百度aistudio上使用yolov4训练人脸检测模型
前几天在百度的aistudio上使用yolov4训练了一下人脸检测的模型,今天看见有人留言希望我写一篇在aistudio上如何使用yolov4的教程,纠结了一下,因为这玩意的操作流程其实在我那篇yolov4的文章以及其他人的文章中都有,只不过那些文章不是针对aistudio,想了想,最近也是好久没有更新csdn了,正好有人有这个需求,那么就写吧。
如何在aistudio上注册上的我就不说了,反正注册后进入个人中心,然后点击项目创建项目,取名添加数据集这些,如下:
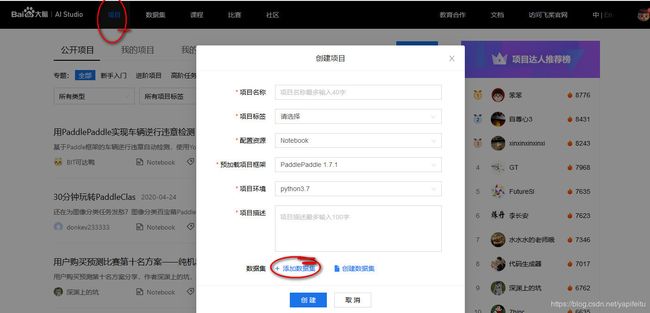 我们这里是进行人脸检测,所以需要添加的数据集叫wider_face,添加完后启动项目进入系统,进去之后选择终端,输入nvidia-smi命令,输入之后可以看见下面效果:
我们这里是进行人脸检测,所以需要添加的数据集叫wider_face,添加完后启动项目进入系统,进去之后选择终端,输入nvidia-smi命令,输入之后可以看见下面效果:
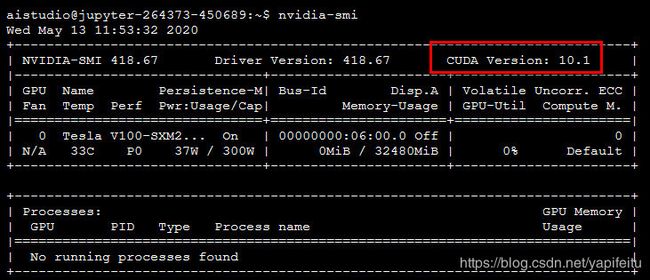 如果出现红色部分,根据我的经验,因为系统中默认安装的是cuda9.2,如果在这种情况下进行yolov4的编译会出现问题,此时我们要停止这个项目,然后再重新启动这个项目。进去之后,再在终端输入nvidia-smi命令,如果红色边框部分不存在了,那么基本上就可以编译成功了,可以进行下一步操作了。我这刚刚停止试了一下,还是存在,算了,我就不折腾了,反正之前都已经编译好了的。
如果出现红色部分,根据我的经验,因为系统中默认安装的是cuda9.2,如果在这种情况下进行yolov4的编译会出现问题,此时我们要停止这个项目,然后再重新启动这个项目。进去之后,再在终端输入nvidia-smi命令,如果红色边框部分不存在了,那么基本上就可以编译成功了,可以进行下一步操作了。我这刚刚停止试了一下,还是存在,算了,我就不折腾了,反正之前都已经编译好了的。
我们可以看看整个文件结构了,如下:
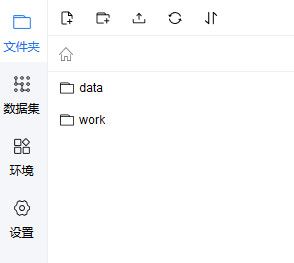 data文件夹里面就是加载的数据集,work文件夹里面默认啥都没有,我们将yolov4的文件放到这里面就行,至于yolov4的源文件和预训练模型,yolov4源代码和预训练模型,点击它就可以下载,这里要注意一下,aistudio里面只能最大上传150m的数据,而预训练模型超过了150m,所以我们可以采取第一张图片中的创建数据集的方法将这些预训练模型放到data里面,然后添加自己的数据集。
data文件夹里面就是加载的数据集,work文件夹里面默认啥都没有,我们将yolov4的文件放到这里面就行,至于yolov4的源文件和预训练模型,yolov4源代码和预训练模型,点击它就可以下载,这里要注意一下,aistudio里面只能最大上传150m的数据,而预训练模型超过了150m,所以我们可以采取第一张图片中的创建数据集的方法将这些预训练模型放到data里面,然后添加自己的数据集。
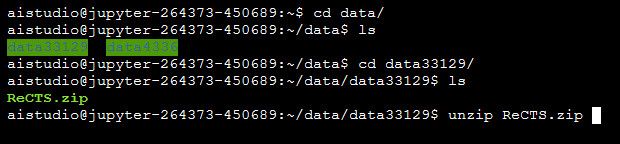
当我们将yolov4的源代码和预训练模型通过创建自己的数据集的方式放到系统的data文件夹里面之后,我们要使用cd进入文件夹,和使用uzip来解压文件,类型下面这张:
 然后我们再使用cp命令将yolov4的数据拷贝到work文件里面,哎,算了,我就不操作这一步了,相信这些基本操作对于玩aistudio的你都是小问题,是我累述了。
然后我们再使用cp命令将yolov4的数据拷贝到work文件里面,哎,算了,我就不操作这一步了,相信这些基本操作对于玩aistudio的你都是小问题,是我累述了。
接下来,我们进入yolov4的文件夹,cd ~/work/darknet-master,类似这命令行,进去之后,使用ls,我们可以看见一个makefile文件,我们使用vim命令打开这个文件,打开之后,改成下面这种:
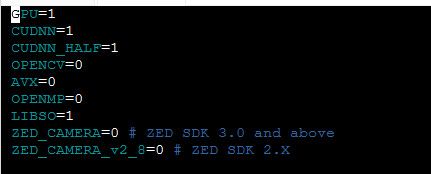 先附上作者多这些的解释:
先附上作者多这些的解释:

