大数据与云计算笔记
基于VMware和Centos的大数据与云计算学习
- 1.Centos安装
- 2.网络的基本配置
- ①可能遇到的问题
- ②网络配置
- 3.Xshell的设置
- 4.主机的基本配置
- 5.zookeeper的安装配置
- 6.hadoop的安装配置
- ①传入hadoop文件
- ②解压文件
- ③配置hadoop环境变量
- ④修改hadoop配置文件
- ⑤HDFS格式化
1.Centos安装
centos ISO映像下载:link.
<使用VMwareWorkstation平台安装>
①创建新的虚拟机

②选择虚拟机硬件兼容性
默认即可
③加载linux系统ISO镜像
④虚拟机命名并定义储存位置
⑤自定义虚拟机配置
处理器配置(按需配置,下同):

内存配置:
网络配置:选择桥接模式即可

I/O控制器选择默认:
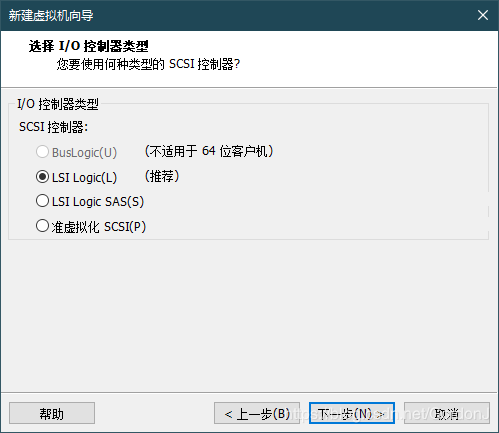
硬盘类型选择默认:
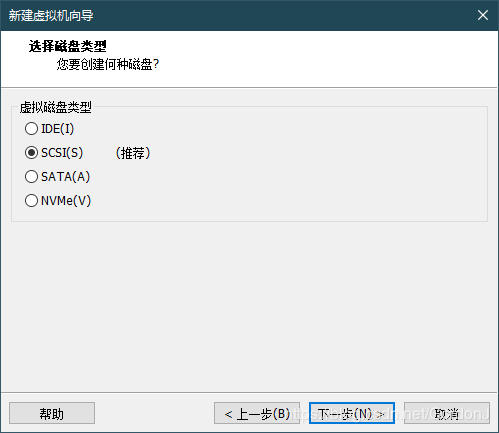
硬盘容量配置(按需分配):

⑥安装设置,开启安装

点击完成,开始安装
⑦安装

正在安装
⑧选择系统语言

⑨选择预安装软件(按需选择)

