cs231n笔记:lecture5
Convolutional Neural Networks
fully connected layer
在前面的课程中,我们用到的神经网络的层都是把输入展开与权重矩阵W做矩阵乘法,这也意味着输入数据将与W中的神经元每个都直接连接,所以这也叫全连接层,但是全连接层存在一些问题,比如说我们需要将输入的32323的彩色图像拉伸成13072的长向量才能与权重W连接,但是这个拉伸过程实际上就丢失了输入图像空间位置信息。而且还有一个问题就是全连接层因为要与每个输入都直接连接,所以该层的参数就会非常多,例如下图我们经过一个全连接层得到10个分类的输出我们需要103072的权重W,仅这一层就高达30k个参数需要训练。
总结一下全连接层的问题:
会丢失空间位置信息
需要训练的参数量很大

Convolutional Neural Networks
由于这些问题,接下来我们会介绍新的网络,也就是这门课的主角,卷积神经网络,他能允许我们保留输入的空间结构,能保留维度信息,而且卷积操作需要训练的参数会比传统的全连接层要少很多。先来看一下经典的卷积神经网络结果的示意图,稍后我们会一个部分一个部分的详细介绍每个部分。
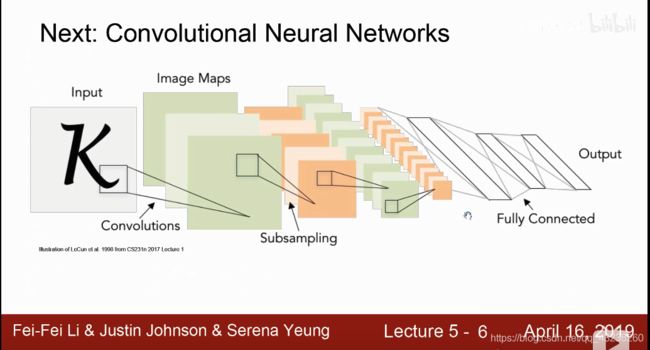
从图中看到,得到网络的输入input之后,首先会做convolutional操作得到卷积的结果image maps,或者叫feature maps。然后会经历一个subsampling下采样操作,一般是由池化操作完成下采样操作,可以把image maps的结果缩小,得到大而化之的结果防止过拟合,减少参数,最后会加上一个全连接层,得到输出。
convolutional
下面我们来介绍一下卷积操作

可以看到,卷积层,首先需要一个filter,也可以叫卷积核,要注意的是卷积核filter总是会与输入数据有相同的通道数,然后卷积操作就是拿着这个卷积核在输入的image上做对应位置的点乘运算,然后在输入的image位置上滑动,得到卷积结果feature map,这样说可能有点抽象,我们来看一张示意图

这张图就比较能清楚的描述卷积过程,图中的中间层的白色就是卷积核filter,卷积核对应的输入位置叫感受野,最后得到的蓝色输出结果叫feature map特征图。
一开始卷积核会在图像的左上方位置开始卷积操作得到特征图的第一个输出结果,然后卷积核以设定好的步长向右移动,移到最右面之后再向下移动。直到移到图像的最右下方,得到完整的卷积结果。而且因为卷积核本身有大小,所以如果没有padding的话得到的特征图feature map肯定是要小于原来大小的。
下面我们来看一下一次具体的卷积得到结果的过程:

如图,其实就是卷积核与对应位置处做乘法然后求和得到最后这个位置的输出。
因为实际问题中图像的输入都是三通道的。所以输入将是三维的输入,那么filter卷积核也要是三维的,而且一个卷积核就会得到一个feature map,有几个卷积核就会得到几个feature map

比如上图,我们有32323的图像,我们用6个卷积核对输入图像进行卷积操作,最后就会得到6个特征图,得到的输出就是28283的,至于为什么是28*28,下面我们会讲到。

经过推导我们可以得到图中这个公式output size = (N - F)/stride +1,N就是输入图片的尺寸大小,比如32323的图片,那么N就是32,F是我们做卷积操作时候选取的卷积核的大小,常用的卷积核大小有33 55,77,等等,例如我们选取55的卷积核,那么这里的F就是5,stride是指卷积核移动的时候的步长,这里选取步长为1,那么由上面这个公式就可以计算得到输出的尺寸大小为(32-5)/1 + 1 = 28。这就解释了为什么上面我们做卷积操作得到的输出是28*28的。

上图给出了完整的关于卷积操作的总结。
下面我们将通过一些例子来解释一下卷积操作,实际上是在干什么,我们来理解一下卷积它是在图像中获取什么信息。

例如,我们有一个卷积核是处理图像中关于眼睛的信息的,那么在卷积的过程中,它将会捕捉图像中有没有“眼睛”,如果图像中的某个区域与眼睛不匹配,那么卷积会得到较低的值,如果图像中某个区域与眼睛匹配,那么卷积就会在这个区域得到较高的值,完成卷积操作之后,在与卷积核要检测的特征匹配的位置,feature map就会是高值,意思就是这个地方存在这个卷积核要检测的特征,反之就是这个位置不存在需要的特征。一个卷积核就意味着检测一个特征,因此通常我们设置多个卷积核就是用于提取图像的不同特征,多个卷积核卷积得到的多通道feature map就表示了图像关于这些特征有无的信息。