其中第三行你可以改也可以不改,这是针对特斯拉还有啥显卡的忘记了,恰好aistudio上就是特斯拉显卡。LIBSO也可以不改,修改完后,按esc然后:,然后输入wq,enter退出,这是vim的基本操作,大家没使用过的可以参考一下,如果使用过程出现啥问题,建议百度。修改保存后,我们又回到了yolov4的文件夹,然后直接在终端输入make,注意终端要在yolov4的文件夹下面输入make,然后就开始编译了,一般来说,编译会很正常,我遇到的编译异常就是上面那红色边框里面会显示cuda-10.1的情况,在那种情况下,我是没有成功编译成功过的,只能停止这个项目再进入,看红色边框的内容会不会消失,只要一次编译成功,后面再进入项目,不管有不有红色边框的内容,都无所谓了,反正之前就编译好了。
编译成功后,你使用ls或者直接在左端的界面打开yolov4的文件夹,会看见一个darknet程序,如果能看见,那么就代表编译成功了,接下来,我们就可以进行数据的预处理了,我们利用cd命令进入到wider_face数据存放的文件夹,我这里wider_face是放到:
 我们在命令行进入到这个文件夹,然后使用unzip命令进行解压,类似下面这种:
我们在命令行进入到这个文件夹,然后使用unzip命令进行解压,类似下面这种:
 我们主要将下面三个文件进行解压:
我们主要将下面三个文件进行解压:
 解压之后会生成下面几个文件夹:
解压之后会生成下面几个文件夹:
接下来我们就可以生成voc数据集和生成yolov4需要的数据类型了,直接给你们处理的源代码吧,也是我根据他人的源代码改的,到时候把这两个py文件放到你想放到的地方,我是放到~/work/darknet-master/data/wider_face/下面的,你到时候只需要在文件中改一两个地方然后直接运行即可:
# -*- coding: utf-8 -*-,这是转化为voc数据
import shutil
import random
import os
import string
import cv2
headstr = """\
VOC2007
%06d.jpg
My Database
PASCAL VOC2007
flickr
NULL
NULL
company
%d
%d
%d
0
"""
objstr = """\
"""
tailstr = '''\
'''
def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % ('face', bbx[0], bbx[1], bbx[0] + bbx[2], bbx[1] + bbx[3]))
f.write(tail)
f.close()
def clear_dir():
if shutil.os.path.exists(('Annotations')):
shutil.rmtree(('Annotations'))
if shutil.os.path.exists(('ImageSets')):
shutil.rmtree(('ImageSets'))
if shutil.os.path.exists(('JPEGImages')):
shutil.rmtree(('JPEGImages'))
shutil.os.mkdir(('Annotations'))
shutil.os.makedirs(('ImageSets/Main'))
shutil.os.mkdir(('JPEGImages'))
def excute_datasets(idx, datatype):
f = open(('ImageSets/Main/' + datatype + '.txt'), 'a')
f_bbx = open(('/home/aistudio/data/data4336/wider_face_split/wider_face_' + datatype + '_bbx_gt.txt'), 'r')
# 这里需要改一下,主要是data4336这里,要对应到你的加载的wider_face对应的文件夹
while True:
filename = f_bbx.readline().strip('\n')
if not filename:
break
im = cv2.imread(('/home/aistudio/data/data4336/WIDER_' + datatype + '/images/' + filename))
head = headstr % (idx, im.shape[1], im.shape[0], im.shape[2])
