pytorch—CNN卷积神经网络实现mnist手写体识别
- 接上篇文章的线性模型是一个实验,这次使用pytorch实现神经网络LENET5手写识别MNIST
- 卷积层块里的基本单位是卷积层后接平均池化层:卷积层用来识别图像里的空间模式,如线条和物体局部,之后的平均池化层则用来降低卷积层对位置的敏感性。
科普一下LENET5:
手写字体识别模型LeNet5诞生于1994年,是最早的卷积神经网络之一。
LeNet5通过巧妙的设计,利用卷积、参数共享、池化等操作提取特征,避免了大量的计算成本,
最后再使用全连接神经网络进行分类识别,这个网络也是最近大量神经网络架构的起点。
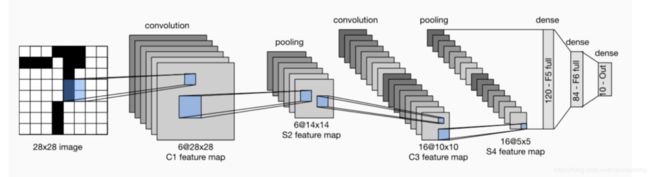
- 每层的参数个数的计算 原理 在备注中
- 每层输出的features map的shape 如何得出
- 代码中包含模型的调试信息
- 代码以兼容运行在GPU或者CPU上
- 都在备注中有体现,详细看代码
- MNIST的数据集 没有上传,可以去Google查找,或者给我留言我邮件给你均可
- 代码可以直接跑起来,不能运行的代码都是耍流氓
- 话不多说 直接上代码:
#引入使用库
import torch
import torch.nn as nn
import torch.optim as optim
import time
import torchvision
import torchvision.transforms as transforms
from torchviz import make_dot
import matplotlib.pyplot as plt
net
#战平 操作
class Flatten(torch.nn.Module):
def forward(self,x):
return x.view(x.shape[0],-1)
#将图像 大小 重新定制
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1,1,28,28)
#创建 堆栈模型
net = torch.nn.Sequential(
Reshape(),# 将图像裁剪大小
# 2维卷积 输入1维 输出6维 kernel_size = 5 padding =2 strid = 1 参数个数 num_nerual * input_channel kernel_size 65*5
# 输出 features Map (input size + 2 padding -kernelsize)/ stride +1
nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2),
# 激活函数
#nn.Sigmoid(),
#nn.ReLU(),
nn.Tanh(),
# 池化操作 降低卷积层对位置的敏感程度
# (28 - 2)/2 +1 输出feature map 14 14
nn.AvgPool2d(kernel_size=2,stride=2),
nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5),
#nn.Sigmoid(),
#nn.ReLU(),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2,stride=2),
Flatten(),
nn.Linear(in_features=1655,out_features=120),
#nn.Sigmoid(),
#nn.ReLU(),
nn.Tanh(),
nn.Linear(120,84),
nn.Sigmoid(),
nn.Linear(84,10)
)
读取数据
batch_size = 256
num_workers = 4
#train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size = batch_size,root = “./datasets/input/FashionMNIST2065”)
mnist_train = torchvision.datasets.FashionMNIST(root=’./dataset/input/FashionMNIST2065’, train=True, download=False, transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root=’./dataset/input/FashionMNIST2065’, train=False, download=False, transform=transforms.ToTensor())
train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
#检测可以运行设备
def try_gpu():
if torch.cuda.is_available():
device = torch.device(“cuda0”)
else:
device = torch.device(“cpu”)
return device
#计算准确率
def evaluate_accuracy(data_iter,net,device = torch.device(“cpu”)):
acc_sum ,n = torch.tensor([0],dtype=torch.float32,device=device),0
for X,y in data_iter:
X,y = X.to(device),y.to(device)
net.eval()
with torch.no_grad():
y = y.long()
acc_sum += torch.sum((torch.argmax(net(X),dim=1) == y))
n += y.shape[0]
return acc_sum.item() / n
def train_ch5(net,train_iter,test_iter,criterion,num_epochs,batch_size,device,lr = None):
print("train on ",device)
net.to(device)
optimizer = optim.SGD(net.parameters(),lr= lr)
for epoch in range(num_epochs):
train_l_sum = torch.tensor([0.0],dtype=torch.float32,device = device)
train_acc_sum = torch.tensor([0.0],dtype=torch.float32,device = device)
n,start = 0,time.time()
for X,y in train_iter:
optimizer.zero_grad()
X,y = X.to(device),y.to(device)
y_hat = net(X)
loss = criterion(y_hat,y)
loss.backward()
optimizer.step()
with torch.no_grad():
y = y.long()
train_l_sum += loss.float()
train_acc_sum+= (torch.sum((torch.argmax(y_hat,dim=1)== y))).float()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter,net,device)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, '
'time %.1f sec'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc,
time.time() - start))
lr,num_epochs = 0.1,10
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
torch.nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
criterion = nn.CrossEntropyLoss() #交叉熵 描述了两个概率分布之间的距离,交叉熵越小说明两者越接近
train_ch5(net,train_iter,test_iter,criterion,num_epochs,batch_size,device,lr)
for testdata,test_label in test_iter:
testdata,test_label = testdata.to(device),test_label.to(device)
break
print(testdata.shape,test_label.shape)
net.eval()
y_pre = net(testdata)
print(torch.argmax(y_pre,dim=1)[:10])
print(test_label[:10])
print(“well done”)
- 项目中没有精细的调整
- 只调整了激活函数对准确率的影响
- 调整了lr对准确率的影响