ConWeilin caffe训练MTCNN
ConWeilin caffe训练MTCNN
总体步骤和tensorflow配置类似TensorFlow配置MTCNN
工程版本参考https://github.com/CongWeilin/mtcnn-caffe
整个工程目录大致是这样的:
P-Net训练
1、将准备好的数据集放入./prepare_data/WIDER_train 文件夹下;
wider_face_train.txt是对应的标签文件,记录着每一张图片的annotation:
![]()
绿色表示图片地址,蓝色表示bbox(真实框的坐标,box (x_left, y_top, x_right, y_bottom))
2、执行
python ./prepare_data/gen_net_data.py
注:参数要修改,P-Net参数修改为12,R-Net修改为24,O-Net修改为48
生成12*12大小的三类图片数据
生成negative:
每张图片会生成50个 negative samples
随机大小,随机位置的裁剪一个小方块称为crop _box,如果crop_box与所有boxes的Iou都小于0.3,那么认为它是nagative sample
生成positives and part faces:
(忽略较小的box)每个box随机生成50个box,在box上进行随机偏移,Iou>=0.65的作为positive examples,0.4<=Iou<0.65的作为part faces,其他忽略
3、执行
python ./12net/gen_12net_lmdb.py
生成P-Net的数据集,存放于./12net/12/目录下,cls.lmdb用来分类,roi.lmdb用来边框回归
4、执行
./12net/runcaffe.sh
runcaffe.sh的代码如下:
#!/usr/bin/env sh
export PYTHONPATH=$PYTHONPATH:/home/caffe/mtcnn-caffe/12net
LOG=./LOG/train-`date +%Y-%m-%d-%H-%M-%S`.log
set -e
~/caffe/build/tools/caffe train \
--solver=./solver.prototxt --weights=./12net-cls-only.caffemodel 2>&1 | tee $LOG
LOG是用来记录训练日志的文件夹,可以借助caffe自带的工具画出loss曲线;weights是预训练权重,这两者都可以选择加或不加。
因为WIDER_face没有pts关键点回归,所以pythonLayer.py要进行稍改:
将训练任务从3个改为2个,读pts数据的部分注释掉,修改完如下:
# coding=utf-8
import sys
sys.path.append('/home/caffe/python')
import cv2
import caffe
import numpy as np
import random
import pickle
imdb_exit = True
def view_bar(num, total):
rate = float(num) / total
rate_num = int(rate * 100)
r = '\r[%s%s]%d%%' % ("#"*rate_num, " "*(100-rate_num), rate_num, )
sys.stdout.write(r)
sys.stdout.flush()
class Data_Layer_train(caffe.Layer):
def setup(self, bottom, top):
self.batch_size = 68
net_side = 12
cls_list = ''
roi_list = ''
pts_list = ''
cls_root = ''
roi_root = ''
pts_root = ''
self.batch_loader = BatchLoader(cls_list, roi_list, pts_list, net_side, cls_root, roi_root, pts_root)
top[0].reshape(self.batch_size, 3, net_side, net_side)
top[1].reshape(self.batch_size, 1)
top[2].reshape(self.batch_size, 4)
top[3].reshape(self.batch_size, 10)
def reshape(self, bottom, top):
pass
def forward(self, bottom, top):
#loss_task = random.randint(0, 2)
loss_task = random.randint(0, 1)
#loss_task = 1
for itt in range(self.batch_size):
im, label, roi, pts = self.batch_loader.load_next_image(loss_task)
top[0].data[itt, ...] = im
top[1].data[itt, ...] = label
top[2].data[itt, ...] = roi
top[3].data[itt, ...] = pts
def backward(self, top, propagate_down, bottom):
pass
class BatchLoader(object):
def __init__(self, cls_list, roi_list, pts_list, net_side, cls_root, roi_root, pts_root):
self.mean = 128
self.im_shape = net_side
self.cls_root = cls_root
self.roi_root = roi_root
self.pts_root = pts_root
self.roi_list = []
self.cls_list = []
self.pts_list = []
print("Start Reading Classify Data into Memory...")
