《CCNet: Criss-Cross Attention for Semantic Segmentation》--阅读笔记-ICCV2019
这两天实验室大佬有篇工作去ICCV了,羡慕的一腿,加油加油,多读书多看报。
本文作者:
Authors
Zilong Huang1∗ , Xinggang Wang1† , Lichao Huang2 , Chang Huang2 , Yunchao Wei3,4, Wenyu Liu1
Motivation
现有的FCN的方案由于缺少有效的上下文信息,存在着limitation。 due to the fixed geometric structures, 受限于 local receptive fields and short-range contextual information.
使用连续稀疏注意取代非局部网络中的单层密集注意力
Contributions
1、节省GPU显存,与non-local block比较,节省了11倍的显存.
2、计算高效,递归交叉注意力减少了85%的Flops相比于non-local的block
3、达到了新的SOTA performance 数据集有: Cityscapes, ADE20K, instance segmentation benchmark COCO
Previous method
ASPP
不足:从周围像素获取信息,不能获得dense contextual information
金字塔池化
均等的上下文信息被所有像素所采纳,不符合不同的像素有不同的依赖
non-local OP![]() in time and space
in time and space
Network

特征提取网络ResNet-101作为backbone,去除最后两个下采样层、加上dilate 卷积以后获得原图1/8大小的特征图 X
加一个卷积层降维到H,将特征图 H 输入 第一个 criss-cross attention (CCA) module 得到 H’, H’ 仅仅只将水平,竖直方向的远距离上下文信息进行聚合(因为这两个方向是not powerful enough的)。特征图 H’ 输入到第二个CCA,得到H’’(获得的feature是包含richer和dense context information的),H’’的每一个位置都捕获到了所有像素的信息。两个CCA是一样的结构share了一样的weight,为了防止太多的参数引进。叫做recurrent CCA(RCCA)。这一步操作将收集到每一个像素的信息,连接 X 和H’’ 送入多个带bn和激活函数的卷积层以及分割层得到最后的分割结果。
CCA结构
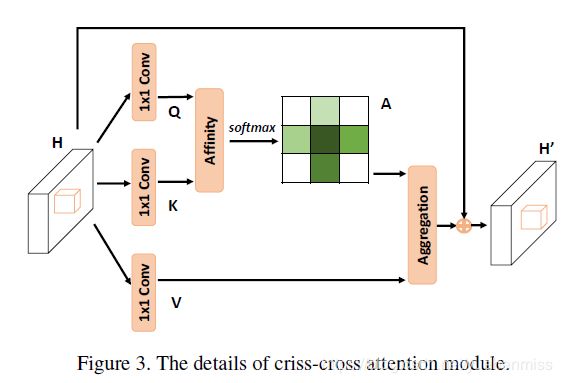
![]() 先使用两个1✖1卷积核的卷积生成K和Q,
先使用两个1✖1卷积核的卷积生成K和Q,![]() ,C'是小于C的,因为需要降维操作。下一步采用affinity操作
,C'是小于C的,因为需要降维操作。下一步采用affinity操作![]() ,对于每一个Q中的位置u,都能得到一个长度为C'大小的向量
,对于每一个Q中的位置u,都能得到一个长度为C'大小的向量![]() ,在同样的u的位置,集合
,在同样的u的位置,集合![]() 是可以在K上被提取出来的,
是可以在K上被提取出来的,![]() 表示第i个
表示第i个![]() 元素,那么affinity操作为
元素,那么affinity操作为
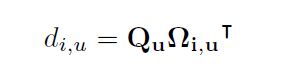 ,
,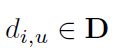 是特征
是特征![]() 和
和![]() 之间的纠偏率,其中
之间的纠偏率,其中![]() 随后在D的channel维度上进行了softmax操作,得到attention map A。
随后在D的channel维度上进行了softmax操作,得到attention map A。
在CCA的下面分支中,H也用一个1✖1卷积核的卷积滤过,得到![]() ,V也同样存在每个u的位置有
,V也同样存在每个u的位置有![]() ,以及集合
,以及集合![]() ,
,![]() 是V中每一个u位置有想通row和col的集合,这个C和输入的C是一致的。因此最后的 contextual information就是
是V中每一个u位置有想通row和col的集合,这个C和输入的C是一致的。因此最后的 contextual information就是 这里
这里![]() 是u位置的
是u位置的![]() ,
,![]() 是个标量,是i号channel和u号位置的A中值。上下文信息就这样,被加入到H ,这样的操作使得增强了 local features和the pixel-wise representation
是个标量,是i号channel和u号位置的A中值。上下文信息就这样,被加入到H ,这样的操作使得增强了 local features和the pixel-wise representation
RCCA
解决像素与周围之间的联系,引入了recurrent CCA(一次CCA并不能够cover)。 传递过程如下

第一次CCA,我们在计算左下角点的f时,只能包含左上角点和右下角点的信息,此时并没有左下角点与蓝色点的相关信息。
但在计算左上(or右下)点时,是计算了蓝色点与它们的相关性信息的。
第二次CCA,当我们再次计算左下角点的 时,再次包含左上与右下点的信息,此时的左上 与右下已经不是当初那个信息,它们已经有了蓝色点的信息,此时便可以间接地将蓝色点信息传递给左下点。
同理,其他不在左下点十字型位置的像素点,都可以通过这种方式在第二次CCA的时候就将信息传递给左下点。于是实现两次CCA便“遍历”了所有点。
事实上,我们可以发现蓝色点信息是传递了两遍给左下点的(左上传递了一次,右下传递了一次),虽然是间接传递没有直接计算得到的结果强度大,但这种对于信息的两次加强也很有可能是最终效果 略胜于 Non-local的原因之一。(这段来自https://zhuanlan.zhihu.com/p/51393573, 感谢解释)
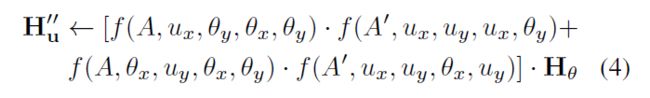
结果和non-local相比,1/11的内存消耗,15%的计算开销