C语言程序设计(朱陈)-第9章 编译预处理与多文件工程程序
第9章 编译预处理与多文件工程程序
程序是写来给人读的,只是偶尔让机器执行一下。
Programs must be written for people to read, and onlyincidentally for machines to execute.
——哈若德·艾柏森(Harold Abelson),
计算机科学家学习目标:
• 掌握三种编译预处理指令
• 掌握多文件工程程序的组织方式
• 掌握模块化程序设计的基本方法
编译预处理是指令,不是语句,因此不以“;”结尾。并且编译预处理是编辑与编译之间的一步,因此不占用运行时间。一个程序如果有很多函数,通常按功能分类,每一类函数放在一个源文件中。在大型程序开发中通常采用多文件工程,即一个工程包含多个源文件。本章将分别介绍编译预处理与多文件工程程序的相关概念。
9.1编译预处理
本节要点:
• 文件包含、宏定义、条件编译等编译预处理命令的正确使用
• 无参和带参宏定义的替换过程
前面1.3.3小节介绍过,C语言的源程序编辑结束之后,在被编译之前,要进行预处理。所谓编译预处理(Preprocessor)就是编译器根据源程序中的编译预处理指令对源程序文本进行相应操作的过程。编译预处理的结果是一个删除了预处理指令、仅包含C语言语句的新的源文件,该文件才被正式编译成目标代码。编译预处理指令都以“#”开头,它不是C语言语句,结尾不带“;”号,例如:前面我们用到的#include等就是编译预处理指令。
C语言的编译预处理指令主要包括3种:
文件包含(IncludingFiles)、宏定义(Macro Definition)和条件编译(Conditional Compilation)。
9.1.1 文件包含
一个C源程序最前面的部分通常都是由文件包含指令组成的,而被包含的文件就称为头文件(Header File)。头文件是存储在磁盘上的外部文件,它主要的作用是保存程序中的声明,包括功能函数原型、数据类型的声明等。例如:我们最常用的标准输入/输出头文件stdio.h中给出了标准输入/输出函数(如scanf、printf等)的函数原型声明;头文件math.h中给出了标准数学函数(如sqrt、pow、fabs等)的函数原型声明。
文件包含指令的一般格式如下。语法:#include <头文件名>
或
#include "头文件名"
文件包含指令的功能是:在编译预处理时,将所指定的头文件名对应的头文件的内容包含到源程序中。
因此,通过#include
以上两种文件包含指令功能相同,但头文件查找方式上有所区别。
<头文件名>表示按标准方式查找头文件,即到编译系统指定的标准目录(一般为\include 目录)下去查找该头文件,若没有找到就报错。这种格式多用于包含标准头文件。
"头文件名"表示首先到当前工作目录中查找头文件,若没找到,再到编译系统指定的标准目录中查找。这种格式多用于包含用户自定义的头文件。
需要指出的是,头文件stdio.h、math.h、string.h等是由编译系统给定的,称为标准头文件,在这些标准头文件中只给出了函数的原型声明,而函数真正的完整定义、实现代码是放在库文件.LIB 或动态链接库.DLL 文件中的(出于对版权的保护,系统中提供函数的源码不对用户开放),当用户程序用到哪一个函数时,从.LIB或.DLL文件中找到相应定义,与当前程序的目标文件进行链接而成为一个可执行文件;在C语言中,程序员也可以根据需要自己定义头文件,称为用户自定义头文件,头文件的文件扩展名一般为“.h”,用户自定义头文件中可以保存用户自定义的函数原型和数据类型声明等,对应的函数定义及实现代码定义在与主文件名一致的“.c”文件中。这种编程方式在多文件工程程序中有广泛应用,具体例子见9.2节。
9.1.2 宏定义
宏定义将一个标识符定义为一个字符串。
在编译预处理时,源程序中的该标识符均以指定的字符串来代替。
因此,宏定义也称为宏替换。宏定义指令又分为无参宏指令和带参宏指令两种。
1.无参宏指令
无参宏指令的一般格式如下。
语法:#define <标识符> <字符串>
在C程序中,无参宏指令(无参宏定义)通常用于数字、字符等符号的替换,可以提高程序的通用性和易读性,减少不一致和拼写错误。
在本书2.3.5节中介绍的符号常量,就是无参宏指令的典型应用。
下面我们再举一例。
【例9.1】无参宏指令应用示例。
#include
#define PI 3.14159
#define ISPOSITIVE >0
#define FORMAT "Area=%f\n"
#define ERRMSG "Input error!\n"
int main()
{
double r;
scanf("%lf",&r); / *输入圆的半径* /
if(r ISPOSITIVE) / *若r>0则输出圆的面积,否则报错* /
{
printf(FORMAT,Pi*r*r);
}
else
{
printf(ERRMSG);
}
return 0;
} 运行此程序,
若用户从键盘输入为:
1<回车>则输出结果为:Area=3.141590
若用户从键盘输入为:−1<回车>
则输出结果为:
Input error!
