曾经遍历过的节点。然后同样是从头结点开始,依次遍历单链表的每一个节点。每遍历到一个新节点,就用新节点和HashSet集合当中存储的节点作比较,如果发现HashSet当中存在相同节点ID,则说明链表有环,如果HashSet当中不存在相同的节点ID,就把这个新节点ID存入HashSet,之后进入下一节点,继续重复刚才的操作。本质上是采用空间换时间。
方法三:首先创建两个指针1和2(在java里就是两个对象引用),同时指向这个链表的头节点。然后开始一个大循环,在循环体中,让指针1每次向下移动一个节点,让指针2每次向下移动两个节点,然后比较两个指针指向的节点是否相同。如果相同,则判断出链表有环,如果不同,则继续下一次循环。
假设从链表头节点到入环点的距离是D,链表的环长是S。那么循环会进行S次(为什么是S次,有心的同学可以自己揣摩下),可以简单理解为O(N)。除了两个指针以外,没有使用任何额外存储空间,所以空间复杂度是O(1)。
问题一:判断两个单向链表是否相交,如果相交,求出交点?

答: 将其中一条链表连接到另一条链表的尾部,如果两个链表相交,那么将会存在交点,也就是说会存在环。
问题二:在一个有环链表中,如何找出链表的入环点?

答: 假设入环点距离距离链表的长度为D,环的大小为S,假设相遇的点到入环点的距离为 x x ,那么第一入环相遇满足如下条件。
由此可以知道,第一次相遇,走的慢的指针总共走了 T1=D+x T 1 = D + x 的长度,第二次相遇,走的慢的指针走了 T2=D+x+S T 2 = D + x + S ,所以,通过前后两次时间差可以确定 S S 的大小。进一步的求出 D D 的大小
参考原文链接
5. 进程和线程的区别?
能说多少说多少吧。参考链接
- 进程的划分尺度大于线程,一个程序通常至少以一个进程,而一个进程最少有一个线程。
- 进程和线程是不同操作系统对资源的管理方式。进程是操作系统分配资源的单位,线程(Thread)是进程的一个实体,是CPU调度和分派的基本单位。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。所有,启动进程的耗费的资源比线程多得多。
简洁版:
- 进程是运行中的程序,线程是进程的内部的一个执行序列
- 进程是资源分配的单元,线程是执行行单元
- 进程间切换代价大,线程间切换代价小
- 进程拥有资源多,线程拥有资源少
- 多个线程共享进程的资源
牛客网链接
6. 简述浏览器访问一个网页的过程?
我个人理解就是说明下TCP三次握手协议,其它的也搞不懂-_-||。
TCP握手协议
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接.
1. 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
SYN:同步序列编号(Synchronize Sequence Numbers)
2. 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
3. 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手.