Tsung笔记之监控数据收集篇
前言
压力测试和监控分不开,监控能够记录压测过程中状态,方便问题跟踪、定位。本篇我们将讨论对压测客户端tsung client的监控,以及对被压测服务器的资源占用监控等。同时,也涉及到Tsung运行时的实时诊断方式,这也是对Tsung一些运行时状态的主动监控。
压测客户端的监控
压测端(指的是tsung client)会收集每一个具体模拟终端用户(即ts_client模块)行为数据,发送给主节点(tsung_controller),供后面统计分析使用。
 

- ts_client模块调用ts_mon,而ts_mon又直接调用ts_mon_cache,有些绕,不直观(逻辑层面可忽略掉ts_mon)
- count为计数器,sum表示各项累加值,sample和sample_counter计算一次统计项的平均值&标准差
- tsung.dump文件一般不会创建&写入,除非你在tsung.xml文件中指定需要dump属性为true,压测数据量大时这个会影响性能
-
match.log仅仅针对HTTP请求,默认不会写入,除非在HTTP压测指定
<http url="/" method="GET" version="1.1"/> <match do=’log’ when=’match’ name=’http_match_200ok’>200OKmatch> -
从节点tsung client所记录日志、需要dump的请求-响应数据,都会交由tsung_controller处理
-
ts_mon_cache,接收到数据统计内存计算,每500毫秒周期分发给后续模块,起到缓冲作用
-
ts_stats_mon模块接收数据进行内存计算,结果写入由ts_mon触发
-
ts_mon负责统计数据最每10秒定时写入各项统计数据到tsung.log文件,非实时,可避免磁盘IO开销过大问题
tsung/src/tsung_controller/tsung_controller.app.in对应{dumpstats_interval, 10000}- 可以在运行时修改
-
tsung.log文件汇集了客户端连接、请求、完整会话、页面以及每一项的sum操作统计的完整记录,后续perl脚本报表分析基于此
-
ts_mon模块处理tsung.log的最核心模块,全局唯一进程,标识为
{global, ts_mon}
比如某次单机50万用户压测tsung.log日志片段:
# stats: dump at 1467620663
stats: users 7215 7215
stats: {freemem,"os_mon@yhg162"} 1 11212.35546875 0.0 11406.32421875 11212.35546875 11346.37109375 2
stats: {load,"tsung_controller@10.10.10.10"} 1 0.0 0.0 0.01171875 0.0 0.01171875 2 17,1 Top
stats: {load,"os_mon@yhg162"} 1 2.3203125 0.0 3.96875 0.9609375 2.7558736313868613 411
stats: {recvpackets,"os_mon@yhg162"} 1 5874.0 0.0 604484 5874 319260.6024390246 410
stats: {sentpackets,"os_mon@yhg162"} 1 8134.0 0.0 593421 8134 293347.0707317074 410
stats: {cpu,"os_mon@yhg162"} 1 7.806645016237821 0.0 76.07377357701476 7.806645016237821 48.0447587419309 411
stats: {recvpackets,"tsung_controller@10.10.10.10"} 1 4164.0 0.0 45938 4164 24914.798543689314 412
stats: {sentpackets,"tsung_controller@10.10.10.10"} 1 4182.0 0.0 39888 4182 22939.191747572815 412
stats: {cpu,"tsung_controller@10.10.10.10"} 1 0.575191730576859 0.0 6.217097016796189 0.575191730576859 2.436491628709831 413
stats: session 137 2435928.551725737 197.4558174045777 2456320.3908691406 2435462.9838867188 2436053.875557659 499863
stats: users_count 0 500000
stats: finish_users_count 137 500000
stats: connect 0 0 0 1004.4912109375 0.278076171875 1.480528250488281 500000
stats: page 139 12.500138756182556 1.1243565417115737 2684.760009765625 0.43115234375 16.094989098940804 30499861
stats: request 139 12.500138756182556 1.1243565417115737 2684.760009765625 0.43115234375 16.094989098940804 30499861
stats: size_rcv 3336 3386044720
stats: size_sent 26132 6544251843
stats: connected -139 0
stats: error_connect_timeout 0 11
tsung.log日志文件可由tsung_stats.pl脚本提取、分析、整理成报表展示,其报表的一个摘要截图:
 

