kaggle 猫狗数据集二分类 系列(1)构建模型进行二分类,保存模型,画出走势图
系列(1)构建模型进行二分类,保存模型,画出走势图
系列(2)采用数据增强再次训练
系列(3)采用预训练网络再次训练
系列(4)使用神经网络可视化 去看网络中间层提取的特征是什么样子
可视化卷积核 Visualizing convnet filters
可视化类激活的热力图
全部代码下载
https://download.csdn.net/download/x1131230123/11788732
训练的模型下载:
https://download.csdn.net/download/x1131230123/11789104
这个实验来自于《deep learning with python》
实验取了4000张猫狗数据,利用CNN进行二分类。
采用数据增强。
采用预训练网络。
最后讲了神经网络可视化。
2013年kaggle的猫狗数据集,这个train里有2.5w张图,1.25w张猫,1.25w张狗。
命名都是cat.n或者dog.n (n是0到12499)
数据集下载地址:
https://download.csdn.net/download/qq_32796253/11037359
首先数据预处理:
模型参数 3,453,121 个
训练完后保存的cats_and_dogs_small_1.h5文件大小26.3MB
GTX1060 6G训练了差不多5分钟,等了一阵子。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
代码:
import os, shutil
original_dataset_dir = r'F:\kaggle\train'
base_dir = 'F:/kaggle/cats_and_dogs_small'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
from keras import optimizers
model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
# 数据预处理
# (1) 读取图像文件。
# (2) 将 JPEG 文件解码为 RGB 像素网格。
# (3) 将这些像素网格转换为浮点数张量。
# (4) 将像素值(0~255 范围内)缩放到 [0, 1] 区间(正如你所知,神经网络喜欢处理较小的输
# 入值)。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1. / 255)
test_datagen = ImageDataGenerator(rescale=1. / 255)
# 生成器生成了 150×150 的 RGB 图像
# [形状为 (20, 150, 150, 3) ]与二进制标签[形状为 (20,) ]组成的批量
# 每个批量中包含 20 个样本(批量大小)
# 生成器会不停地生成这些批量,它会不断循环目标文件夹中的图像
# 因此,你需要在某个时刻终止( break )迭代循环。
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
# 要知道每一轮需要从生成器中抽取多少个样本。这是 steps_per_epoch 参数的作用
# 从生成器中抽取 steps_per_epoch 个批量后(即运行了 steps_per_epoch 次梯度下降),
# 拟合过程将进入下一个轮次。本例中,每个批量包含 20 个样本,
# 所以读取完所有 2000 个样本需要 100个批量。
# 我的解释:
# 生成器一次给20例,其实就是一般fit里的batch_size
# 然后搞100次,相当于把训练数据集的2000张全训练了一次
# 平时用fit方法只给epochs和batch_size,其他的交给keras自己算
# 这里多了一个steps_per_epoch参数,其实就是让用户算算
# 为了取完训练数据集,一般这里肯定需要 训练总量=batch_size*steps_per_epoch
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
# 保存模型
model.save('cats_and_dogs_small_1.h5')
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果:
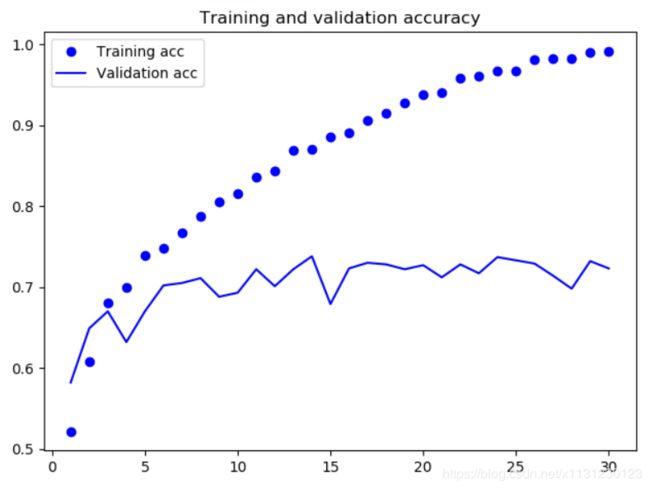
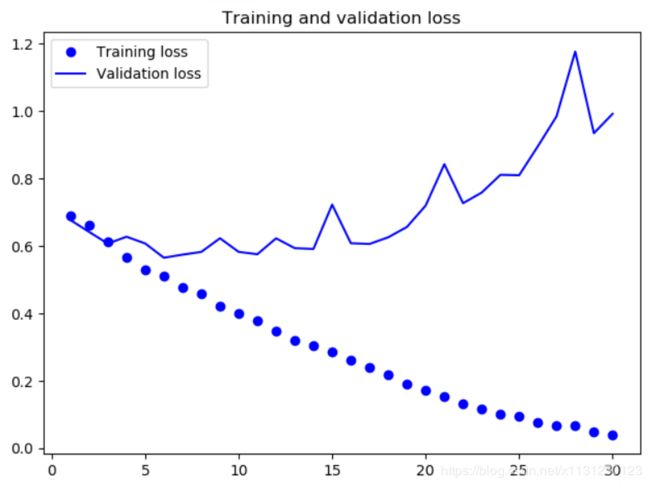
代码实验 总结与反思:
1、使用os.mkdir(字符串地址)方法创建目录;
2、使用shutil.copyfile(src, dst)复制指定文件;
3、网络中特征图的深度在逐渐增大(从 32 增大到 128),而特征图的尺寸在逐渐减小(从150×150 减小到 7×7)。这几乎是所有卷积神经网络的模式。
4、学会生成器和model.fit_generator!!
from keras.preprocessing.image import ImageDataGenerator
这个操作很骚。
我的解释:
生成器一次给20例,其实就是一般fit里的batch_size
然后搞100次,相当于把训练数据集的2000张全训练了一次
平时用fit方法只给epochs和batch_size,其他的交给keras自己算
这里多了一个steps_per_epoch参数,其实就是让用户算算
为了取完训练数据集,一般这里肯定需要 训练总量=batch_size*steps_per_epoch
5、保存模型
model.save(‘cats_and_dogs_small_1.h5’)
6、模型又过拟合了!