Google File System及其继任者Colossus
Google File System及其继任者Colossus
在CMU 16Fall学期Storage Systems的课堂上,我有幸听了在Google Infra Team的Larry Greenfield的一个Lecture。其中,Larry对GFS的设计初衷理念、优劣势、瓶颈、改进以及现役系统Colossus (GFS2)进行了简要介绍。其中涉及的内容相当宝贵,故在这里记下。
背景
遥想谷歌创业之初,还是个规模不过数十人的小公司。他们手里有Page Rank算法,并打算将其实现为风靡全世界的搜索引擎。既然要做搜索引擎,第一步自然是用爬虫爬取整个互联网的网页,并将其存储、索引起来,这意味着巨大的存储开销。更为糟糕的是,这种规模的存储量远超单机或RAID阵列可以容纳的最大值,所以,分布式存储系统的使用呼之欲出。
由于初创公司的精力、成本等因素,谷歌决定摒弃传统的使用大而高可靠性服务器作为存储节点的分布式文件系统,转而使用最便宜、能在当时市场以最高性价比买到的普通主机作为集群成员。由于商业主机相较于高稳定服务器在稳定性上存在数量级的差异,谷歌自主开发了一款具有高容错性的分布式文件系统:Google File System (GFS)。
无论在设计理念还是应用规模上,GFS都是划时代的。不过,从现在看来,谷歌在当初的设计充满了简单粗暴。为了简化系统,GFS仅适用于以下场景:
- 文件系统中的文件大(GB级及以上)而少
- 对文件操作多为顺序读取、复写或追加,几乎没有随机访问
该场景听上去似乎十分荒谬——打开我们身边台式机或笔记本电脑的文件浏览器,我们能看到铺天盖地的数KB~MB的小文件;而无论是用Office编辑的文档还是被应用程序使用的临时文件,随机访问都占据大半壁江山,这也是为何硬盘固件设计者倾其所能将随机访问重新编排,使其尽量类似顺序访问而优化访问效率。然而,如果我们关注于谷歌建立GFS的目的,一切又就非常合理了:每个分布式爬虫打开一个文件并不停地将爬到的内容顺序追加,索引器和Page Rank算法不停顺序读取这些大文件并吸收他们需要的信息。正是GFS的应用场景和谷歌核心业务的高度匹配性,才让这个实现粗糙的文件系统成为谷歌所有数据的脊梁。
Google File System
(熟悉的读者可直接空降下一章节:GFSv2: Colossus)
现在我们试着从头开始体验GFS的建立过程。首先需要确定的是,和任何其他文件系统一样,GFS将文件分块(Chunks)存储,从而达到更好的追加效率。而谷歌面对着上千台主机,需要确定一个方法将数据块合理而均匀的散布在主机上。在之前的日志里,我介绍了在集群上从头搭建云存储系统的傻瓜教程,而其中最重要且精妙的一步是利用一致性哈希(Consistent Hash)来分布不同文件。在那篇文章的存储系统中,文件和文件的独立无关的;而在谷歌将要搭建的文件系统中,存储基本单位(数据块)之间是相关的,不幸的是,一致性哈希并不能很好解决不同文件协同操作的一致性和原子性问题,故不再适用于目前的情况。GFS则采用了一个更为简单粗暴的办法:不知道哪个数据块在哪里?专门用一台机器全部记下来不就好了!
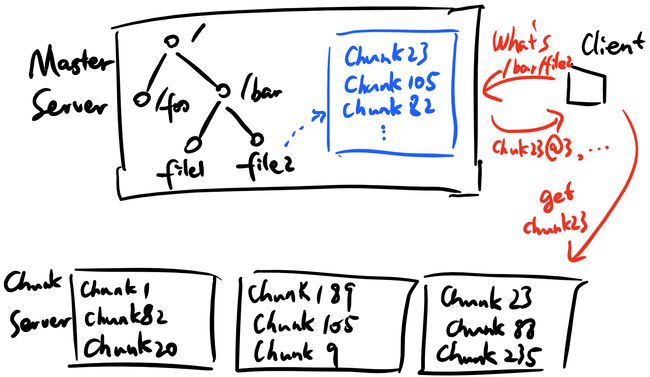
如上图,一个GFS集群由一个Master Server和大量Chunk Server组成,其中Chunk Server以大文件的形式存储文件数据块,每个数据块由全局唯一的id标识并作为该数据块在本地文件系统的文件名;Master Server存储除了数据块以外的所有信息:文件系统树形结构、文件和目录的访问权限、每个文件内容数据块的ID列表,以及每个数据块所在Chunk Server的位置。
该设计乍一看极不合理,似乎将所有重头工作都交给Master进行。然而,考虑到上文适用场景中“文件系统中的文件大(GB级及以上)而少”的特点,Master存储的有关文件的数据量相当少。另外,由于客户端每读/写一个数据块都会联系Master Server至少一次,同时Master也需要维护每个数据块的基本信息,数据块越少越能减轻Master节点的负担——在实现中,GFS规定一个数据块的大小为64MB,远远大于常规本地文件系统4KB的数据块尺寸,当然,相较应用场景中GB级的文件大小,64MB依然显得相当合适。在这里我们再度看出,GFS正是完全针对特定应用场景而设计的文件系统。