异常行为的收集
当模拟终端遇到网络连接超时、地址不可达等异常事件时,最终也会发给主节点的ts_mon模块,保存到tsung.log文件中。
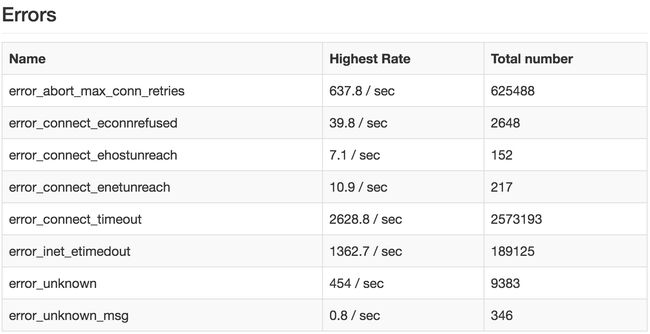
这种异常记录,关键词前缀为 **error_**:
- 比如ts_client模块遇到连接超时会汇报
error_connect_timeout错误 - 系统的可用端口不够用时(创建与压测服务器连接数超出可用段限制)上报
error_connect_eaddrinuse错误
Errors报表好比客户端出现问题晴雨表,再加上tsung输出log日志文件,很清楚的呈现压测过程中出现的问题汇集,方便问题快速定位。

被压测服务器的监控
当前tsung提供了3种方式进行监控目标服务器资源占用情况:
- erlang
- snmp
- Munin
大致交互功能,粗略使用一张图表示:
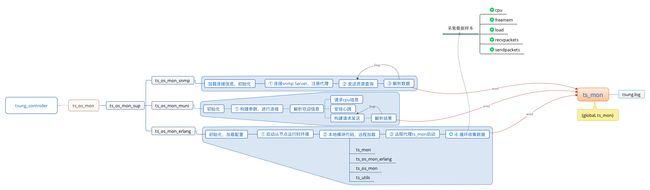 

- tsung_controller主节点会被强制启用监控
- SNMP方式,客户端作为代理主动注册并连接开放SNMP的服务器,SNMP安装针对新手来说比较复杂
- Munin采用C/S模式,自身要作为客户端连接被压测服务器上能够安装Munin Server
- erlang方式,本身代理形式监控服务器资源占用,满足条件很简单:
- 需要能够自动登录连接
- 并且安装有Erlang运行时环境,tsung_controller方便启动监控节点
- 采用远程加载方式业务代码,省去被监控端部署的麻烦
- 现实情况下,我一般采用一个脚本搞定自动部署监控部署客户端,自动打包可移植的Erlang,简单绿色,部署方便
- 提供监控采样数据包括 CPU/Memory/Load/Socket Sent&Recv
- 所有监控数据都会被发送给ts_mon模块,并定时写入到tsung.log文件中
看一个最终报表部分呈现吧:
 