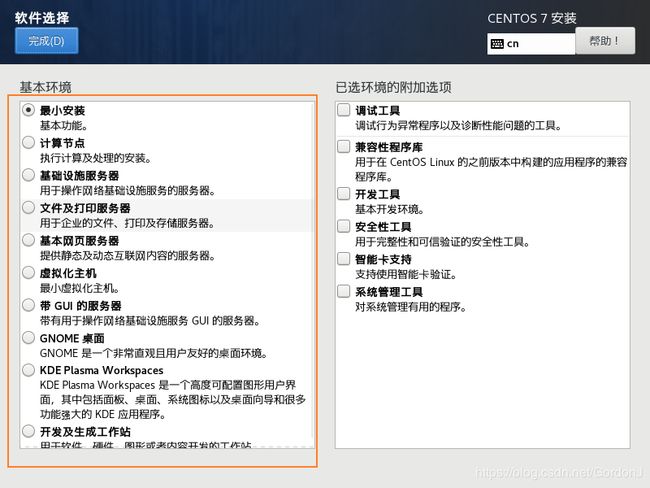
如果需要桌面环境,请选择安装GNOME桌面
(此处我并未选择)
⑩配置分区

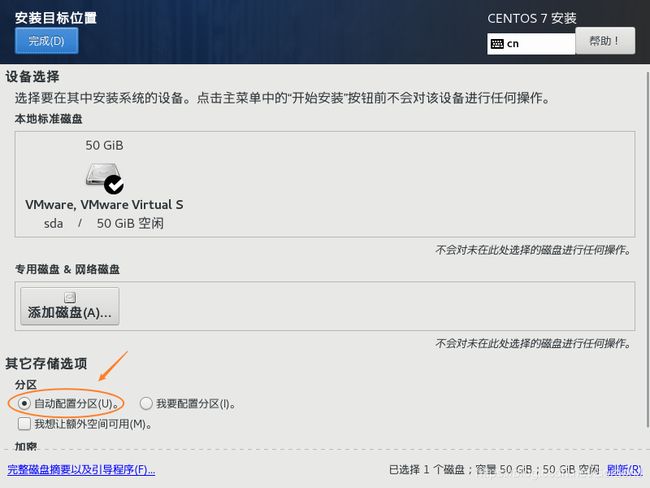
默认自动分配即可
⑪开始安装


设置root密码

安装中

⑫安装完成,重启

⑬进入系统

由于我前面安装时,选择的最小安装,所以并没有桌面环境
localhost login:root
password:123456(安装时设置的)
2.网络的基本配置
①可能遇到的问题
⑴虚拟机内Linux与宿主机无法连通

⑵虚拟机与Linux外网无法连通
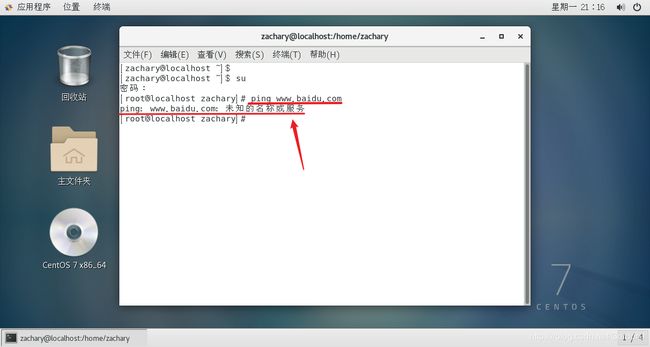
⑶虚拟机与Linux其他节点无法连通

②网络配置
⑴查看一下系统IP地址
此处可以看见系统并未设置IP地址

⑵打开虚拟网络编辑器进行设置
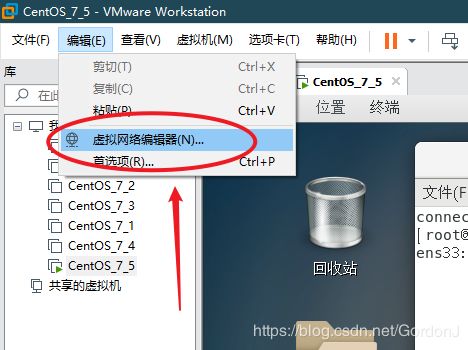
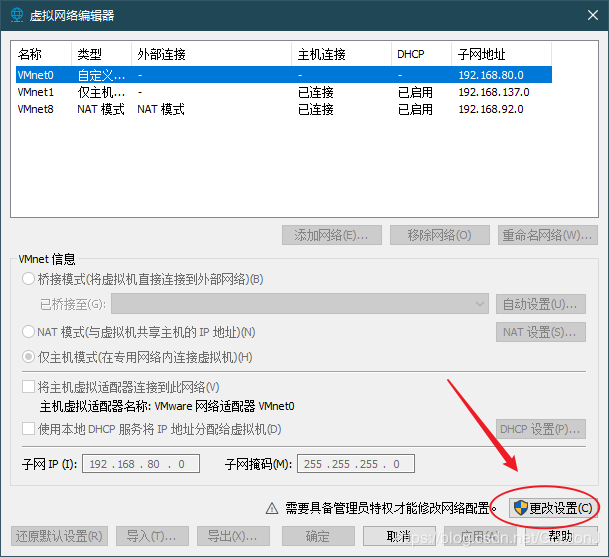
选择桥接模式,并选择宿主机的上网网卡

⑶为系统配置固定静态IP
编辑虚拟机网卡设置,使用命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改的内容如图所示:

