Chapter6_Vocoder
文章目录
- 1 Introduction
- 2 WaveNet
- 2.1 WaveNet的架构
- 2.2 Softmax Distribution
- 2.3 Causal Convolution和Dilated Convolution
- 2.4 Gated Activation Unit
- 2.5 小结
- 3 FFTNet
- 4 WaveRNN
- 4.1 Dual Softmax Layer
- 4.2 Model Coarse
- 4.3 Model Fine
- 4.4 小结
- 5 WaveGlow
本文为李弘毅老师【Vocoder】的课程笔记,这次课程由助教同学許博竣讲授,课程视频youtube地址,点这里(需)。
下文中用到的图片均来自于李宏毅老师的PPT,若有侵权,必定删除。
文章索引:
上篇 - 5 Speaker Verification
下篇 - 7-1 Overview of NLP Tasks
总目录
1 Introduction
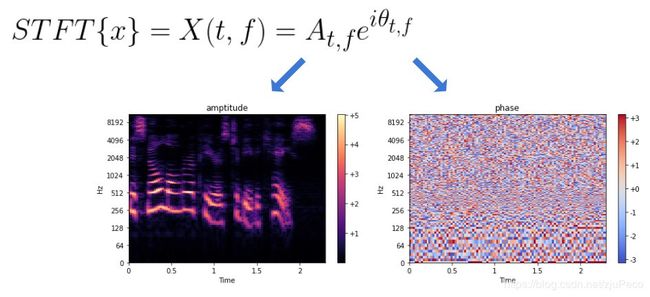
我们在之前的课程中有讲过TTS(Text to Speech)模型和VC(Voice Conversion)模型。这两个模型一般吐出来的都是一个叫做Spectrogram的东西,Spectrogram不是语音,它是一个表示各个时间点各个频率的声音强度的图谱(下图的图谱中,横轴为时间,纵轴为声音频率,颜色深浅表示强度)。因此要转化为最终的语音,还需要一个叫做Vocoder的模型。总而言之,Vocoder就是把Spectrogram转化为语音的模型。

为什么我们必须要有一个Vocoder,而不是让我们的网络直接生成一段语音呢?假设我们有一段语音 x x x,然后这段语音 x x x经过短时傅里叶变换之后,可以得到一个与时间 t t t和频率 f f f相关的复数,这个复数的幅值 A t , f A_{t,f} At,f就是我们刚才聊到的Spectrogram,而 e i θ t , f e^{i\theta _{t,f}} eiθt,f就是相位。TTS或者VC直接生成的结果都是 A t , f A_{t,f} At,f,没有相位。相位不同,产生的音质的差别是很大的,所以相位是必须要有的,这个相位就需要一个叫做Vocoder的模型去生成。
其实要把相位直接放到模型里去end-to-end的train也行,但是这一方面会加大模型的训练难度,另一方面Vocoder是TTS和VC这样的任务都需要的,单独拿出来train的话,既可以两边通用,又可以降低TTS和VC的训练难度。
2 WaveNet
我们的声音信号放大来看,就是一串点的序列,WaveNet借鉴了autogressive model的思想,泛一点来说就是输入前 t − 1 t-1 t−1个点,输出第 t t t个点,然后把新生成的点放到队列当中去,继续生成下一个点。WaveNet最重要的部分就是Causal Convolutions,说简单点就是一堆卷积。