nums = f_bbx.readline().strip('\n')
bbxes = []
if nums=='0':
bbx_info= f_bbx.readline()
continue
for ind in range(int(nums)):
bbx_info = f_bbx.readline().strip(' \n').split(' ')
bbx = [int(bbx_info[i]) for i in range(len(bbx_info))]
# x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
if bbx[7] == 0:
bbxes.append(bbx)
writexml(idx, head, bbxes, tailstr)
shutil.copyfile(('/home/aistudio/data/data4336/WIDER_' + datatype + '/images/' + filename), ('JPEGImages/%06d.jpg' % (idx)))
f.write('%06d\n' % (idx))
idx += 1
f.close()
f_bbx.close()
return idx
if __name__ == '__main__':
clear_dir()
idx = 1
idx = excute_datasets(idx, 'train')
idx = excute_datasets(idx, 'val')
print('Complete...')
接下来是转化为yolov4需要的数据,这个文件里面没有啥需要改的,直接运行:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007_test', 'test')]#
sets=[('face', 'train'), ('face', 'val')]#
#
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["face"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if x == 0.0:
x = 0.001
if y == 0.0:
y = 0.001
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('./Annotations/%s.xml'%(image_id))
out_file = open('./labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__=='__main__':
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/JPEGImages/%s.jpg\n' % (wd, image_id))
convert_annotation(year, image_id)
list_file.close()
先运行第一个文件,然后运行第二个文件,运行完后,我们可以看见生成类型下面的文件夹结构:
 你按照上面操作,也会生成这种结构,接下来,我们使用cd …这个命令进入到darknet里面的data文件夹,然后使用touch face.data命令行创建一个文件,然后使用vim face.data命令打开这个文件,在这个文件里面输入下面的文字:
你按照上面操作,也会生成这种结构,接下来,我们使用cd …这个命令进入到darknet里面的data文件夹,然后使用touch face.data命令行创建一个文件,然后使用vim face.data命令打开这个文件,在这个文件里面输入下面的文字:
classes= 1
train = data/wider_face/face_train.txt
valid = data/wider_face/face_val.txt
#difficult = data/difficult_2007_test.txt
names = data/face.names
backup = backup/
然后再保存退出后使用touch face.names命令行,然后用vim face.names打开这个文件,然后再这个文件里面输入:
face