保存并退出,重启网络,使用命令:
systemctl restart network.service
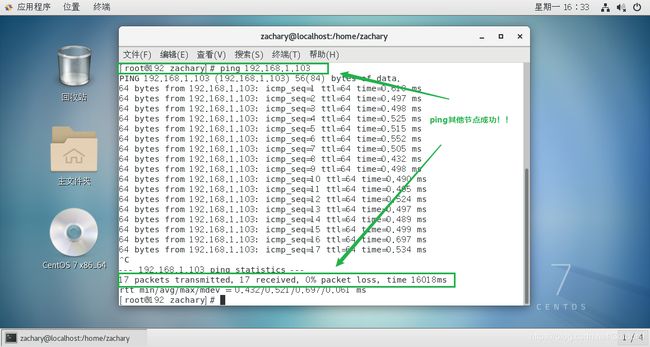
大功告成!
此时,虚拟机既可以ping通宿主机,也可以ping通其他节点

3.Xshell的设置
①打开Xshell,新建会话

②填写会话名称和主机IP
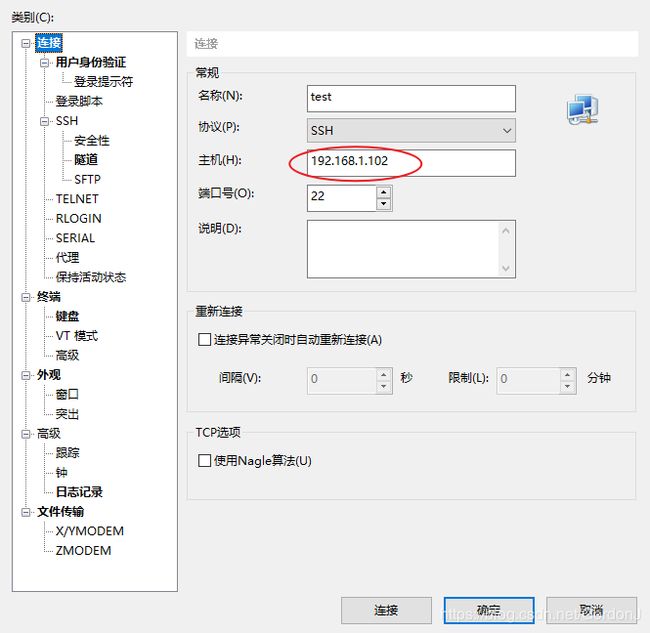
③点击用户身份验证
设置用户名为root,密码为前面设置的密码,设置完成后点击确定,连接。
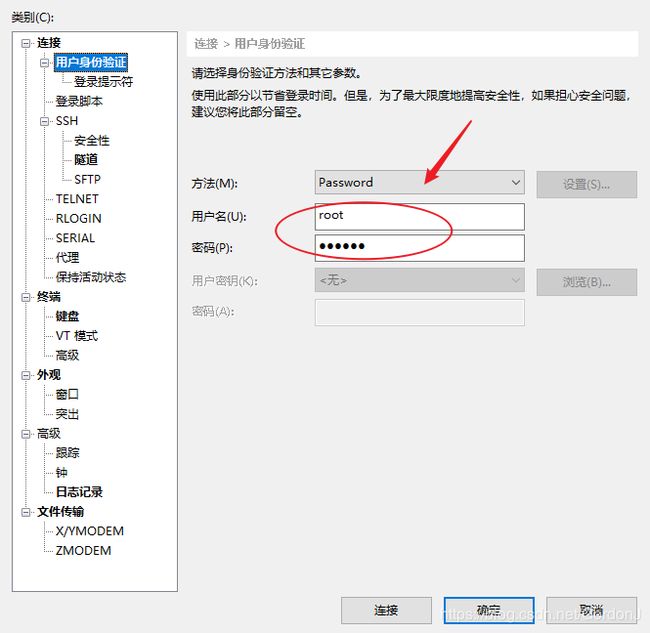
4.主机的基本配置
5.zookeeper的安装配置
①使用vi编辑器,编辑hosts文件
指令
vi /etc/hosts
在原来的文件中添加如下语句
192.168.92.128 master master.root
192.168.92.128 slave1 slave1.root
192.168.92.128 slave2 slave2.root
②将Zookeeper从电脑中传入虚拟机,按照如下步骤
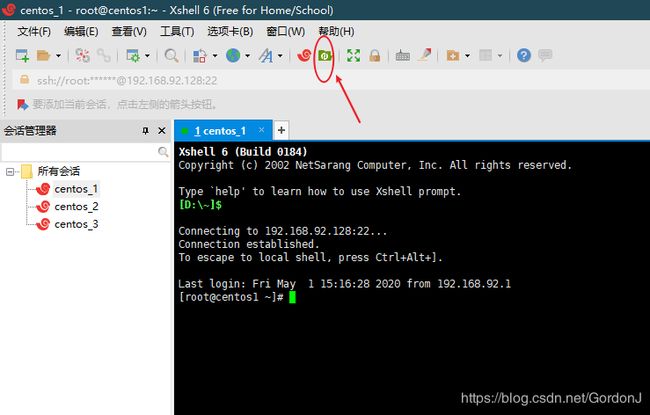
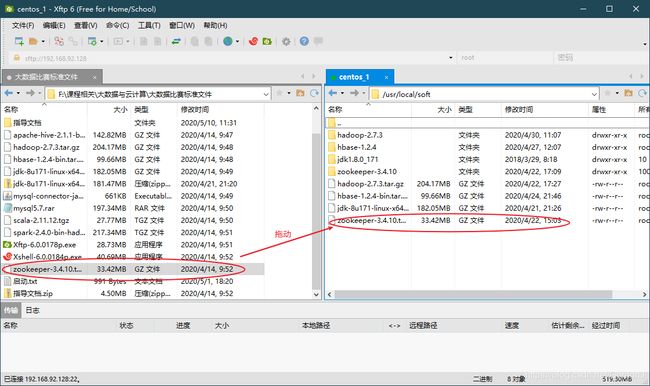
③进入zookeeper安装目录,并解压文件
进入目标目录
cd /usr/local/soft
解压文件
tar -zxvf zookeeper-3.4.10.tar.gz
解压后会出现如图所示文件
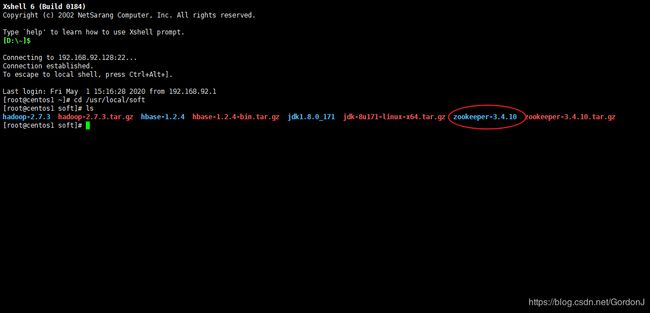
④配置zookeeper
进入conf文件夹
cd /usr/local/soft/zookeeper-3.4.10/conf
将zoo_sample.cfg复制并更名为zoo.cfg
scp zoo_sample.cfg zoo.cfg

