深度学习之----TextCNN文本分类
1.卷积神经网络
英文名称:(Convolutional Neural Network),简称CNN。由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC。是深度学习技术中极具代表的网络结构之一,最早应用在图像处理当中,现在在自然语言处理应用也非常多。
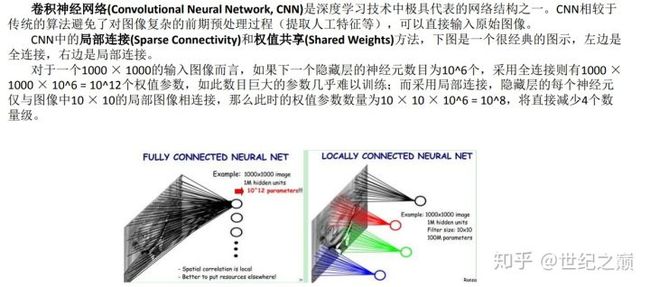

卷积神经网络示意图
2.构成部分
主要由5个部分组成:输入层,卷积层,激活层,池化层,全连接层,搞懂这5个层怎么运作,基本就搞懂卷积神经网络的流程了
1.输入层
图像处理中是输入就是图像尺寸像素(1024*768),三维(R,G,B),
自然语言处理中一般将原始文本使用word2vec转化成词向量的形式进行输入
2.卷积层
卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的 权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个 偏置参数),得到卷积层上的结果。如下图所示。
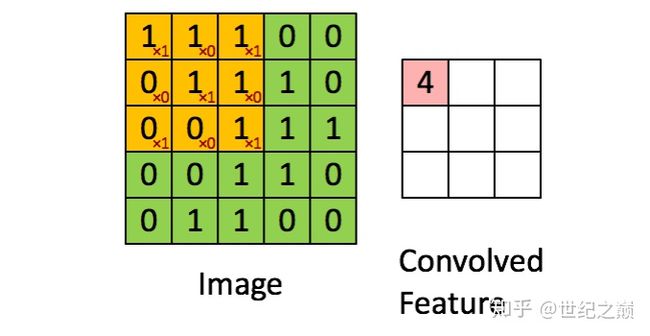
绿矩阵为输入,黄矩阵为卷积核,右边的矩阵为卷积层
卷积层是卷积核【黑框中小矩阵】在输入中【大矩阵】通过逐一滑动窗口,计算每次的参数乘积后相加得到的一个新矩阵。
高维度卷积层
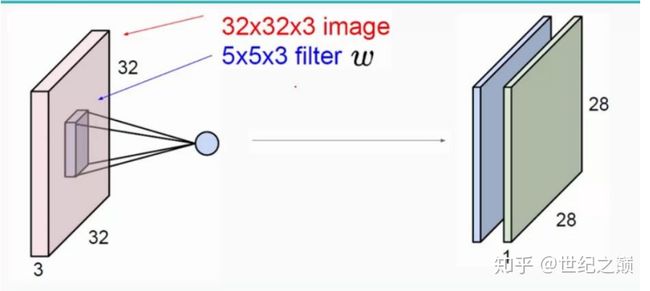
输入图像是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野),这里注意:感 受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征 图,上图是用了两个filter得到了两个特征图
这里注意两点:
- 原始图有多少维,卷积核就有多少维
- 有多少卷积核,就输出多少特征。
3.激活层
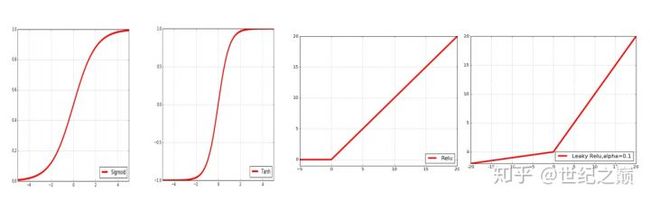
将上面特征图中的得到的每个参数放入到下面的几个激活函数中进行处理
Sigmoid(S形函数),得到的是[0,1]区间的数值
Tanh(双曲正切,双S形函数),得到的是[-1,0]之间的数值
ReLU 当x<0 时,y=0,当x>0 时,y = x
Leaky ReLU 当x<0 时,y = α(exp(x-1)),当x>0时,y= x
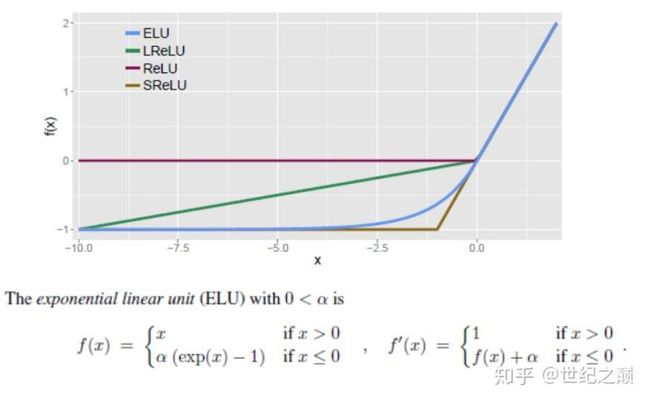
4.池化层
池化层总共有4个处理步骤:
- 处理策略1
在池化层中,进行压缩减少特征数量的时候一般采用 两种策略
- 最大池化(max pooling),也就是取特征图中的最大值作为输出值,这个最常用