Master Server
正是由于文件数目极度有限、每个文件也仅仅包含较小规模数量的64MB数据块,Master Server需要存储和维护的数据非常少,以至于被Master的内存全部容纳还绰绰有余。当然,对于文件系统树形结构、文件和目录的访问权限、每个文件内容数据块的ID列表等数据,由于仅由Master存储唯一副本,Master会将其保存在硬盘上,辅之一定的备份机制(如RAID、定期全盘备份等)以保证数据的万无一失。但对于每个数据块所在Chunk Server的位置信息,Master并不会做任何措施将其永久保存,相应的,Master会定期询问所有Chunk Server其存储的数据块列表,并重建位置信息映射表,如下图所示:

在此架构下,常见的文件目录结构操作(新建目录、改名、删除)等均由Master完成。由于对这类数据负责的结点有且仅有一个,GFS在保证各类操作的原子性和数据一致性上有得天独厚的效率优势:无需复杂而昂贵的分布式事务或分布式副本管理算法,仅依靠本地互斥锁便可实现原子性的目录结构修改。而这是基于一致性哈希进行文件划分、建立伪文件系统的OpenStack Swift至今也不能实现的。
Chunk Server
如前文所描述的,Chunk Server的职责仅仅在于存储数据块。(当然在实际系统中,Chunk Server还要负责在客户端上传文件时确定数据块存储顺序、选举主副本等。本文将跳过这类细节,如想获取更详细的GFS实现,请参阅参考文献[3]) 为了设计简单,Chunk Server将数据块以普通文件的形式存储于Linux的文件系统中(如ext3)。当Server发起询问时,Chunk Server会检查自己存储的所有数据块文件名,(也许会检查数据块是否遭到损坏,)并将有效的数据块名整理成列表回答给Server。
需要注意的是,Chunk Server并没有自己实现任何复杂神奇的缓存控制算法,而仅仅利用OS的默认文件缓存进行有限的加速。该简化设计不会对整个系统造成很大性能损耗,是由于适用场景中的文件读写特征决定了文件访问极弱的局部性(顺序读写+大数据块)。这再次凸显了GFS作为一个特定文件系统与众不同的地方,毕竟通用文件系统无一例外的绞尽脑汁提出新颖精妙的缓存算法,就为了降低那么一丢丢cache miss rate。
当错误来临时 - GFS容错性措施
前文我们提到,作为初创公司的谷歌采购了大量便宜但不可靠的商业主机作为GFS的硬件载体,这意味着各种形式的错误将是常见情况。这些错误包括但不限于:硬盘故障、死机(CPU/内存故障)、网络故障、机房断电、软件bug,他们的影响范围小到单个文件、大到整个机房,错误后果轻则暂时无法响应任何请求、重则永久性丢失受影响的文件。如何在这么纷繁复杂的错误面前保证存储在文件系统的文件不丢失,是GFS有别于之前文件系统的最大特色。
在有关架构云存储系统的日志里,我们提到了一个提高容错性的基本策略:副本存储(Replication)。该策略的原理非常简单:即使因为错误丢失单个文件的概率可观,短时间内丢失多个副本的概率却很低。只要我们的系统能够在丢失一个副本时及时探测到损失并创建一个新的,丢失数据将几乎不可能发生。具体在GFS的实现中,每个数据块会被三台Chunk Server存储,在写入数据时,数据会被同时写到选定的三台存储结点的硬盘中;而当某一台Chunk Server因为任何问题失去响应、从而无法提供数据块时,Master会寻找正常运行并存有改数据块副本的Chunk Server并着手将其复制到一台新的节点上。
上述流程的问题在于,Master如何探测到一个Chunk Server失去响应、或因为任何原因丢失/损坏了某个数据块呢?我们在前文已经给出了答案:定期询问。定期询问既能让Master的Chunk ID-Chunk Server映射表保持更新,又能帮助Master及时意识到数据块的丢失,从而启动恢复流程。
以上提到的副本存储、恢复策略很好的消弭了Chunk Server出错时对整个系统带来的影响。那么假如Master Server出错了又将如何?