if imdb_exit:
fid = open('12/cls.lmdb', 'rb')
self.cls_list = pickle.load(fid)
fid.close()
else:
fid = open(cls_list, 'rb')
lines = fid.readlines()
fid.close()
cur_ = 0
sum_ = len(lines)
for line in lines:
view_bar(cur_, sum_)
cur_ += 1
words = line.split()
image_file_name = self.cls_root + words[0] + '.jpg'
im = cv2.imread(image_file_name)
h, w, ch = im.shape
if h != self.im_shape or w != self.im_shape:
im = cv2.resize(im, (int(self.im_shape), int(self.im_shape)))
im = np.swapaxes(im, 0, 2)
im -= self.mean
label = int(words[1])
roi = [-1, -1, -1, -1]
pts = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
self.cls_list.append([im, label, roi, pts])
random.shuffle(self.cls_list)
self.cls_cur = 0
print("\n", str(len(self.cls_list)), " Classify Data have been read into Memory...")
print("Start Reading Regression Data into Memory...")
if imdb_exit:
fid = open('12/roi.lmdb', 'rb')
self.roi_list = pickle.load(fid)
fid.close()
else:
fid = open(roi_list, 'rb')
lines = fid.readlines()
fid.close()
cur_ = 0
sum_ = len(lines)
for line in lines:
view_bar(cur_, sum_)
cur_ += 1
words = line.split()
image_file_name = self.roi_root + words[0] + '.jpg'
im = cv2.imread(image_file_name)
h, w, ch = im.shape
if h != self.im_shape or w != self.im_shape:
im = cv2.resize(im, (int(self.im_shape), int(self.im_shape)))
im = np.swapaxes(im, 0, 2)
im -= self.mean
label = int(words[1])
roi = [float(words[2]), float(words[3]),float(words[4]), float(words[5])]
pts = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
self.roi_list.append([im, label, roi, pts])
random.shuffle(self.roi_list)
self.roi_cur = 0
print("\n", str(len(self.roi_list)), " Regression Data have been read into Memory...")
def load_next_image(self, loss_task):
if loss_task == 0:
if self.cls_cur == len(self.cls_list):
self.cls_cur = 0
random.shuffle(self.cls_list)
cur_data = self.cls_list[self.cls_cur] # Get the image index
im = cur_data[0]
label = cur_data[1]
roi = [-1, -1, -1, -1]
pts = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
if random.choice([0, 1]) == 1:
im = cv2.flip(im, random.choice([-1, 0, 1]))
self.cls_cur += 1
return im, label, roi, pts
if loss_task == 1:
if self.roi_cur == len(self.roi_list):
self.roi_cur = 0
random.shuffle(self.roi_list)
cur_data = self.roi_list[self.roi_cur] # Get the image index
im = cur_data[0]
label = -1
roi = cur_data[2]
pts = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
self.roi_cur += 1
return im, label, roi, pts
if loss_task == 2:
if self.pts_cur == len(self.pts_list):
self.pts_cur = 0
random.shuffle(self.pts_list)
cur_data = self.pts_list[self.pts_cur] # Get the image index
im = cur_data[0]
label = -1
roi = [-1,-1,-1,-1]
pts = cur_data[3]
self.pts_cur += 1
return im, label, roi, pts
class regression_Layer(caffe.Layer):
def setup(self, bottom, top):
if len(bottom) != 2:
raise Exception("Need 2 Inputs")
def reshape(self, bottom, top):
if bottom[0].count != bottom[1].count:
raise Exception("Input predict and groundTruth should have same dimension")
roi = bottom[1].data
self.valid_index = np.where(roi[:, 0] != -1)[0]
self.N = len(self.valid_index)
self.diff = np.zeros_like(bottom[0].data, dtype=np.float32)
top[0].reshape(1)
def forward(self, bottom, top):
# self.diff[...] = 0
top[0].data[...] = 0
if self.N != 0:
self.diff[...] = bottom[0].data - np.array(bottom[1].data).reshape(bottom[0].data.shape)
#self.diff[...] = bottom[0].data - bottom[1].data
top[0].data[...] = np.sum(self.diff**2) / bottom[0].num / 2.
