实时查询引擎 - Apache Drill 介绍与应用
1. Drill是什么
Apache drill是什么,脱去华丽的外衣,Apache Drill是一个能够对大数据进行实时的分布式查询引擎,目前它已经成为Apache的顶级项目。Drill是开源版本的Google Dremel。它以兼容ANSI SQL语法作为接口,支持对本地文件,HDFS,HIVE, HBASE,MongeDB作为存储的数据查询,文件格式支持Parquet,CSV, TSV,以及JSON这种无模式无关(schema-free)的数据。所有这些数据都可以像使用传统数据库的针对表查询一样进行快速实时的查询。
2. Drill结构
Apache Drill是一个无主节点的分布式查询工具,每一个部署节点(Drillbit)都包含有以下核心模块:
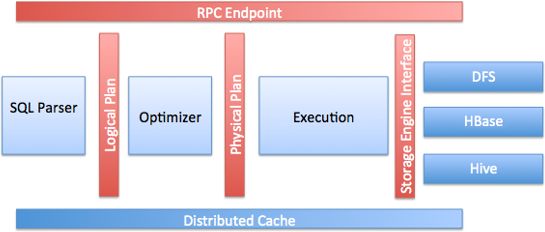
- RPC Endpoint: 基于RPC协议的客户端通信接口
- SQL Parser: SQL解析工具,输出Logical plan, 它使用了开源工具:Calcite
- Storage Engine interface: 面对多种数据源的统一读写抽象接口,它提供几种功能: 1.提供Metadata。 2.数据读写接口。3.数据定位和优化规则帮助提高查询效率。
Drill提供以下几种类型的使用接口:
- Drill Shell
- Drill WEB控制台
- ODBC/JDBC
- C++ API
3. Drill安装
Drill支持单机或分布式模块的Linux, Mac OS X, Windows系统的部署。本文的测试环境为基于CDH 5.5的Hadoop集群环境的安装和测试。ApacheDrill 版本: 1.8. Drill 的安装依赖于以下几个组件:
- (必须)JDK 7
- (必须)ZooKeeper quorum
- (建议)Hadoop Cluster
- (建议)使用DNS
即然是基于已安装好的CDH 5.5环境,那么以上要求自然是完全满足的。(CDH5.5安装参考: 理清CDH Hadoop集群安装流程,剩下的就是安装Drill了:
1. 解压Apache Drill(软件包的下载可以在Apache drill官网下到)
tar -xzvf apache-drill-1.8.0.tar.gz 2. 更改配置文件
更改目录 apache-drill-1.8.0/conf/drill-override.conf配置文件,如:
drill.exec: {
cluster-id: "drillbits1", //集群唯一ID,可以默认
zk.connect: "master:2181,slave2:2181,slave3:2181" //参考hdfs-site.xml的ha.zookeeper.quorum配置项值
} 3. 配置Drill
Drill默认使用4G Heap memory, 8G Direct Memory的配置,(自Drill 1.5后,Drill使用Driect Memory来分配查询内存,提高查询效率)。可以在apache-drill-1.8.0/conf/drill-env.sh文件中更改内存配置,如:
DRILL_MAX_DIRECT_MEMORY="8G"
DRILL_MAX_HEAP="4G" 4. 启动Drill
将配置完成后的 apache-drill-1.8.0 目录拷贝到每一个集群节点上,执行bin目录下的以下脚本启动Apache Drill:
./drillbits.sh start 5. 连接到Drill
Drill可以使用以下几方式进行命令行连接操作:
##使用drill-override.conf配置文件进行默认连接
./bin/drill-conf #以下的查询测试都采用此方式进行连接
##使用命令行自己指定参数进行连接
./bin/sqlline -u jdbc:drill:schema=hive;zk=master:2181,slave2:2181,slave3:2181或访问如下URL进行WEB界面访问和操作,包括进行Storage plugin的配置等,也都要通过该界面:
http://:8047/ #注意更改主机名 ,可以访问任意一台运行有Drill的节点4. 使用Drill查询文件
1. 配置Drill 的HDFS Storage
在上面的WEB页面中的Storage Tab页中,更新hdfs storage,如:
{
"type" : "file",
"enabled" : true,
"connection" : "hdfs://master:8020/", ##配置该项为集群HDFS地址
"workspaces" : {
"root" : {
"location" : "/user/root/drill",
"writable" : true,
"defaultInputFormat" : null
}
},
"formats" : {
"json" : {
"type" : "json"
}
}
} 然后Update并Enable.