Master Server作为整个系统的Single Point of Failure,一旦出错对整个系统带来的影响远比上文所述严重:因为Master参与绝大部分操作,Master未响应意味着这些操作均不能完成。另外,仅存在一份副本的文件系统元数据也会因为Master的损坏而永久丢失,而元数据一旦丢失,及时所有数据块都存在,整个文件系统也完全无法恢复。针对第一个问题,谷歌采用了Standby Server作为解决方案:即,设立其他服务器并模仿Master的一举一动,一旦Master失去响应,Standby Server充当新的Master节点。而对于第二个问题,大量传统数据备份方案(RAID/在线备份/离线备份)会很好的解决这一点。由于Master Server毕竟占少数,为了保证其高可靠性而采用更昂贵的措施并不会对总体开销带来太大额外提升。
神秘的继任者 - GFSv2: Colossus
GFS的简单架构介绍已经结束了,但所有人都总多少有点不尽兴的感觉:毕竟GFS是一个初创公司为了节约陈本、节省时间做的一个粗糙系统,虽然在之后的日子随着Google的壮大几经演化,但一些结构上的不完美始终让人耿耿于怀:中心化的Master让整个系统始终被Single Point of Failure的阴霾笼罩;有限的文件数目和数据块数目限制了整个文件系统的尺寸;而更为关键的是,随着Google的各项业务逐渐完善,在设计GFS时所设立的适用场景正在逐渐瓦解,大量较小而多的文件需求开始出现。这一切都预示着谷歌即将做出改变。
在这之前,学术界已经做了相当多相关探索。USENIX FAST每年都会出现大量分布式文件系统的论文,其中不乏以GFS为原型,想方设法做出分布式Master Server架构、支持大目录、多文件等的原型系统。遗憾的是,这些文件系统均没有在工业界得到广泛应用。而在开源界,大名鼎鼎的Hadoop项目下有GFS的开源实现HDFS,其从诞生至今都一直被各大公司开发、使用,虽几经演化已与当年的GFS差距甚大,HDFS在总体架构上始终没有重大变更,从而依然受到GFS固有缺陷的困扰。
大概从2010年起,Google用全新架构的文件系统替换了GFS,新系统拥有分布式元数据管理、4MB的数据块和理论上无限大的目录规模支持:妥妥的官方逼死同人系列。让人感叹的是,Google对来头如此大的新系统的架构和实现只字不提,对外公开的仅有其令人难以捉摸的名字——Colossus。
如序言所言,由于CMU 15746 Guest Lecture,我有幸地听从Larry Greenfield讲述了并不对外公开(事实上展示用幻灯片对我们也是不开放的)的Colossus架构。由于课后手上没有任何可供参考和回忆的资料,以下内容仅供参考,且严禁转载或用于其他用途。
重构系统从改名字做起
当然这是句玩笑话(对微软这似乎不是玩笑?) 不过在讲述GFSv2之前,我们有必要理清一下新系统中的若干组件以及其与GFS相关组件的对应关系:
- Colossus File System:该系统名字的又来,本质上仅仅是分布式元数据管理子系统,但也是整个新系统的核心。对应原系统的Master Server。
- D Server:数据块存储服务器,对应原系统的Chunk Server。其在具体数据块存储和管理方式上的改进未知,且非重点,此处不做详细展开。
分布式Master Server: CFS
在新一代文件系统中,最大变化、也最令人瞩目的莫过于分布式元数据管理节点的实现。在CFS的实现上,谷歌向我们完美地展示了如何将新问题(不择手段地)转化为已有问题,并将架构上的暴力美学体现得淋漓尽致。
扩展元数据管理节点的第一步,是将原有的单节点树形文件系统结构存储方式改为基于key-value store的键值存储,具体原理类似于OpenStack Swift。但CFS如何在将语义上的树形文件系统结构实现为键值存储的同时还保证相应操作的原子性,我们不得而知。所幸的是,我们也许可以在学术界找到一些线索:例如,TableFS就提出了一种方式来将文件系统元数据表示为k-v数据表;而我在开源项目H2Cloud也利用了相似的方法在OpenStack Swift的键值对象存储上建立了完整语义的文件系统。
总之,Google将文件系统元数据表示为了一个表。而对于一张数据表,Google有非常成熟的方法来分布式处理之:BigTable。关于BigTable的实现细节我在此处不多做描述,有兴趣的读者可以参考其开源实现Apache HBase。Google BigTable能在分布式集群上维护一个key-value store的数据库并提供极高的读写性能。通过将文件元数据维护在BigTable上,CFS成功实现了分布式扩展。
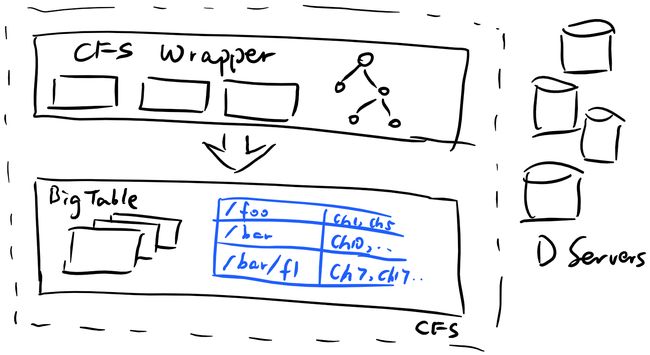
事情当然没有这么简单,熟悉BigTable的读者应该能够反应过来,BigTable数据库是依托GFS建立的,而这似乎形成了死结:扩展GFS需要依靠BigTable,而BigTable建立在GFS上。事实上事情并非如此:由于CFS存储的元数据相较整个文件系统非常小(大约万分之一),一个可扩展性不那么强的GFS也能够胜任将其存下的工作。因此,Colossus通过将元数据存储在GFS上的方式实现了比GFS大若干数量级的扩展水平。
当然,Google不会就此满足。毕竟一次系统重构代价极高,若不能一次将可扩展性做足,势必在不久的将来面临再次重构的困境。既然较小的Colossus的元数据能够存在GFS,那么更大的Colossus元数据是否能存在一个较小的Colossus上呢?