说明
① 上例中,第3行至第6行定义了4个无参宏,分别是标识符PI、ISPOSITIVE、FORMAT 和 ERRMSG。通常宏定义中的标识符采用大写字母。在编译预处理时,编译器将源程序所有的宏定义标识符进行替换,即PI替换为“3.14159”,ISPOSITIVE替换为“>0”,FORMAT替换为“"Area=%f\n"”,ERRMSG替换为“"Input error!\n"”。宏替换完成后,程序才正式进行编译、链接和运行。
② 需要提醒的是:宏定义在处理时仅仅做符号替换,而不做任何类型或语法检查。所以上例中的PI只是一个符号,不是double型常量。
【例9.1】的思考题:若在本例宏定义命令的后面都加上“;”号,程序是否还能正确编译?
2.带参宏指令
带参宏指令的一般格式如下。语法:
#define <标识符> ( <参数列表> ) <字符串>
在C程序中,带参宏指令通常用于简单的函数计算的替换。
【例9.2】带参宏指令应用示例。
/*li0902.c:带参宏定义示例*/
#include
#define SUB(a,b) a-b / *带参宏定义* /
int main()
{
int a=3,b=2;
int c;
c=SUB(a,b); / *替换为:c=a-b; * /
printf("%d\n",c);
c=SUB(3,1+2); / *替换为:c=3-1+2; * /
printf("%d\n",c);
return 0;
} 运行此程序,输出结果为:
1
4
说明
说明
① 与无参宏指令类似,带参宏指令中的参数传递也仅仅是一个符号替换过程,这与普通函数实参、形参之间的值传递机制有本质区别。上例中第9行语句c=SUB(3,1+2);将替换为c=3−1+2,其计算结果为4,而不是我们期望的0。
② 为了防止这样的错误,可以在宏定义时通过给参数加“()”的方法来解决,即:#define SUB(a, b) (a) − (b),则c=SUB(3,1+2);替换为c=(3) − (1+2);,其结果为0。
【例9.2】的思考题:
若上例增加语句c=SUB(6, 2*3);,则运行后c的值为多少?
3.取消宏定义指令
所有宏定义指令(无参和带参)所定义的宏标识符都可以被取消,用取消宏定义的指令完成该功能。
取消宏定义指令的一般格式如下。
语法:
#undef <标识符>
示例:
#undef PI / *表示取消标识符PI的宏定义* /
宏定义提高了编程的灵活性,也方便程序的调试。读者可进一步查阅资料,熟练掌握这一方法。
9.1.3 条件编译
一般情况下,源程序中所有的行都参加编译。但是条件编译指令可以使得编译器按不同的条件去编译源程序不同的部分,产生不同的目标代码文件。
也就是说,通过条件编译指令,某些源程序代码要在满足一定条件下才被编译,否则将不被编译,这一指令可用于调试程序。另外,在头文件中一般都通过使用条件编译避免重复包含的错误。条件编译指令有两种常用格式。
(1)条件编译指令格式1。
语法:
#ifdef <标识符>
<程序段1>
[#else
<程序段2> ]
#endif
该条件编译指令的含义是:若<标识符>已被定义过,则编译<程序段1>;
否则,编译<程序段2>。其中,方括号[ ]中的#else部分的内容是可选的。
条件编译指令在多文件、跨平台的大型程序开发中有很重要的作用,感兴趣的读者可以自行查阅相关资料。
这里,我们举一个简单而实用的例子:
在程序调试过程中,我们往往希望程序输出一些中间结果;
一旦程序调试完成,我们又希望将这些中间结果输出语句删除。
利用条件编译指令可以很方便地实现这一要求。
【例9.3】条件编译指令应用示例。
/*09_03.c:条件编译指令示例*/
#include
#include
#define DEBUG
int main()
{
double a,b,c;
double s,area;
scanf("%lf%lf%lf",&a,&b,&c);
#ifdef DEBUG / *条件编译指令* /
printf("DEBUG: a=%f,b=%f,c=%f\n",a,b,c);
#endif
s=(a+b+c)/2;
#ifdef DEBUG
printf("DEBUG:s=%f\n",s);
#endif
area=sqrt(s*(s-a)*(s-b)*(s-c));
printf("Area=%f\n",area);
return 0;
} 运行此程序,
若用户从键盘输入为: 3.0 4.0 5.0<回车>
则输出结果为:
DEBUG: a=3.000000, b=4.000000, c=5.000000
DEBUG: s=6.000000
Area=6.000000
说明
① 上例利用海伦公式计算三角形的面积,根据调试语句输出的中间结果,我们就容易看到程序的运行过程,发现程序中可能存在的错误。
② 当调试完成后,只要删除DEBUG的宏定义指令,条件编译指令中的输出语句也就不再被编译了。最终的程序将只输出三角形的面积值。
2)条件编译指令格式2。
语法:
#ifndef <标识符>
<程序段1>
[#else
<程序段2> ]