2.1 WaveNet的架构
WaveNet的整体架构如下图所示。Input就是声音信号的前 t − 1 t-1 t−1个点,然后Input会经过一个Causal Conv,经过Causal Conv之后,会经过k层layers,layers就是由dialated conv和 1 × 1 1 \times 1 1×1卷积组成的残差网络,每层都会输出一个特征,利用skip-connection组合起来之后,再经过两个 1 × 1 1 \times 1 1×1卷积和Softmax就得到了最终的结果。
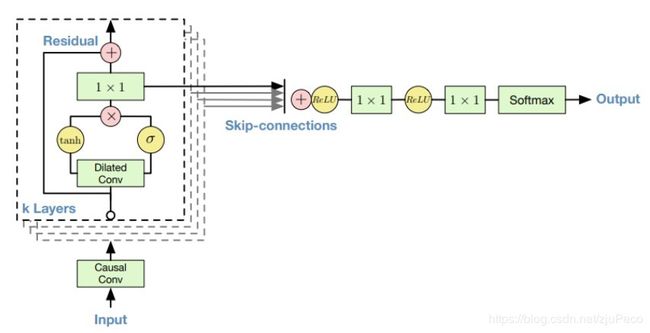
2.2 Softmax Distribution
我们的输入和输出都是one-hot的向量,所以这里要用到softmax。我们的声音信号上每个点的数值是一个16-bit的int,范围在[-32768, 32767],如果直接把这个进行one-hot的话,我们softmax的layer将会有65536个类别,这太难了。所以这里用了一个叫做μ-law的方法,把[-32768, 32767] (16-bit int)的信号转变到了[0, 255] (8-bit int)。这个过程如下所示,先将信号数值转化到[-1, 1],然后用一个叫做μ-law的方法再转换一下,范围仍在[-1, 1],最后再转化到[0, 255]。之所以要用μ-law是因为μ-law可以减小量化误差。
μ-law就是下面这个公式,这里不做过多介绍。
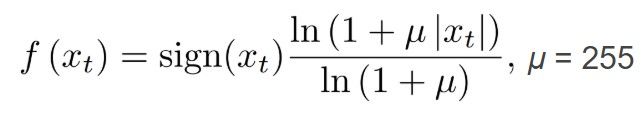
2.3 Causal Convolution和Dilated Convolution
Causal Convolution(因果卷积)就是下图这个东西。它是专门针对时间序列设计的,所以它输出的时候,不会考虑未来的信息,而且隐藏层越多,考虑过去的时间越久远。比如下图是一个kernel size为2的Causal Convolution,最终的output会考虑前5个时间点的信息。

而Dilatied Convolution则是下图所示的这样,它的目的是在卷积中加入空洞来增加感受野。这样一来就不用像标准的CNN那样去pooling了。
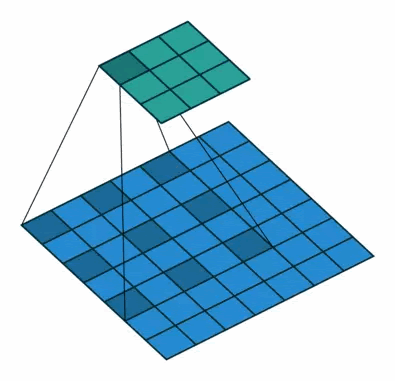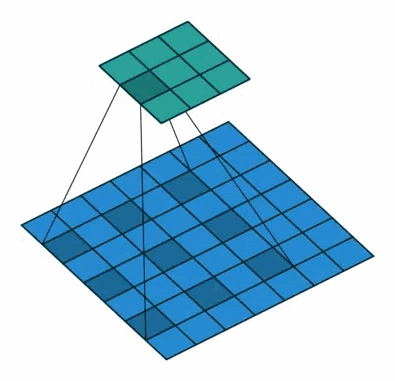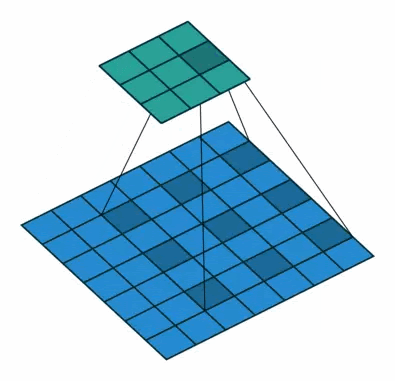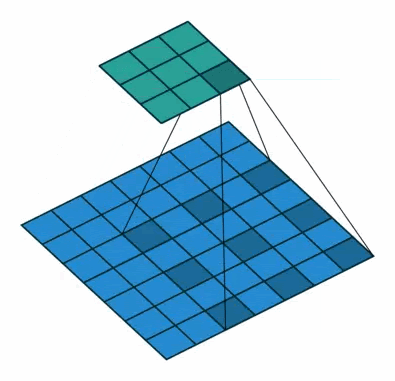
而把这两者结合起来就是Dilated Causal Convolution了。这样一来模型就可以看到更长远的信息了,这在点非常密集的语音里是非常必要的。