2. 直接查询HDFS中的JSON文件
JSON是一个无模式化,结构随意的文件,使用Drill不仅可以像表一个查询JSON,而且可以分析JSON深层的数据,如:
0: jdbc:drill:> select employee_id,full_name,first_name,last_name from `hdfs`.`/tmp/drill/employee.json` limit 5;
+--------------+------------------+-------------+------------+
| employee_id | full_name | first_name | last_name |
+--------------+------------------+-------------+------------+
| 1 | Sheri Nowmer | Sheri | Nowmer |
| 2 | Derrick Whelply | Derrick | Whelply |
| 4 | Michael Spence | Michael | Spence |
| 5 | Maya Gutierrez | Maya | Gutierrez |
| 6 | Roberta Damstra | Roberta | Damstra |
+--------------+------------------+-------------+------------+
5 rows selected (0.312 seconds)
# 如果JSON具有多层结构,还可以使用点分隔来引用深层数据 3. 直接查询HDFS中的CSV文件
跟查询JSON文件一样:
0: jdbc:drill:> select * from `hdfs`.`/tmp/drill/customer_data.csv` limit 5;
+---------+
| columns |
+---------+
| ["1","Customer#000000001","IVhzIApeRb ot.c.E","15","25-989-741-2988","711.56","BUILDING","to the even. regular platelets. regular. ironic epitaphs nag e"] |
| ["2","Customer#000000002","XSTf4.NCwDVaWNe6tEgvwfmRchLXak","13","23-768-687-3665","121.65","AUTOMOBILE","l accounts. blithely ironic theodolites integrate boldly: caref"] |
| ["3","Customer#000000003","MG9kdTD2WBHm","1","11-719-748-3364","7498.12","AUTOMOBILE"," deposits eat slyly ironic. even instructions. express foxes detect slyly. blithely even accounts abov"] |
| ["4","Customer#000000004","XxVSJsLAGtn","4","14-128-190-5944","2866.83","MACHINERY"," requests. final. regular ideas sleep final accou"] |
| ["5","Customer#000000005","KvpyuHCplrB84WgAiGV6sYpZq7Tj","3","13-750-942-6364","794.47","HOUSEHOLD","n accounts will have to unwind. foxes cajole accor"] |
+---------+
5 rows selected (0.527 seconds)这儿看到的列头只有一个columns,因为CSV文件中不包含列头,但我们可以通过columns[n]来进行拆分,如:
0: jdbc:drill:> select columns[0] as id, columns[1] as name, columns[3] as age
. . . . . . . > from `hdfs`.`/tmp/drill/customer_data.csv` limit 5;
+-----+---------------------+------+
| id | name | age |
+-----+---------------------+------+
| 1 | Customer#000000001 | 15 |
| 2 | Customer#000000002 | 13 |
| 3 | Customer#000000003 | 1 |
| 4 | Customer#000000004 | 4 |
| 5 | Customer#000000005 | 3 |
+-----+---------------------+------+
5 rows selected (0.316 seconds) 4. 直接查询HDFS中的Parquet文件
Parquet是一种自描述的数据源,本身已包含了对数据结构的描述,且压缩率高,按列存储,使用广泛:
0: jdbc:drill:> select * from `hdfs`.`/tmp/drill/nation.parquet` limit 5;
+--------------+------------+--------------+-----------------------+
| N_NATIONKEY | N_NAME | N_REGIONKEY | N_COMMENT |
+--------------+------------+--------------+-----------------------+
| 0 | ALGERIA | 0 | haggle. carefully f |
| 1 | ARGENTINA | 1 | al foxes promise sly |
| 2 | BRAZIL | 1 | y alongside of the p |
| 3 | CANADA | 1 | eas hang ironic, sil |
| 4 | EGYPT | 4 | y above the carefull |
+--------------+------------+--------------+-----------------------+
5 rows selected (0.258 seconds)- Parquet中含有Decimal数据类型时会产生异常:
Error: SYSTEM ERROR: IndexOutOfBoundsException: index: 256, length: 1 (expected: range(0, 256))