#endif
这里,#ifndef <标识符>与前面的#ifdef <标识符> 的判别正好相反,表示<标识符>是否未定义过。
该指令在多文件工程程序中可以用来防止重复包含头文件,具体在9.2节介绍。
9.2 多文件工程程序
本节要点:
• 外部变量与外部函数、静态全局变量与静态函数之间的区别
• 多文件工程程序中模块的合理划分
迄今为止,本书所介绍的程序实例都是单文件工程程序,即将程序代码全部放在一个源文件(扩展名为.c)中。
单文件工程程序(Project with a Single Source File)适用于小型程序的开发。
但是,随着程序功能越来越多,越来越复杂,将所有代码集中到一个源文件中显然不合适。
因此,需要用多个文件共同完成程序。在多文件工程程序(Project with Multiple Source Files)中,程序代码按一定的分类原则被划分为若干个部分,也称为模块(Module),并分别存放在不同的源文件中。
多文件工程程序体现了软件工程的基本思想,其主要优势有以下几点。
(1)程序结构更加清晰。
将不同的数据结构和功能函数模块放在不同的源文件中,便于程序代码的组织管理;
同时,不同的模块可以单独拿出来供其他程序再次使用,提高了软件的可重用性(Reusability)。
(2)便于程序的分工协作开发(CooperativeDevelopment)。
在软件工程中,大型程序的开发不是一个人能单独完成的,而是需要多人合作完成。
多文件工程程序能很方便地将各个模块分配给多人分工协作开发,提高了软件的开发效率。
(3)便于程序的维护(Maintenance)。
当程序修改或升级时,往往需要对其进行重新编译。
单文件工程程序每次重新编译都是对整个程序进行的,费时费力;而多文件工程程序只需要对已修改的源文件进行编译即可,这样就节省了大量时间,提高了软件维护效率。
9.2.1 多文件工程程序的组织结构
多文件工程程序的组织结构(Organization Structure)比较灵活,采用不同的程序设计方法会产生不同的程序结构。
但是,从模块化程序设计的基本规律出发,要使一个多文件工程程序具有良好的组织结构,我们必须遵循以下程序组织原则。
(1)将不同的功能和数据结构划分到不同的模块中。
根据程序设计需求,将代码按功能及其数据结构进行分类,不同类型的程序代码放在不同的源文件(扩展名为.c)中。
(2)将函数的定义和使用相分离。
函数是具有通用性、需要反复使用的程序,在使用之前做函数原型声明即可。将函数的定义从程序其他代码中分离出来,单独存放,有利于函数功能的重用。
(3)将函数的声明和实现相分离。
也就是说,将函数的原型声明放在一个头文件中(扩展名为.h),将函数的具体实现放在另一个与头文件同名的源文件中(扩展名为.c)。这样,当程序需要使用某函数时,只要将该函数的头文件用#include命令包含进来就可以了,非常便捷。
下面我们举例说明。
【例9.4】设计一个多文件工程程序,其功能是计算圆和矩形的面积和周长。
分析:
根据多文件工程程序的组织原则,我们将程序“自顶向下”划分为3个模块(如图9.1所示):
主模块(main.c)是程序的主要入口,负责参数输入、其他模块调用和结果输出等;
圆形模块(circle.c)定义了计算圆形面积和周长的函数,相应的函数声明存放在头文件circle.h中;
矩形模块(rectangle.c)定义了计算矩形面积和周长的函数,相应的函数声明存放在头文件rectangle.h中。所以本程序是一个由5个文件共同构成完整工程的程序,这样的工程组织结构清晰、易于理解,也便于今后对功能进行扩展和维护。

circle.h 文件的内容:
/*circle.h的代码*/
#ifndef CIRCLE / *条件编译,防止重复包含头文件* /
#define CIRCLE
double circle_area(double r);
double circle_perimeter(double r);
#endifcircle.c文件的内容:
/*circle.c的代码*/
#include
double const pi=3.14159;
double circle_area(double r)
{
return pi*r*r;
}
double circle_perimeter(double r)
{
return 2*pi*r;
} rectangle.h文件的内容:
#ifndef RECTANGLE
#define RECTANGLE
double rectangle_area(double w,double h);
double rectangle_perimeter(double w,double h);
#endifrectangle.c文件的内容:
/*rectangle.c的代码*/
#include
double rectangle_area(double w,double h)
{
return w*h;
}
double rectangle_perimeter(double w,double h)
{
return 2*(w+h);