2.4 Gated Activation Unit
这里还有一个需要提一下的就是这个Gated Activation Unit,那其实就是经过了两个不同的激活函数,如下图所示。

如果我们要给模型加一些条件的话,就可以加载这个Gated Activation Unit的部分。如果一些全局的特征,比如说话人的一些条件,就像Global Condition那样加,如果是要加Spectrogram这样的随时间变化的条件,就可以像Local condition这样加。
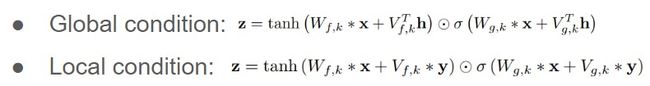
2.5 小结
WaveNet可以直接使用waveform level的特征,利用到了Dilated Causal Convolution去增大感受野,同时也可以接受各种的条件输入,最终出来的结果也是比较不错的。但是,它有一个问题就是速度太慢了,这也可以想象,毕竟autogressive这种方法计算下一个时间点的输出时,是需要利用到之前输出的结果的,因此无法并行计算。所以之后提出的一些网络,基本都是为了解决速度的问题。
3 FFTNet
FFTNet和WaveNet一样都是autogressive model,它简化了WaveNet中的一些繁琐计算,同时提出了一种可以用到所有的autogressive model上的训练和合成技巧。
FFTNet的模型架构如下图所示,它会把输入 x x x分为 x L x_L xL和 x R x_R xR两个部分,然后分别经过一个卷积之后,加起来,再过一层卷积,使得总长度减半,这样运行两层,得到最终结果。这样得到的特征,也是考虑了一定范围的语音特征的,比如下图中输出的绿色部分就是考虑了 x L x_L xL生成的。

FFTNet提出了四个技巧:
- 在开头做zero-padding可以让训练结果更好
- 最后取结果是,不是直接去最大概率的那个值,而是根据概率分布去做sample
- 在训练时,给输入加上一些噪声
- 加入去噪声的后处理
FFTNet最终可以达到和WaveNet差不多的效果,但速度却快上很多。
4 WaveRNN
WaveRNN是Google提出来的,说简单点就是用RNN去代替之前的CNN。
4.1 Dual Softmax Layer
WaveRNN没有用之前把16bit转成8bit的方法,而是把16bit转成了两个8bit,然后做两次softmax的操作。
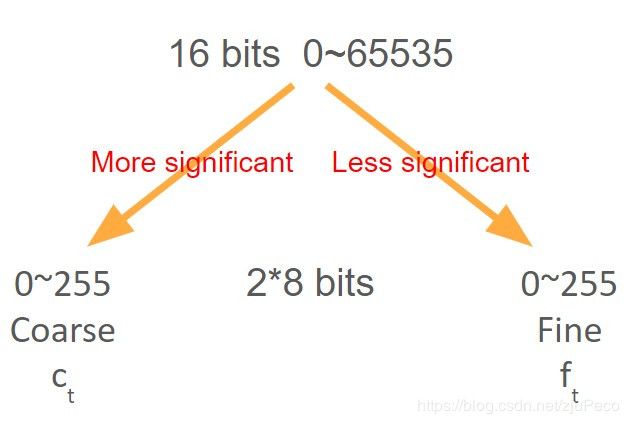
4.2 Model Coarse
产生 c t c_t ct的部分如下图所示,中间这块我们可以把它看成一个GRU,它吃 c t − 1 c_{t-1} ct−1和 f t − 1 f_{t-1} ft−1,以及上一个time step的hiddent state,输出 c t c_t ct。
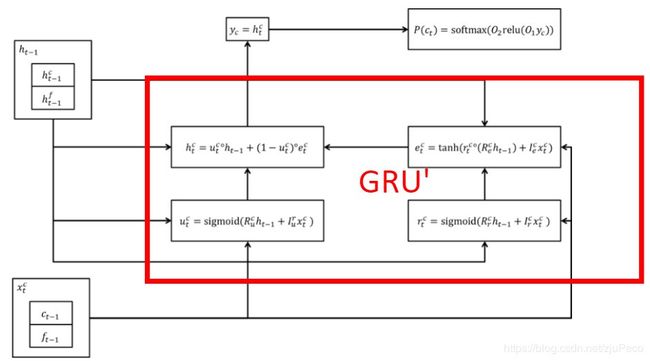
4.3 Model Fine
产生 f t f_t ft的部分如下图所示,中间这块我们可以把它看成一个GRU,它吃 c t − 1 c_{t-1} ct−1和 f t − 1 f_{t-1} ft−1,以及上一个time step的hiddent state,除此之外,还有刚才产生的 c + t c+t c+t,输出 f t f_t ft。

4.4 小结
WaveRNN还有一些加速的技巧,最终可以达到在手机cpu上real time的效果,非常强~
5 WaveGlow
WaveGlow放弃了autogressive的方法,基于flow-based model去做的,这个模型非常难train,有兴趣的同学可以看一下视频或者相关资料学习,这里不做介绍了。