根据这个思路一直想下去:100PB数据的元数据大约10TB,10TB数据的元数据大约1GB,1GB数据的元数据大约100KB。经过这几层压缩,数据量已经小到能够放进极小规模的分布式系统甚至单机上了!

是的,这就是CFS的架构。跟我念一遍:Colossus是一个通过将元数据存储在一个将元数据存储在另一个将元数据存储在Google Chubby(分布式锁管理系统,也可理解为一个小型强一致性文件系统)上的文件系统上的文件系统而获得高可扩展性的分布式文件系统。
这一套充斥着糙快猛的哲学和暴力美学的系统架构方式实在是刷新了我的三观。对此读者(包括我)第一个问题很可能是:既然说Master Server是GFS的Single Point of Failure,那么Colossus中最下层的Chubby岂不是Single Point of Single Point of Single Point of Failure,只要Chubby小集群中的过半节点无法响应,整个巨大的Colossus文件系统也就随之崩坏了不是么?
为了解答这个问题,我们需要对Google Big Table (亦或是Apache HBase)的基本原理有一定了解。Big Table最大的特性之一是采用了LSM树固化所有修改,LSM树将一切修改转化为追加日志的形式,这意味着在这种数据结构中,随机写操作几乎不存在。而对于GFS/Colossus,顺序写操作仅在需要新创建数据块的时候联系Master/CFS,其余时候只需和Chunk Server/D Server做数据交换;同时,LSM树在上层的修改合并会让创建数据块的操作变得更加不频繁,从而进一步降低Big Table联系Master的频率。该特性导致的直接结果是,即使Master/CFS整体失去响应,其上的Big Table仍然能够正常读写相当长一段时间。根据前文提到的每层CFS对数据量的压缩率,越向下层的BigTable/CFS,访问频率越是以上万倍的速度衰减。因此,即使Chubby整体宕机,整个Colossus集群依然能运行极长时间,而这个时间差对于Google检测到Chubby失败而采取回复措施已经绰绰有余。
其他改动
除了总体架构上的改动,Colossus还在其他若干方面做出了和老系统不同的决定:
- 数据容错不再使用副本,转而使用更复杂的Reed-Solomon编码。类似于RAID-6,Reed-Solomon允许被编在同一组的4个数据块最多丢失两个。这样的编码能在不对数据丢失概率做出太多负面影响的情况下减小存储开销,而付出的代价则是更复杂的系统和更高的计算量。
- D Server采用更激进的缓存策略,同时客户端也采用更高并发度的方式获取数据块,其目的在于减少tail-latency,即最慢访问延迟,让”最糟糕的情况不那么糟“。
总之,由于缺乏学术论文,Colossus的设计详情和表现性能至今不被外人所知,Larry's Lecture也只是揭开了庞大复杂的新系统的冰山一角。尽管新系统看起来简单粗暴,但作为系统设计者最应该清楚,一个能够实际投入使用的系统从来都不像看上去那么简单——对于Colossus如此,对于GFS亦如此。正是因为实现难度远大于设计难度,进行系统设计时才需要遵循"Simple is vital"这条黄金准则。
希望这片小博文能对读者有所启发。由于我学识甚浅,有任何错误希望大家不吝指正。
参考文献
- CMU 15746 Storage Systems Lecture Slides, Greg Ganger and Garth Gibson
- Evolution of Google FS, Larry Green Field, 2016 (15746 Fall Guest Lecture)
- Ghemawat, Sanjay, Howard Gobioff, and Shun-Tak Leung. "The Google file system." ACM SIGOPS operating systems review. Vol. 37. No. 5. ACM, 2003.
- Ren, Kai, and Garth A. Gibson. "TABLEFS: Enhancing Metadata Efficiency in the Local File System." USENIX Annual Technical Conference. 2013.