分布式锁在多实例部署,分布式系统中经常会使用到,这是因为基于jvm的锁无法满足多实例中锁的需求,本篇将讲下redis如何通过Lua脚本实现分布式锁,不同于网上的redission,完全是手动实现的
我们先来看一个无锁的情况下会导致什么问题:
这是一个普通的更新用户年龄的功能,各层代码如下,访问controller层,一个更新,一个查询

这是service层,我们使用contdownlatch发令枪来模拟线程同时并发的情况,发令枪设为32,即32个线程同时去请求修改年龄,

这里使用线程池来提交多线程任务,看代码知道,这里我们已经有了判断年龄的操作,当查询用户查询大于0时,才去调更新用户年龄-1的方法,等下看看有没有用
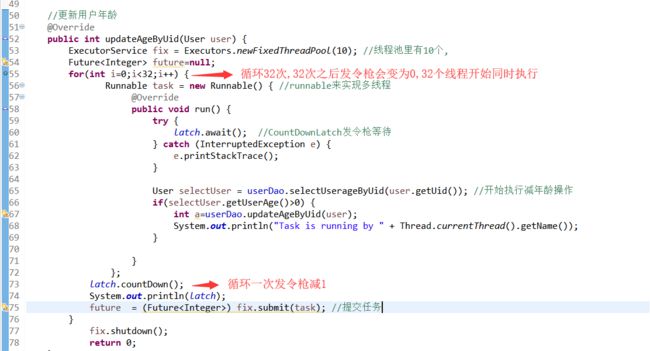
这里是sql,可以看到两个sql,一个查询用户年龄,一个会执行用户年龄每次减1 ,

这里是用户数据,我们可以看到,用户UID为UR12324的用户,他的年龄是30,接着我们来调32个线程来操作减他年龄
我们请求下这个方法
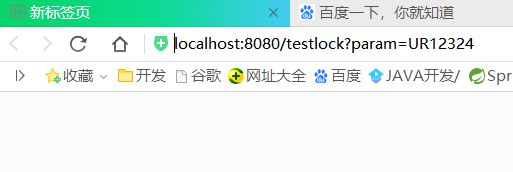
然后看看结果:


可以看到库中年龄已被减为-2,在未加锁的情况下,查询较验并没有什么作用,此时如果加个synchronized或lock锁肯定能避免这种情况,但我们本文讨论的是多实例或分布式环境中,此加锁方式仍然会产生问题,感兴趣的可以试下是不是
下面我们开始实现一个redis分布式锁,来避免这种情况发生,先说说实现思路:
1,线程请求访问前先调用加锁的方法,加锁就去里生成一个随机数同时保存在线程本地变量和redis的某key中,此key设有效期为200ms,具体值根据业务执行时间自行调整,加锁成功;
2.其它线程试着访问拿出它本地变量与redis中某key进行比较,如果不一致,则说明有锁,此线程休眠一段时间,再试着加锁;
3.加锁成功的线程在操作结束后删掉它持有锁(用lua实现,保证原子性,在它比对和删除锁的过程中,其它线程不会加锁成功),让其它线程再次加锁以执行任务;
说明:锁的时间为200ms可预防线程挂掉之后死锁,200ms后会自动释放
下面看看我们写的锁代码:
片段1:使用redislock 实现lock来复写它的方法

片段2:试着加锁的方法

片段3:解锁方法,此处首先从线程本地变量获取它的随机数,然后调用lua脚本,与redis中key相比较,如果相同则删除,否则返回0;

此为lua脚本方法,用此方法可以保证判断和删除的原子性,在此过程中没有线程可以操作此key

到此为止,我们锁基本写完,来测试下有没有用:
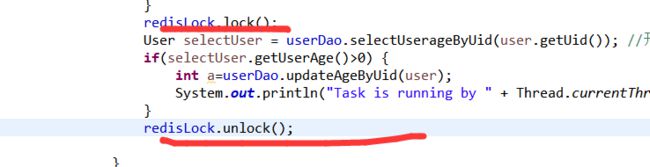
我们在此方法前后分别加入加锁和解锁方法,使用方式和lock锁一样, 我们重新把年龄恢复到30后来测试一下吧
先看看日志

这里可以看到各个线程争夺锁的情况,再看看执行结果
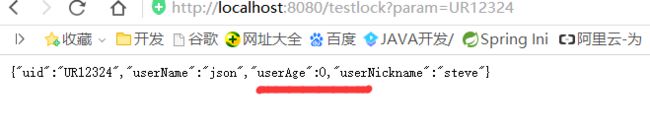
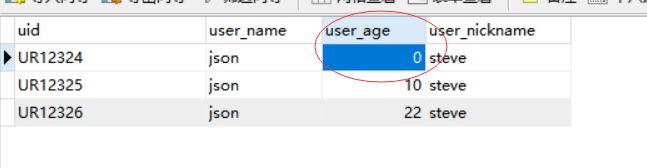
这里我们可以看到虽然是32个线程并发执行,但此值并不会变为负数,加锁成功.
我们可以看到最后2个线程并没有执行方法

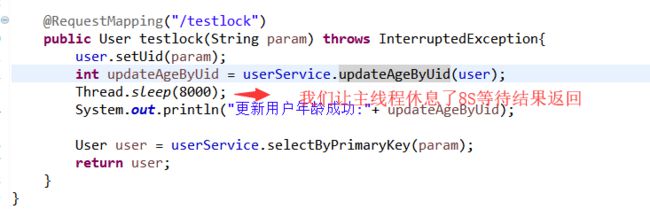
在具体生产环境中,比如典型的用户余额扣减,我们可以用用户UID作KEY,这样就不会造成100个用户,500个线程争夺一个锁的情况发生,100个用户会有100个锁,此时假如每个用户5个请求,一个锁只处理5个线程
大大提高锁的效率.
此时说明加锁成功,大家可以在分布式环境中测试更明显,有关极端情况下解锁失败后应该做什么也可以由我们自己决定,比redission要灵活,带锁的redis最好是单实例,在集群中可能会出问题,有机会我们再用zk实现下.