2.平均池化(Average Pooling:)也就是取特征图中的平均值作为输出值
- 处理策略2【避免过拟合问题】
-
正则化
正则化,通过降低模型的复杂度,通过在cost函数上添加一 个正则项的方式来降低过拟合,主要有L1和L2两种方式
2.Dropout
通过随机删除神经网络中的神经元来解决过拟合问题,在每 次迭代的时候,只使用部分神经元训练模型获取W和b的值
Dropout就是利用这 个原理,每次丢掉一半左右的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间 的依赖性,即每个神经元不能依赖于某几个其它的神经元(指层与层之间相连接的神经元),使神经网络更加 能学习到与其它神经元之间的更加健壮robust(鲁棒性)的特征。另外Dropout不仅减少过拟合,还能提高准确 率。

- 处理策略3【误差反向传播】
Maxpool 池化层反向传播,采用的方法是:除了最大值处继承上层梯度外,其他位置置零

- 处理策略4【打补丁】
在卷积处理过程中我们的图片由4*4,通过卷积层变为3*3,再通过池化层变化2*2,如果我们再添加层,那么图 片岂不是会越变越小?怎么办呢,有以下两种方式:
- Zero Padding,在原始输入层外边全补0

原来是4*4,卷完后是3*3,如果在外边都补一层0,就变成6*6,卷完后仍然是4*4大小,保持不变
2.Same Padding,
把最外边的数值复制一遍,方法跟上面是类似的,这个根据具体需求来进行选择
5.全连接层
通 过不断的设计卷积核的尺寸,数量,提取更多的特征,最后识别不同类别的物体。做完Max Pooling后,我们就会把这些 数据“拍平”把3维的数组变成1维的数组,丢到Flatten层,然后把Flatten层的output放到full connected Layer里,采用softmax对其进行分类。

6.利用Text-CNN模型来进行文本分类
github链接:https://github.com/gaussic/text-classification-cnn-rnn
训练模型
命令窗口输入:python run_cnn.py train
Epoch: 5
Iter: 3200, Train Loss: 0.021, Train Acc: 98.44%, Val Loss: 0.2, Val Acc: 94.94%, Time: 0:04:34
Iter: 3300, Train Loss: 0.015, Train Acc: 100.00%, Val Loss: 0.17, Val Acc: 95.68%, Time: 0:04:43
Iter: 3400, Train Loss: 0.02, Train Acc: 98.44%, Val Loss: 0.21, Val Acc: 95.18%, Time: 0:04:51
Iter: 3500, Train Loss: 0.013, Train Acc: 100.00%, Val Loss: 0.22, Val Acc: 94.24%, Time: 0:05:00
No optimization for a long time, auto-stopping...
训练模型用了5分钟
测试模型
命令窗口输入:python run_cnn.py test
precision recall f1-score support
体育 1.00 0.99 0.99 1000
财经 0.95 0.99 0.97 1000
房产 1.00 1.00 1.00 1000
家居 0.98 0.90 0.94 1000
教育 0.88 0.96 0.92 1000
科技 0.97 0.98 0.97 1000
时尚 0.97 0.97 0.97 1000
时政 0.96 0.93 0.95 1000
游戏 0.98 0.97 0.98 1000
娱乐 0.98 0.98 0.98 1000
micro avg 0.97 0.97 0.97 10000
macro avg 0.97 0.97 0.97 10000
weighted avg 0.97 0.97 0.97 10000
准确率达到97%,还是相当可以的。
参考文章
【1】简书--基于tensorflow+CNN的新浪新闻文本分类--https://www.jianshu.com/p/b1000d5345bb
【2】知乎--这可能是最通俗易懂的卷积神经网络笔记--https://zhuanlan.zhihu.com/p/47849841
【3】github--新闻文本分类--https://github.com/gaussic/text-classification-cnn-rnn