spark源码阅读笔记Dataset(一)初识Dataset
1、Dataset 是什么
本质上,Dataset在源码中是一个类(和RDD不同,Dataset为非抽象类),其中有三个参数
class Dataset[T] private[sql](
@transient val sparkSession: SparkSession,
@DeveloperApi @transient val queryExecution: QueryExecution,
encoder: Encoder[T])
extends Serializable {/**/}
SparkSession:The entry point to programming Spark with the Dataset and DataFrame API.(包含环境等信息)
QueryExecution:The primary workflow for executing relational queries using Spark. Designed to allow easy access to the intermediate phases of query execution for developers(包含数据和执行逻辑信息)
Encoder[T]:数据结构编码信息(包含序列化、schema,数据type)
Dataset的作用就是:一推数据丢进来到调用這个类的时候,大致会经历如下步骤中的后两步
原始数据-->数据清洗-->格式转换-->逻辑运算
2、如何创建dataSet
下面从序列(Seq)转换成dataset,来看看经历了什么,执行如下函数
def start()={
val sparkSession = SparkSession.builder().appName("data set example")
.master("local").getOrCreate()
import sparkSession.implicits._
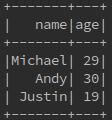
val data= Seq(Person("Michael", 29), Person("Andy", 30), Person("Justin", 19))
val showData = sparkSession.createDataset(data)
showData.show()
}
查看一下createDataset的源码如下:
def createDataset[T : Encoder](data: Seq[T]): Dataset[T] = {
/**
* 对于输入的的信息,两个需要主要(此刻T = person)
* 1、编码信息为T
* 2、输入的数据类型为Seq[T]
*/
val enc = encoderFor[T]
/**
* 此处通过对类型T进行提取
*/
val attributes = enc.schema.toAttributes
val encoded: Seq[InternalRow] = data.map(d => enc.toRow(d).copy())
/**
* case class LocalRelation(output: Seq[Attribute], data: Seq[InternalRow] = Nil)
* play包含了属性attributes和内部数据encoded