⑤用vi编辑器打开配置文件zoo.cfg,修改参数
vi zoo.cfg
将参数修改为如图所示
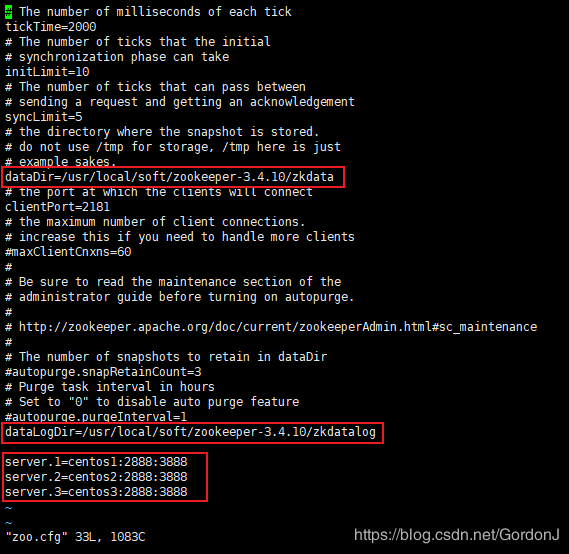
⑥添加zkdata和zkdatalog文件夹
cd /usr/local/soft/zookeeper-3.4.10/
mkdir zkdata
mkdir zkdatalog
创建好后会出现如图所示的两个文件夹

