吴恩达机器学习SVM


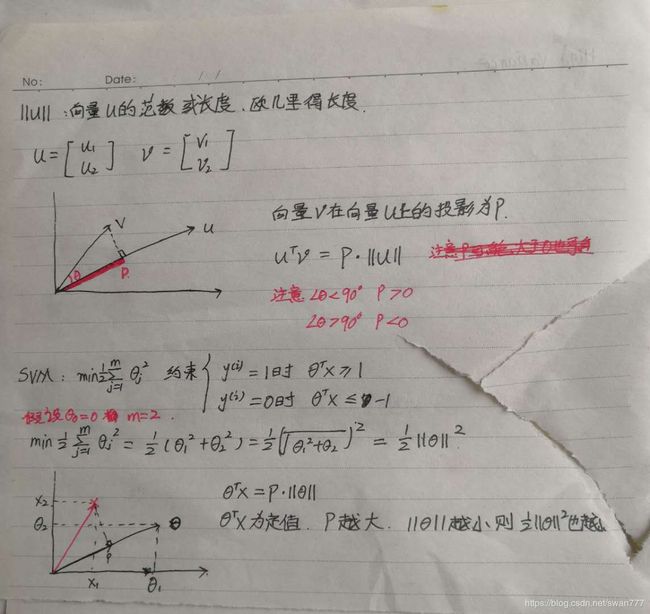
核函数
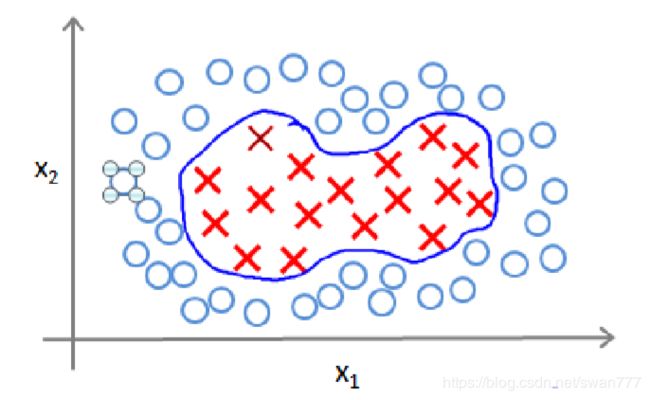
为了获得上图所示的判定边界,我们的模型可能是
![]()
我们可以用一系列的新的特征 f 来替换模型中的每一项。例如令
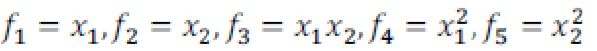
得到 hθ(x)=f1+f2+...+fn。然而,除了对原有的特征进行组合以外,有没有更好的方法来
构造 f1,f2,f3?我们可以利用核函数来计算出新的特征。
高斯核函数
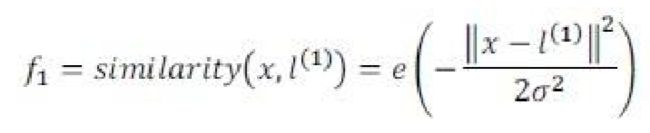
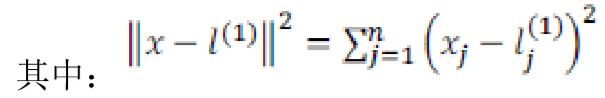 为实例 x 中所有特征与地标 l(1)之间的距离的和。
为实例 x 中所有特征与地标 l(1)之间的距离的和。
我们通常是根据训练集的数量选择地标的数量,即如果训练集中有 m 个实例,则我们选取 m 个地标,并且令:
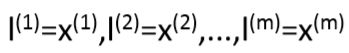
如果一个训练实例 x 与地标 L 之间的距离近似于 0,则新特征 f 近似于 =1,如果训练实例 x 与地标 L 之间距离较远,则 f 近似于
=1,如果训练实例 x 与地标 L 之间距离较远,则 f 近似于![]() =0。
=0。
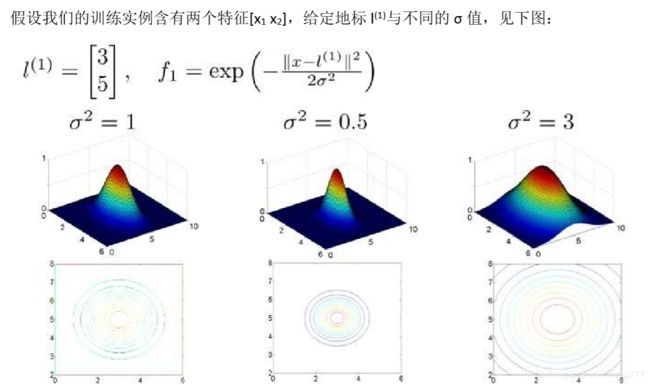
图中水平面的坐标为 x1,x2而垂直坐标轴代表 f。可以看出,只有当 x 与 l(1)重合时 f 才具有最大值。随着 x 的改变 f 值改变的速率受到 σ2的控制。
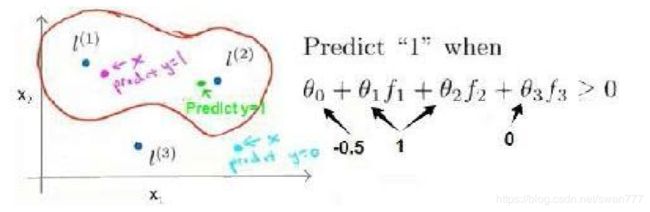
当实例处于洋红色的点位置处,因为其离 l(1)更近,但是离 l(2)和 l(3)较远,因此 f1接近 1,而 f2,f3 接近 0。
因此 hθ(x)=θ0+θ1f1+θ2f2+θ1f3=-0.5+1*1+1*0+0*0 >0,因此预测 y=1。