*/
val plan = new LocalRelation(attributes, encoded)
Dataset[T](self, plan)
/**
* Dataset[T](self, plan) =>
* 最终调用:Dataset(sparkSession, sparkSession.sessionState.executePlan(logicalPlan), encoder)
* 其中:执行逻辑是 play部分,encoder就是play的encoded
*/
}1、类型T,
2、输入的数据为Seq[T]
那么此刻的T为Person
通过
val enc = encoderFor[T]
val attributes = enc.schema.toAttributes
@param name The name of this field.
* @param dataType The data type of this field.
* @param nullable Indicates if values of this field can be `null` values.
* @param metadata The metadata of this field. The metadata should be preserved during
* transformation if the content of the column is not modified, e.g, in selection.
来得到属性信息----->case Person(name:String,age:Int)的属性的
val encoded: Seq[InternalRow] = data.map(d => enc.toRow(d).copy())nullable: Boolean = true,
metadata: Metadata = Metadata.empty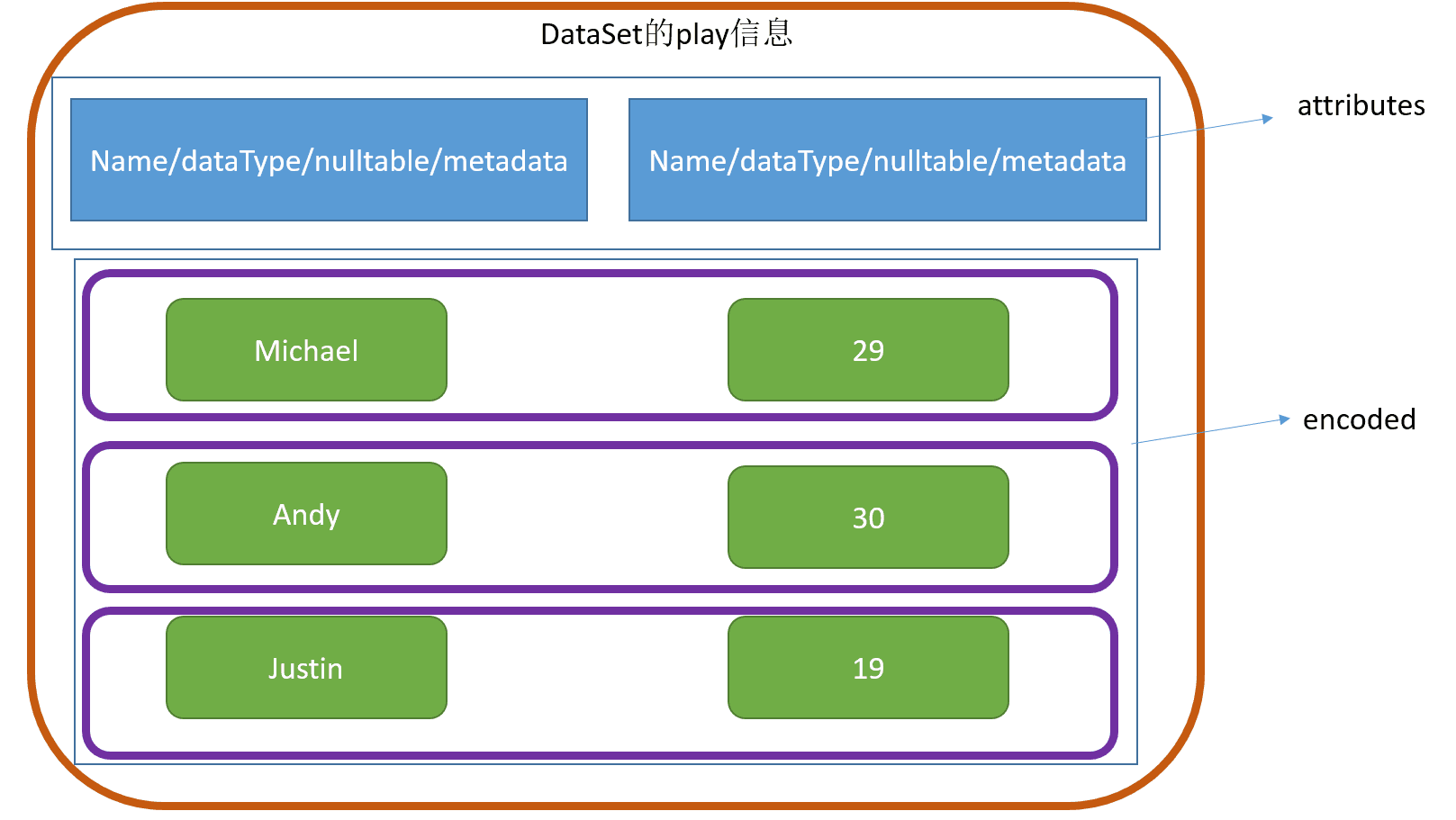
3、 隐式转换为dataSet
在(原始数据-->数据清洗-->格式转换-->逻辑运算 )步骤中的(数据清洗-->格式转换 )这一步,spark提供了隐式转换
可以直接把Seq等這些数据类型转换为dataSet,但需要导入一个隐式转换这一步骤,如下:
val sparkSession = SparkSession.builder().appName("data set example")
.master("local").getOrCreate()
import sparkSession.implicits._
这样其他类型就可以直接转换为dataSet(同时解决序列化编码问题)
它调用的方法如下:
object implicits extends SQLImplicits with Serializable {
protected override def _sqlContext: SQLContext = SparkSession.this.sqlContext
}
它继承了SQLimplicits,在来看SQLimplicits這个类如下:
abstract class SQLImplicits {
protected def _sqlContext: SQLContext
/**
* Converts $"col name" into a [[Column]].