tsung对服务器监控采样手机数据不是很丰富,因为它面向的更为通用的监控需求。
更深层次、更细粒度资源监控,就需要自行采集、自行分析了,一般在商业产品在这方面会有更明确需求。
日志收集
和前面讲到的终端行为数据采集和服务器端资源监控行为类似,tsung运行过程中所产生日志被存储到主节点。
tsung使用error_logger记录日志,主节点tsung_controller启动之后,会并发启动tsung client从节点,换句话来说tsung client从节点是由主节点tsung_controller创建,这个特性决定了tsung client从节点使用error_logger记录的日志都会被重定向到主节点tsung_controller所在服务器上,这个是由Erlang自身独特机制决定。
因此,你在主节点log目录下能够看到具体的日志输出文件,也就水到渠成了。因为Erlang天生分布式基因,从节点error_logger日志输出透明重定向到主节点,不费吹灰之力。这在其他语言看来,确实完全不可能轻易实现的。
基于error_logger包装日志记录,需要一个步骤:
- 设置输出到文件系统中
error_logger:tty(false) - 设定输出的文件目录
error_logger:logfile({open, LogFile}) - 包装日志输出接口
?DEBUG/?DEBUGF/?LOG/?LOGF/ - 最终调用包装的error_logger接口
debug(From, Message, Args, Level) ->
Debug_level = ?config(debug_level),
if
Level =< Debug_level ->
error_logger:info_msg("~20s:(~p:~p) "++ Message,
[From, Level, self()] ++ Args);
true ->
nodebug
end.
和大部分日志框架设定的日志等级一致,emergency > critical > error > warning > notice (default) > info > debug,从左到右,依次递减。
需要注意事项,error_logger语义为记录错误日志,只适用于真正的异常情况,并不期望过多的消息量的处理。
若当一般业务调试类型日志量过多时,不但耗费了大量内存,网络/磁盘写入速度跟不上生产速度时,会导致进程堵塞,严重会拖累整个应用僵死,因此需要在tsung.xml文件中设置至少info级别,至少默认的notice就很合适。
Tsung运行时诊断/监控
Tsung在运行时,我们可以remote shell方式连接登录进去。
为了连接方便,我写了一个脚本 connect_tsung.sh,只需要传入tsung节点名称即可:
# !/bin/bash
## 访问远程Tsung节点 sh connect\_tsung.sh tsung\_controller@10.10.10.10
HOST=`ifconfig | grep "inet " | grep -v "127.0.0.1" | head -1 | awk '{print $2}' | cut -d / -f 1`
if [ -z $HOST ]; then
HOST = "127.0.0.1"
fi
erl -name tmp\_$RANDOM@$HOST -setcookie tsung -remsh $1
需要安装有Erlang运行时环境支持
当然,要向运行脚本,你得知道Tsung所有节点名称。
如何获得tsung节点名称
其实有两种方式获得Tsung节点名称:
- 直接连接tsung_controller节点获得
- 若是IP形式,
sh connect_tsung.sh tsung_controller@10.10.10.10 - 若是hostname形式,可以这样:
sh connect_tsung.sh tsung_controller@tsung_master_hostname - 成功进入之后,输入
nodes().可以获得完整tsung client节点列表
- 若是IP形式,
- 启动tsung时生成日志所在目录,可以看到类似日志文件:
- tsung client端产生日志单独存放,格式为
节点名称.log - eg: tsung15@10.10.10.113.log,那么节点名称为tsung15@10.10.10.113
- 可以直接连接:
sh connect_tsung.sh tsung15@10.10.10.ll3
- tsung client端产生日志单独存放,格式为
如何诊断/监控Tsung运行时
其实,这里仅仅针对使用Erlang并且对Tsung感兴趣的同学,你都能够进来了,那么如何进行查看、调试运行时tsung系统运行情况,那么就很简单了。推荐使用 recon 库,包括内存占用,函数运行堆栈,CPU资源分配等,一目了然。
若问,tsung启动时如何添加recon依赖,也不复杂:
- 每一个运行tsung的服务器拷贝已经编译完成的recon项目到指定目录
-
tsung_controller主节点启动时,指定recon依赖库位置
tsung -X /Your_Save_Path/recon/ebin/ ...
说一个用例,修改监控数据每10秒写入tsung.log文件时间间隔值,10秒修改为5秒:
application:set_env(tsung_controller, dumpstats_interval, 5000).
执行之后,会立刻生效。
小结
总结了Tsung主从监控,以及服务器端监控部分,以及运行时监控等。提供的被压测服务器监控功能很粗,仅收集CPU、内存、负载、接收数据等类型峰值,具有一般参考意义。但基于Tsung构建的、或类似商业产品,一般会有提供专门数据收集服务器,但对于开源的应用而言,需要兼顾通用需求,也是能够理解的。