同理可以求出,对于离 l(2)较近的绿色点, hθ(x)=θ0+θ1f1+θ2f2+θ1f3=-0.5+1*0+1*1+0*0>0也预测 y=1,
但是对于蓝绿色的点,因为其离三个地标都较远,hθ(x)=θ0+θ1f1+θ2f2+θ1f3=-0.5+1*0+1*0+0*0<0,预测 y=0。
这样,图中红色的封闭曲线所表示的范围,便是我们依据一个单一的训练实例和我们选取的地标所得出的判定边界,在预测时,我们采用的特征不是训练实例本身的特征,而是通 过核函数计算出的新特征 f1,f2,f3。
下面我们将核函数运用到支持向量机中,修改我们的支持向量机假设为:
• 给定 x,计算新特征 f,当 θTf>=0 时,预测 y=1,否则反之。 相应地修改代价函数为:
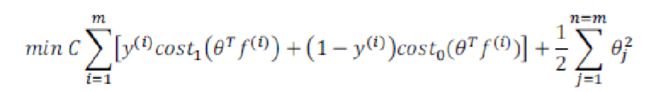
在具体实施过程中,我们还需要对最后的正则化项进行些微调整,在计算时,我们用 θTMθ 代替 θTθ,其中 M 是根据我们选择的核函数而不同的一个矩阵。这样做的原因是为了简化计算。

尽管你不去写你自己的 SVM(支持向量机)的优化软件,但是你也需要做几件事:
1、是提出参数 C 的选择。我们在之前的视频中讨论过误差/方差在这方面的性质。
2、你也需要选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说他使用了线性核的 SVM(支持向量机),这就意味这他使用了不带有核函数的 SVM(支持向量机)。
从逻辑回归模型,我们得到了支持向量机模型,在两者之间,我们应该如何选择呢?
下面是一些普遍使用的准则:
n 为特征数,m 为训练样本数。
(1)如果相较于 m 而言,n 要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果 n 较小,而且 m 大小中等,例如 n 在 1-1000 之间,而 m 在 10-10000 之间,
使用高斯核函数的支持向量机。
(3)如果 n 较小,而 m 较大,例如 n 在 1-1000 之间,而 m 大于 50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。