对于Parquet中的Timestamp, VARCHAR数据类型在查询时需要使用CONVERT_FROM函数进行一次转换,如:
0: jdbc:drill:> select time, varvalue
. . . . . . . > from hdfs.`/tmp/drill/test_data.0.parq` limit 3;
+--------------+--------------+
| time | varvalue |
+--------------+--------------+
| [B@51a22039 | [B@6af1a80d |
| [B@1f502455 | [B@46815882 |
| [B@55d9e2f7 | [B@53c3f229 |
+--------------+--------------+
3 rows selected (0.272 seconds)
###转换这后
0: jdbc:drill:> select CONVERT_FROM(time, 'TIMESTAMP_IMPALA') AS time,CONVERT_FROM(varvalue, 'UTF8') as varvalue
. . . . . . . > from hdfs.`/tmp/drill/test_data.0.parq` limit 3;
+------------------------+------------+
| time | varvalue |
+------------------------+------------+
| 2016-04-26 07:55:00.0 | 0769 |
| 2016-04-26 07:55:00.0 | 0769 |
| 2016-04-26 07:55:00.0 | 0769 |
+------------------------+------------+
3 rows selected (0.273 seconds)5. 使用Drill查询HIVE表数据
1. 配置Drill的HIVE Storage
还是一样的配置页面,还是一样的配置方式,还是一样的需要Update并Enable:
{
"type": "hive",
"enabled": true,
"configProps": {
"hive.metastore.uris": "thrift://master:9083",
"javax.jdo.option.ConnectionURL": "jdbc:derby:;databaseName=../sample-data/drill_hive_db;create=true",
"hive.metastore.warehouse.dir": "/user/hive/warehouse",
"fs.default.name": "hdfs://master:8020",
"hive.metastore.sasl.enabled": "false"
}
}2. 查询HIVE表数据
0: jdbc:drill:> select regionid, regiontype,provinceid from hive.testdb.region limit 5;
+-----------+-------------+-------------+
| regionid | regiontype | provinceid |
+-----------+-------------+-------------+
| 020 | 2 | 103 |
| 0660 | 2 | 103 |
| 0662 | 2 | 103 |
| 0663 | 2 | 103 |
| 0668 | 2 | 103 |
+-----------+-------------+-------------+
5 rows selected (0.262 seconds)
#region表也是Parquet格式表查询HIVE的Parquet表时,可以设置参数: store.hive.optimize_scan_with_native_readers来优化Drill的Parquet读取性能,如:
0: jdbc:drill:> set store.hive.optimize_scan_with_native_readers=true;
+-------+--------------------------------------------------------+
| ok | summary |
+-------+--------------------------------------------------------+
| true | store.hive.optimize_scan_with_native_readers updated. |
+-------+--------------------------------------------------------+
1 row selected (0.228 seconds)
0: jdbc:drill:> select regionid,provinceid from hive.testdb.region limit 5;
+-----------+-------------+
| regionid | provinceid |
+-----------+-------------+
| 020 | 103 |
| 0660 | 103 |
| 0662 | 103 |
| 0663 | 103 |
| 0668 | 103 |
+-----------+-------------+
5 rows selected (0.221 seconds)- 在设置了该参数为true后在读取Decimal参数时会产生异常:
Error: SYSTEM ERROR: IndexOutOfBoundsException: index: 256, length: 1 (expected: range(0, 256))
6. 问题
1. Hive里的Decimal数据类型,在当前版本还属于Bate数据类型,默认不启用,需要设置planner.enable_decimal_data_type参数来启用,在Drill中执行如下语句,可以永久启用Decimal数据类型:
ALTER SYSTEM SET planner.enable_decimal_data_type=TRUE; #是否似曾相识?2. 自1.5版本之后,Drill使用Direct Memory来执行Sort操作,之前版本可以执行成功的SQL,在这后的版本,可能会因内存不足而执行失败并返回错误信息。但会对内存的使用计算更精准。
7. 最后
Apache Drill发展时间虽然短,但它是非常灵活和适用很广的一个实时查询工具。可以看到它适用于多种文件格式和多种数据库。但需要注意目前的版本在使用和兼容上还是需要等完善的。