⑦进入zkdata,创建文件myid
用于表示是几号服务器,master中为1
cd zkdata
vi myid


⑧将zookeeper远程复制至两个子节点并分别修改myid
scp -r /usr/local/soft/zookeeper-3.4.10 root@slave1:/usr/local/soft/
scp -r /usr/local/soft/zookeeper-3.4.10 root@slave2:/usr/local/soft/
slave1中改为2
slave2中改为3
⑨配置zookeeper环境变量(三台虚拟机都要配置)
进入配置文件
vi /etc/profile
添加如下语句
export ZOOKEEPER_HOME=/usr/local/soft/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin
保存后退出,重新运行环境
source /etc/profile
⑩启动zookeeper
每个节点(三个都要)都启动zookeeper脚本服务
cd /usr/local/soft/zookeeper-3.4.10
bin/zkServer.sh start
bin/zkServer.sh status
6.hadoop的安装配置
①传入hadoop文件
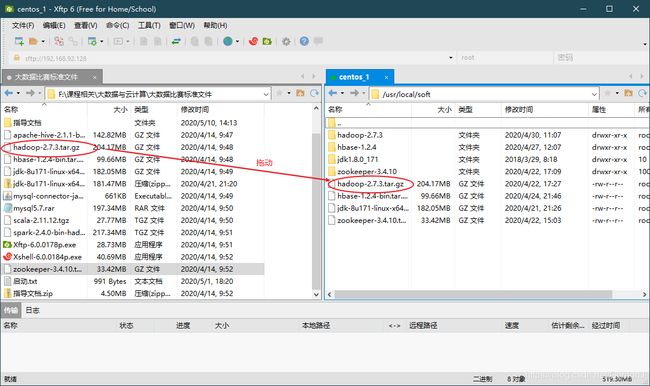
②解压文件
进入目标目录,解压文件
cd /usr/local/soft
tar -zxvf hadoop-2.7.3.tar.gz
解压完成后如图所示
![]()
③配置hadoop环境变量
vi /etc/profile
添加如下语句
export HADOOP_HOME=/usr/local/soft/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/bin
保存后退出,重新运行环境
source /etc/profile
④修改hadoop配置文件
进入hadoop文件夹
cd /usr/local/soft/hadoop-2.7.3/etc/hadoop
下图所示的是我们将要修改的一些文件

⑴修改hadoop-env.sh
vi hadoop-env.sh
添加如下语句
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171

添加后保存,退出
⑵修改core-site.xml
vi core-site.xml
添加如下语句
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.3/hdfs/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.checkpoint.period</name>
<value>60</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
</configuration>
保存后退出
⑶修改yarn-site.xml
vi yarn-site.xml
添加如下语句
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>centos1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>centos1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>centos1:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>centos1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>centos1:8088</value>
</property>
</configuration>
保存并退出
⑷修改hdfs-site.xml
vi hdfs-site.xml
添加如下语句
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/soft/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/soft/hadoop-2.7.3/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>centos1:9001</value>
</property>
<property>
<name>dfs.webhdfs</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
保存并退出
⑸修改mapred-site文件配置
hadoop没有这个文件,需要将mapred-site.xml.template复制为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
修改mapred-site.xml
vi mapred-site.xml
添加如下语句
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
保存并退出
⑹设置节点文件
新建slave文件
vi slaves
添加
slave1
slave2
新建master文件
vi master
添加
master
⑺将整个hadoop文件夹复制进子节点
scp -r /usr/local/soft/hadoop-2.7.3 root@slave1:/usr/local/soft
scp -r /usr/local/soft/hadoop-2.7.3 root@slave2:/usr/local/soft
⑤HDFS格式化
只需在namenode节点上进行
hadoop namenode -format
启动
cd /usr/local/soft/hadoop-2.7.3
sbin/start-all.sh
用jps命令可以查看是否启动成功
jps
如图所示则成功!


注意事项:重复格式化hdfs会导致datanode启动失败
解决办法: link