就这几个单词,而且就这一行,因为这代表你的类别。
好了,数据预处理我们已经处理完了,接下来,我们开始修改cfg文件,我们cd 进入yolov4的cfg文件夹,你可以使用cp命令行复制yolov4.cfg然后再修改,也可以直接修改,随你,我们这里复制然后修改名字为face.cfg,然后使用vim命令打开这个cfg,打开之后开始修改,修改的地方有:classes=80修改为classes=1, filters=255修改为filters=18,还有batch和subdivisions根据显存实际情况来修改,我这里是修改为了batch=64 ,subdivisions=16(显存为32g,如果显存为16g,将16改为32),在就是将test部分注释掉(一般cfg里面是注释掉了的,注意看一下,这里是训练模型必须操作,不然训练模型的时候会出错),类似下面这种:
 使用vim可以通过/classes这种/加上搜索的内容 来定位目标然后修改。还有一个地方要修改,mosaic=1改为mosaic=0,这里应该是跟opencv相联系的,但是在服务器上,我们没有配置opencv,所以我们这里改为0,不需要图形界面显示效果,如果不改,后面训练会出错。
使用vim可以通过/classes这种/加上搜索的内容 来定位目标然后修改。还有一个地方要修改,mosaic=1改为mosaic=0,这里应该是跟opencv相联系的,但是在服务器上,我们没有配置opencv,所以我们这里改为0,不需要图形界面显示效果,如果不改,后面训练会出错。
ok,准备工作都做完了,我们接下来,回到yolov4的文件夹,然后使用./darknet detector train data/face.data cfg/face.cfg yolov4.conv.137命令,就会出现下面的情况了:
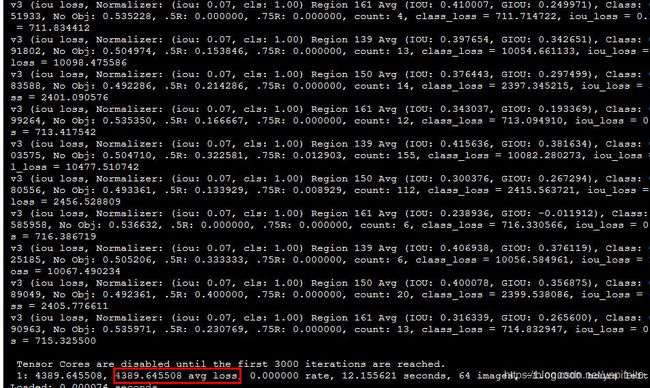 训练过程的输出很可能会出现nan的情况,只要红色边框里面的内容不出现nan,就代表训练正常。
训练过程的输出很可能会出现nan的情况,只要红色边框里面的内容不出现nan,就代表训练正常。
好了,当我的avg loss 在3左右徘徊的时候我停止了训练,然后把跑下来的模型face_lastweight拿到我自己的电脑上测试,使用命令:./darknet detector test data/face.data cfg/face.cfg face_lastweight 测试了一下,测试的效果如下:

 后面这张有一个预测错了,其余的人脸都预测到了,我后面又去训练了一下这个模型,对于第二张照片,还多预测错了一个,我怀疑是过拟合了,yolov4的作者也有专门介绍如何优化调参让模型更好的,大家有兴趣可以去看看:yolov4原作者,这篇文章,大家应该能看懂如何操作了,至于linux系统下的命令行这些,文章中说的有些潦草,感觉认真说起来就会让这篇文章太繁杂了。
后面这张有一个预测错了,其余的人脸都预测到了,我后面又去训练了一下这个模型,对于第二张照片,还多预测错了一个,我怀疑是过拟合了,yolov4的作者也有专门介绍如何优化调参让模型更好的,大家有兴趣可以去看看:yolov4原作者,这篇文章,大家应该能看懂如何操作了,至于linux系统下的命令行这些,文章中说的有些潦草,感觉认真说起来就会让这篇文章太繁杂了。
2020 5.13
ps:今天又去训练了一下其它数据,然后又遇到了几个问题,写一下:
1:在aistudio上运行py文件,这个文件里面涉及到有些路径文件的读取,但是运行这个py文件的时候,一直在提示某些文件夹不存在,我以为是权限的问题,用chmod 777还是无法解决,然后我以为是绝对路径相对路径的问题,然后改成了~/work。。。。这种,但是还是不行,最后发现,的确是路径问题,但是,不能写成 ~/work这种,要写成/home/aistudio/work。。。这种绝对路径。
2:今天运行darknet来跑模型的时候,提示:Can’t open label file. (This can be normal only if you use MSCOCO),这个问题,我最开始以为是文件编码的问题,搞了很久,但是依旧存在,后面百度了一下,发现有大佬提供解决方案:我们不是有一个labels文件夹嘛,我们将这个文件夹里面的所有txt文件全部copy一份到 跑模型过程读取照片的文件夹下面,然后这个问题就解决了。
2020 6.20