再比如这个图,对这个输入有四个卷积核filter,对于filter1,它左边是低值,右边是高值,卷积之后他就会把左边暗,右边亮的边缘提取出来,如下图所示确实如此,依次类推,filter2会把右边暗左边亮的边缘提取出来,filter3会把上边暗下边亮的边缘提取出来,filter4会把上边亮下边暗的边缘提取出来。
通常在前几层的卷积,我们会提取一些简单的信息,比如光亮,边缘等,越往后,卷积就会得到信息的组合,开始出现纹理,甚至眼睛,等等这样一些高级的特征。
1*1convolutional
下面我们介绍一种特殊的卷积核,11卷积。这种卷积现在也经常使用到,它有几个非常优秀的特点,我们来介绍一下:
**根据11卷积核的个数,可以实现降维或者升维的作用**
跨通道的信息交流,因为实际上他会对各个通道的数值进行求和汇总得到一个新输出
减少参数量
加深模型深度,提高非线性表示能力

上图明确给出了同样是由卷积得到282832的输出,先使用11卷积核再用55卷积核卷积参数量比直接用5*5卷积卷积核少了十倍以上。
pooling
卷积之后通常会加入一个pooling操作,一个是为了减少参数量,一个是使模型具有更强的泛化能力,pooling可以使模型学习到一些大而化之的东西,而丢掉一些细节比如一些数据噪声之类的。
要注意的是pooling操作是在每个feature map上独立进行的。

对于pooling的作用我们来看一张比较明显的图就很好理解了
 如这个图所示,虽然上下两个输入位置是不同的,经过那个检测眼睛的卷积核卷积之后得到的输出位置也有点不同但是我们经过池化操作之后,确可以得到相同的输出。这就是平移不变性,可以理解为只要是在类似的位置卷积得到了高值,池化之后就是相同的,这也提高了模型的泛化能力。
如这个图所示,虽然上下两个输入位置是不同的,经过那个检测眼睛的卷积核卷积之后得到的输出位置也有点不同但是我们经过池化操作之后,确可以得到相同的输出。这就是平移不变性,可以理解为只要是在类似的位置卷积得到了高值,池化之后就是相同的,这也提高了模型的泛化能力。
与卷积类似,池化也有公式可以总结经过池化之后的输出大小

summary
这是一个简单的用于分类的卷积神经网络的例子,由几个卷积层和池化层最后连上全连接层实现,我们可以清楚的看到,前面几层卷积层,提取的都是一些简单的信息,后面的卷积层就会把这些简单的信息组合起来得到越来越复杂的特征,最后经过全连接得到分类结果。

这里加入一些我个人的理解,对于卷积核本身来说,一开始几层的卷积核他是用于提取简单的特征,比如颜色,线条,边缘等,所以出现这些特征的图片就会经过卷积之后得到较高的值,所以卷积核自己会很简单,但是得到的输出会很接近原始图像,因为他只是提取了一些简单的特征,比如边缘是每个图像都会有的,卷积之后的结果仍然会看得出原始图像的样子,但是越往后,卷积层越深,会把前面卷积层的结果作为输入传递给深层的卷积层,那么这些卷积层就会融合,总结前面提取到的简单特征去融合成复杂特征,就会形成比较复杂部位的检测器,那么如果图像中存在例如眼睛检测器中的眼睛,那么卷积之后的结果就会高,但是这个复杂特征眼睛是针对原始图像来说的,对于真正的卷积的结果其实这时候已经不是图像的维度了,他是融合了之前提取到很多特征的结果,实际上这个卷积结果是很难可视化的,也很难被解释,只能说是深层的卷积会融合并且总结前面提取到的简单特征去检测高级特征,所以随着卷积层的深入,卷积核检测的特征会越来越复杂,比如会出现检测眼睛,轮胎等等这些复杂特征,但是卷积的结果是很难解释的,因为卷积的结果实际上只是说明存不存在这些特征,而不是这些特征本身。所以深层的卷积结果会完全不具备原始图像的样子,并且难以解释,但是这些深层的卷积核确实是在检测原始图像中有没有这些类似眼睛的高级特征,最后这些高级特征会被全部组合在一起连入全连接网络根据检测到的这些复杂特征的组合来判定是哪个分类。
7.4更新理解:
接着上面的卷积理解,我们可以认为在卷积的前几层是提取一些简单的特征,越往后提取的特征会越来越复杂和抽象,会出现一些具体的图案等。那怎么理解越到后面提取的特征越难理解呢,不是提取到复杂的图案特征了吗,比如提取眼睛特征,眼睛不是相比低级的线条特征更容易看出来吗?其实是这样子的提取复杂特征的意思是把前面简单特征融合起来得到的高级特征,意思就是在深层的卷积层里,如果原图像存在这些类似眼睛或者某一特定的高级特征就会在这个卷积核的卷积结果中取得较高的分数。
下面给出常见的卷积神经网络模型

现在的模型都倾向于使用更小的卷积核filter和更深的网络结构,为了减少参数,并且能在网络中加入更多非线性
倾向于不使用池化层和全连接层,而只使用卷积层(这里我还不是很理解怎么做)
传统常见的网络结构就是在若干层卷积-激活层之后加上一个池化层然后重复若干次最后加上全连接层-激活层-最后到softmax分类。