} main.c文件的内容:
/*main.c的代码*/
#include
#include"circle.h"
#include"rectangle.h"
int main()
{
double r,w,h;
printf("Input radius:\n");
scanf("%lf",&r);
printf("Circle area=%f]n",circle_perimeter(r));
printf("Input width and height:\n");
scanf("%lf%lf",&w,&h);
printf("Rectangle area=%f\n",rectangle_area(w,h));
printf("Rectangle perimeter==%f\n",rectangle_perimeter(w,h));
return 0;
} 运行此程序,屏幕上显示:
Input radius:
若用户从键盘输入为:1.0 <回车>
则输出结果及屏幕提示为:
Circle area=3.141590
Circle perimeter=6.283180
Input width and height:
若用户从键盘继续输入为:
2.0 3.0 <回车>
则输出结果为:
Rectangle area=6.000000
Rectangle perimeter=10.000000
说明
① 上例中,main.c中的第2行语句头文件包含指令#include "circle.h"和第3行语句#include "rectangle.h"使用了双引号,自定义的头文件和main.c都存放在当前工作目录中。
② 头文件 circle.h 和 rectangle.h 中都使用了条件编译指令#ifndef … #define …#endif,这保证了头文件中的内容在同一模块中只出现一次,从而防止了函数被重复声明的错误。
注意
编译多文件工程程序时,必须将所有源文件(扩展名为.c)都添加到工程中,才能生成正确的可执行文件。这是因为.h文件中只有函数的原型声明,并没有具体的实现,具体实现是放在对应的同名.c文件中的,所以必须将.c文件一并放入工程。本例中,main函数使用#include"circle.h"做了文件包含,当main函数中调用circle_area函数时,头文件中只有该函数的声明,如果不将circle.c文件放入工程中,将无法找到该函数的定义及实现部分,导致出错。
9.2.2 外部变量与外部函数
在多文件工程程序中,不同文件之间往往需要共享信息。
那么,在一个文件中定义的变量或函数如何能被其他文件所使用呢?
在C语言中,我们可以通过外部变量(ExternalVariable)和外部函数(External Function)声明来实现这一目标,
具体格式如下:
extern <变量名>;
extern <函数声明>;
其中,extern 为关键字;<变量名>所对应的变量必须是另一文件中定义的全局变量(定义在所有函数之外的变量);<函数声明>是另一文件中的函数原型声明。无论是变量还是函数都只能定义一次,但可以在不同文件中使用extern进行外部声明。
【例9.5】外部变量与外部函数示例。
设有一个多文件工程程序,共有3个源文件,其中,源文件A.c中定义了全局变量int x,源文件B.c定义了函数fb(),源文件C.c中定义了函数fc()。现在A.c希望调用函数fb()和fc(),则可以在A.c中添加这两个外部函数声明实现这一功能;另外,函数fb()和fc()都希望访问全局变量x,只要在B.c和C.c中对x进行外部变量声明即可。
A.c 文件的内容:
/*A.c的代码*/
#include
extern void fb(); / *外部函数声明* /
extern voie fc(); / *外部函数声明* /
int x=0; / *全局变量定义* /
int main()
{
printf("x=%d\n",x);
fb();
fc();
x++;
printf("x=%d\n",x);
return 0;
}
B.c 文件的内容:
/*B.c的代码*/
#include
extern int x; / *外部变量声明* /
void fb()
{
x++;
printf("fb() is called,x=%d\n",x);
}
C.c文件的内容
/*C.c的代码*/
#include
extern int x;
void fc()
{
x++;
printf("fc() is called,x=%d\n",x);
} 运行此程序,输出结果为:
x=0
fb() is called, x=1
fc() is called, x=2
x=3
说明
从程序的运行结果可以看到,全局变量x在3个文件3个函数中的变化是连续的,事实上,x在内存中只有一份副本,无论哪一个函数访问它,都是访问的同一个变量,x在A.c文件中定义,要在B.c和C.c文件中访问,必须做外部变量声明。
【例9.5】的思考题:若B.c文件中删除外部变量声明语句“extern int x;”,程序是否还能正确编译?