def backward(self, top, propagate_down, bottom):
for i in range(2):
if not propagate_down[i] or self.N == 0:
continue
if i == 0:
sign = 1
else:
sign = -1
bottom[i].diff[...] = sign * self.diff / bottom[i].num
class cls_Layer_fc(caffe.Layer):
def setup(self, bottom, top):
if len(bottom) != 2:
raise Exception("Need 2 Inputs")
def reshape(self,bottom, top):
label = bottom[1].data
self.valid_index = np.where(label != -1)[0]
self.count = len(self.valid_index)
top[0].reshape(len(bottom[1].data), 2, 1, 1)
top[1].reshape(len(bottom[1].data), 1)
def forward(self,bottom,top):
top[0].data[...][...] = 0
top[1].data[...][...] = 0
top[0].data[0:self.count] = bottom[0].data[self.valid_index]
top[1].data[0:self.count] = bottom[1].data[self.valid_index]
def backward(self,top,propagate_down,bottom):
if propagate_down[0] and self.count != 0:
bottom[0].diff[...] = 0
bottom[0].diff[self.valid_index] = top[0].diff[...]
if propagate_down[1] and self.count != 0:
bottom[1].diff[...] = 0
bottom[1].diff[self.valid_index] = top[1].diff[...]
因为数据只使用了WIDER_train数据的1/20,所以损失收敛曲线(单独分类任务)很勉强:
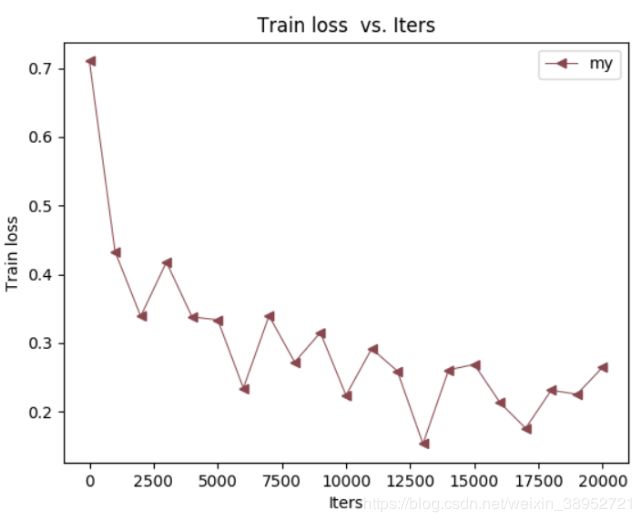
训练过程还有个瑕疵,如下图:就是roi_loss和cls_loss一次迭代只能优化其中一个。当优化roi_loss的时候,cls_loss就会保持0.693147,一直不明白这里到底为什么,有了解的读者欢迎留言。

R-Net训练
1、执行
python ./prepare_data/gen_24net_data.py
2、然后根据上一步生成的P-Net模型,生成hard样本:
执行
python ./prepare_data/gen_12net_hard_example.py
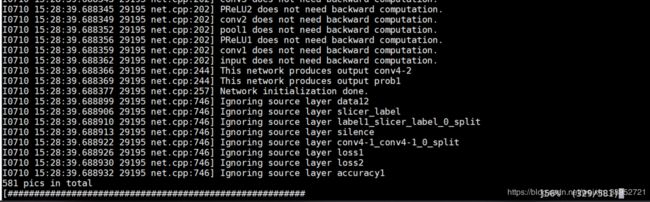
生成hard样本的过程如图,过程很慢,耐心等待;如果想要快一点,可以将导入的tools换成toos.matrix:
import tools_matrix as tools
3、执行
python ./24net/gen_24net_lmdb.py
生成R-Net的数据集,存放于./24net/24/目录下
4、执行
./24net/runcaffe.sh
O-Net训练
1、执行
python ./prepare_data/gen_48net_data.py
2、然后根据上一步生成的R-Net模型,生成hard样本:
执行
python ./prepare_data/gen_24net_hard_example.py
3、执行
python ./48net/gen_net_lmdb.py
生成R-Net的数据集,存放于./48net/48/目录下
4、执行
./48net/runcaffe.sh