*
* @since 2.0.0
*/
implicit class StringToColumn(val sc: StringContext) {
def $(args: Any*): ColumnName = {
new ColumnName(sc.s(args: _*))
}
}
/** @since 1.6.0 */
implicit def newProductEncoder[T <: Product : TypeTag]: Encoder[T] = Encoders.product[T]
// Primitives
/** @since 1.6.0 */
implicit def newIntEncoder: Encoder[Int] = Encoders.scalaInt
/** @since 1.6.0 */
implicit def newLongEncoder: Encoder[Long] = Encoders.scalaLong
/** @since 1.6.0 */
implicit def newDoubleEncoder: Encoder[Double] = Encoders.scalaDouble
/** @since 1.6.0 */
implicit def newFloatEncoder: Encoder[Float] = Encoders.scalaFloat
/** @since 1.6.0 */
implicit def newByteEncoder: Encoder[Byte] = Encoders.scalaByte
/** @since 1.6.0 */
implicit def newShortEncoder: Encoder[Short] = Encoders.scalaShort
/** @since 1.6.0 */
implicit def newBooleanEncoder: Encoder[Boolean] = Encoders.scalaBoolean
/** @since 1.6.0 */
implicit def newStringEncoder: Encoder[String] = Encoders.STRING
// Boxed primitives
/** @since 2.0.0 */
implicit def newBoxedIntEncoder: Encoder[java.lang.Integer] = Encoders.INT
/** @since 2.0.0 */
implicit def newBoxedLongEncoder: Encoder[java.lang.Long] = Encoders.LONG
/** @since 2.0.0 */
implicit def newBoxedDoubleEncoder: Encoder[java.lang.Double] = Encoders.DOUBLE
/** @since 2.0.0 */
implicit def newBoxedFloatEncoder: Encoder[java.lang.Float] = Encoders.FLOAT
/** @since 2.0.0 */
implicit def newBoxedByteEncoder: Encoder[java.lang.Byte] = Encoders.BYTE
/** @since 2.0.0 */
implicit def newBoxedShortEncoder: Encoder[java.lang.Short] = Encoders.SHORT
/** @since 2.0.0 */
implicit def newBoxedBooleanEncoder: Encoder[java.lang.Boolean] = Encoders.BOOLEAN
// Seqs
/** @since 1.6.1 */
implicit def newIntSeqEncoder: Encoder[Seq[Int]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newLongSeqEncoder: Encoder[Seq[Long]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newDoubleSeqEncoder: Encoder[Seq[Double]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newFloatSeqEncoder: Encoder[Seq[Float]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newByteSeqEncoder: Encoder[Seq[Byte]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newShortSeqEncoder: Encoder[Seq[Short]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newBooleanSeqEncoder: Encoder[Seq[Boolean]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newStringSeqEncoder: Encoder[Seq[String]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newProductSeqEncoder[A <: Product : TypeTag]: Encoder[Seq[A]] = ExpressionEncoder()
// Arrays
/** @since 1.6.1 */
implicit def newIntArrayEncoder: Encoder[Array[Int]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newLongArrayEncoder: Encoder[Array[Long]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newDoubleArrayEncoder: Encoder[Array[Double]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newFloatArrayEncoder: Encoder[Array[Float]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newByteArrayEncoder: Encoder[Array[Byte]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newShortArrayEncoder: Encoder[Array[Short]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newBooleanArrayEncoder: Encoder[Array[Boolean]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newStringArrayEncoder: Encoder[Array[String]] = ExpressionEncoder()
/** @since 1.6.1 */
implicit def newProductArrayEncoder[A <: Product : TypeTag]: Encoder[Array[A]] =
ExpressionEncoder()
/**
* Creates a [[Dataset]] from an RDD.
*
* @since 1.6.0
*/
implicit def rddToDatasetHolder[T : Encoder](rdd: RDD[T]): DatasetHolder[T] = {
DatasetHolder(_sqlContext.createDataset(rdd))
}
/**
* Creates a [[Dataset]] from a local Seq.
* @since 1.6.0
*/
implicit def localSeqToDatasetHolder[T : Encoder](s: Seq[T]): DatasetHolder[T] = {
DatasetHolder(_sqlContext.createDataset(s))
}
/**
* An implicit conversion that turns a Scala `Symbol` into a [[Column]].
* @since 1.3.0
*/
implicit def symbolToColumn(s: Symbol): ColumnName = new ColumnName(s.name)
}前面的case class Person(name: String, age: Long),就是用了newProductEncoder进行了隐式转换
import org.apache.spark.sql.{Dataset, SparkSession}
object dataSet1 {
case class Person(name: String, age: Long)
val sparkSession = SparkSession.builder().appName("data set example")
.master("local").getOrCreate()
import sparkSession.implicits._
def textToDataset()={
val data: Dataset[String] = sparkSession.read.text("hdfs://master:9000/src/main/resources/people.txt").as[String]
data.show()
/**
*
+-----------+
| value|
+-----------+
|Michael, 29|
| Andy, 30|
| Justin, 19|
+-----------+
*/
}
def seqToDataset1()={
val data: Dataset[Person] = sparkSession.read.json("hdfs://master:9000/src/main/resources/people.json").as[Person]
data.show()
/**
*
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
*/
}
def seqToDataset2()={
val data= Seq(Person("Michael", 29), Person("Andy", 30), Person("Justin", 19))
val showData = sparkSession.createDataset(data)//data.toDS
showData.show()
/**
*
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
*/
}
def rddToDataSet()={
val rdd = sparkSession.sparkContext.textFile("hdfs://master:9000/src/main/resources/people.txt")
val rddToDataSet = rdd.map(_.split(",")).map(p =>Person(p(0),p(1).trim.toLong)).toDS()
rddToDataSet.show()
/**
*
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
*/
}
def main(args: Array[String]) {
}
}