9.2.3 静态全局变量与静态函数
在多文件工程程序中,有时需要限制所定义的变量或函数只能在本文件中使用,而其他文件却不能访问。使用静态全局变量(Static Global Variable)和静态函数(StaticFunction)声明就能实现这一功能,具体格式如下:
static <全局变量定义>;
static <函数定义>;
其中,static 为关键字;静态全局变量和静态函数必须在其定义时声明,static 不可省略,它们的使用范围仅限于本文件,具有文件作用域。对于例9.5,若在A.c中变量x的定义前加上关键字static,改为static int x=0; 则x就变成了静态全局变量,只能在A.c内被访问,文件B.c和C.c就无法访问了(无论是否进行外部变量声明extern int x;)。此时,程序编译就会出错。同样的,若在B.c和C.c中的函数fb()和fc()定义的前面加上static,则A.c就无法调用它们了,程序编译也不能通过。这个问题,请读者自己修改例9.5上机测试。
9.3 应用举例——多文件结构处理数组问题
本节要点:• 模块化程序设计思想• 数组的输入、输出、统计、查找
本章最后,给出一个综合应用程序,让读者进一步理解多文件工程程序的组织结构。
【例9.6】设计一个多文件工程程序,实现对一维数组的输入、输出、统计、查找等。
分析:
该程序多文件组织结构如图9.2所示,整个工程由7个文件组成。
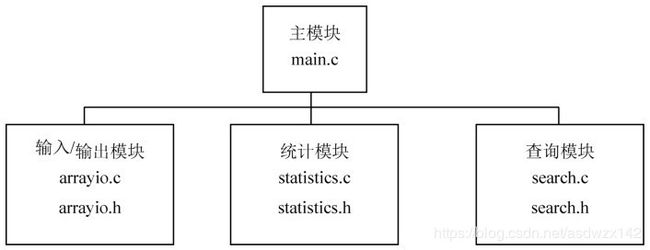
其中,主模块(main.c)主要负责数组定义、用户接口、函数调用等功能;输入/输出模块(arrayio.c)主要负责数据的输入和输出;统计模块(statistic.c)主要负责统计数组的最大值和最小值;查询模块(search.c)主要负责数据的查找。相应的函数原型声明在对应的头文件中。
/*arrayio.h文件的内容*/
#ifndef ARRAYIO / *条件编译防止重复包含头文件* /
#define ARRAYIO
void input(int a[]); / *数据输入函数的原型* /
void output(const int a[]); / *数据输出函数的原型* /
#endif
/ * arrayio.c 文件的内容* /
#include
extern int n; / *外部变量声明* /
/ *函数功能: 输入数组的元素
函数入口参数:数组指针,用来接受实参数组的首地址
函数返回值: 无
* /
void input(int a[])
{
int i;
do{
printf("Please input n(1<=n<=10)\n");
scanf("%d",&n);
}while(n<1||n>10);
printf("Please input %d elements\n",n);
for(i=0;i
extern int n;
/ *函数功能: 从数组中寻找最大的元素
函数入口参数:数组指针,用来接受实参数组的首地址,前面加const防止误修改
函数返回值: int型,找到的最大元素值
* /
int find_max(const int a[])
{
int max,i;
if(n==0){
printf("There is no data in the array\n");
return -1;
}
max=a[0];
for(i=1;imax)
{
max=a[i];
}
}
return max;
}
/ *函数功能: 从数组中寻找最小的元素
函数入口参数:数组指针,用来接受实参数组的首地址,前面加const防止误修改
函数返回值: int型,找到的最小元素值
* /
int find_min(const int a[])
{
int min,i;
if(n==0){
printf("There is no data in the array\n");
return -1;
}
min=a[0];
for(i=1;i
/ * search.h 文件的内容* /
/*search.h文件的内容*/
#ifndef SEARCH
#define SEARCH
int search(const int a[]);
#endif
/ * search.c文件的内容 * /
#include
extern int n;
/ *函数功能: 从数组中寻找指定的元素是否存在及下标
函数入口参数:数组指针,用来接受实参数组的首地址,前面加const防止误修改
函数返回值: int型,找到指定元素的下标值,如果找不到,返回-1
* /
int search(const int a[])
{
int x,j;
if(n==0){
printf("There is no data in the array\n");
return -1;
}
printf("Please input a data to search\n");
scanf("%d",&x);
for(i=0;i /*main.c文件的内容*/
#include
#include "arrayio.h"
#inlcude "statistic.h"
#include "search.h"
int n=0;
static void menu();
int main()
{
int a[10];
int i;
int max,min,index;
do{
menu();
printf("Please input your choice;
scanf("%d",&i);
switch(i){
case 1:
input(a);
break;
case 2:
output(a);
break;
case 3:
max=find_max(a);
printf("Max=%d\n",max);
break;
case 4:
min=find_min(a);
printf("Min=%d\n",min);
break;
case 5:
index=search(a);
printf("Index=%d\n",index);
break;
case 0:
break;
default:
printf("Error input,please input your choice again!\n");
}
}while(i);
return 0;
}
/ *函数功能: 显示菜单 函数入口参数:无
函数返回值: 无
* /
void menu()
{
printf("-------1.输入数据-------\n");
printf("-------2.输出数据-------\n");
printf("-------3.求最大值-------\n");
printf("-------4.求最小值-------\n");
printf("-------5.查找数据-------\n");
printf("-------0.退出程序-------\n");
return;
}
运行该程序,输出结果为:-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 --------------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 1 <回车>Please input n (1<=n<=10)5 <回车>Please input 5 elements12 31 9 26 43 <回车>-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 --------------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 2 <回车>The array is:12 31 9 26 43-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 -------
-------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 3 <回车>max=43-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 --------------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 4 <回车>min=9-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 --------------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 5 <回车>Please input a data to search9 <回车>index=2-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 -------
-------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 5 <回车>Please input a data to search900 <回车>Not find!Index=-1-------- 1. 输入数据 --------------- 2. 输出数据 --------------- 3. 求最大值 --------------- 4. 求最小值 --------------- 5. 查找数据 --------------- 0. 退 出 -------Please input your choice: 0 <回车>
整个程序结束运行。
说明① 上例中,头文件 arrayio.h、search.h 和 statistic.h 中都用到了形如 “#ifndef…#define…#endif”的条件编译命令,以防止重复包含头文件。② 在源文件arrayio.c、search.c和statistic.c中都进行了外部变量声明“extern int n;”,以使用源文件main.c中定义的表示数组当前元素个数的全局变量n。③ 在源文件main.c中通过包含头文件arrayio.h、search.h和statistic.h,以实现对其他模块中定义的各种数组操作函数(如函数input、output、search、find_max、find_min)的使用。④ 在源文件main.c中还声明了一个静态函数“static voidmenu();”,说明menu()函数只能在main.c中被访问,而不能被其他文件模块调用。⑤ 除了input函数,其余各函数中的数组形式参数int a[ ](实质上是int *a)的前面都加了关键字 const 进行限制,使得形参 a 在被调用函数中只能用来访问数组的元素而不能修改数组的元素,这是为了保护对应实参数组的内容。但是 input 函数中的形式参数int a[]之前就一定不能加const,因为该函数的作用就是通过形参a来读入对应实参数组a的元素。
多文件工程程序体现了“自顶向下、逐步分解、分而治之”的模块化程序设计(Modular Programming)思想。对于一个复杂程序的开发,我们通常需要采用模块分解与功能抽象方法,自顶向下,有效地将一个较复杂的程序系统设计任务分解成许多易于控制和处理的子任务,从而便于开发和维护。建议读者在以后的编程实践中,自觉运用多文件工程来组织程序,掌握合理的程序模块划分方法,不断提高程序设计水平。
9.4 本章小结本章主要讲解了C语言中编译预处理与多文件工程的相关知识:需要掌握两种文件包含方式的区别,掌握无参及带参宏的定义及使用,了解条件编译;了解多文件结构工程的构建,了解外部变量与外部函数的使用,了解静态全局变量与静态函数的特点。本章最后给出了一个综合范例——希望读者能够进一步理解多文件工程程序的组织结构,掌握模块化程序设计的基本方法。