论文: YOLACT: Real-Time Instance Segmentation
- 0.简介
- 1.YOLACT结构
- 2.Prototypes
- 3.Cofficients
- 4. InstanceMasks组装
- loss fuction
- 5.Fast NMS
- 6.代码 实验
0.简介
惯例,有请作者自己介绍一下本文工作——摘要:
-
是一个fully-convolutional模型
-
29.8mAP——COCO, 33.5fps——a TitanXP。
(精度高于FCIS,低于MaskRCNN之后的。但速度猛提,注意,MaskRCNN仅为为5fps。)
-
分为两个平行子任务:
- 生成一系列Prototype masks
- 预测mask coefficients
然后两者线性结合(矩阵相乘)得出instance masks
-
提出Fast NMS,微小代价换来12ms增速
YOLACT——You Only Look At CoefficienTs,是实力分割单阶段的一个代表算法,不论是模型名字还是原文第一段直接引用Joseph Redmon在YOLOv3中的原话,都致敬了目标检测领域的YOLO,可见他的目标就是real-time。
1.YOLACT结构
首先,图像经过主干网络提取特征,这里使用的是ResNet101-FPN。图中下面的分支,使用FPN的P3输出作为Protonet的输入产生与在原图上全局的k个prototypes(P3同时拥有深层特征有较好鲁棒性以及高分辨率有利于提升Mask质量及小目标精度的特点);同时上面的分支,除了进行典型目标检测的框分类及回归系数之外,还将对每个anchor预测出k个系数cofficients,即每个prototype的系数。然后组装prototypes和cofficients,再进行剪切和阈值处理就得到了instance masks。
2.Prototypes
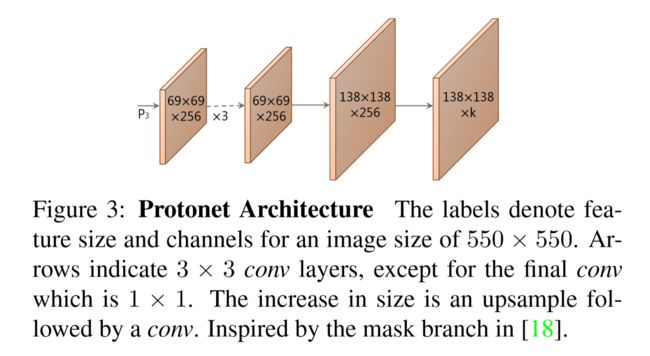
用于生成prototypes的Protonet分支为全卷积网络,在上一节说过,protonet选择了使用FPN的p3特征作为输入。特征深则鲁棒性好,特征图大则mask质量高且小目标精度好,想要特征图又深又大,所以作者选择了FPN。
正如上图,除了最后一个卷积为1×1,其他卷积都为3×3,使用ReLU作为激活函数,对于550×550的图像,最终会产生k个138×138的全局prototypes。 这种方法类似语义分割方法,但不同的是,没有对生成prototypes单独设置loss来惩罚,而是通过组成之后的loss来监督。
上图即为产生的prototypes,网络学习出产生的protoypes都有一些明显的功能,例如1-3是一些粗糙、隐式的一侧边界,4对图像下部一些对象做出了反应,5反映背景,6感知图像中的地面,等等。
另外,作者提到,因为有些prototype的功能是相近的,所以K=32就够用,而且k=32时效果就几乎饱和了,不会随着K的增加而增加,因为k变大,预测其cofficients也变的困难。
3.Cofficients
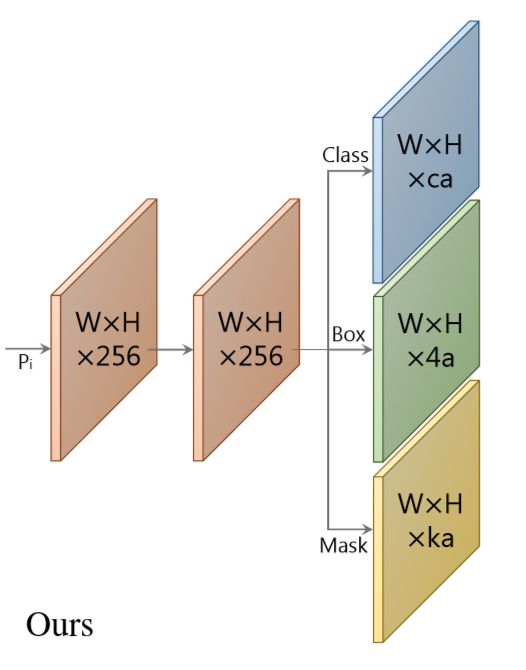
预测cofficients的分支,是在目标检测经典结构上增改而来的,原有框分类和回归的两个分支,YOLACT的head加入第三个分支来预测cofficients,每一个coofficient数值对应一个prototype,原本对于每个anchor预测的区域需要预测c+4个数,现在需要c+4+k个,图中的a为每个像素产生多少个anchor(对anchor不熟悉的可以去学习下fasterrcnn的论文),本文a=3。
简单来说就是,对于每个anchor的区域,产生k个系数(cofficients),每个系数对应一个prototype,即是最后通过线性运算组装这k个prototypes的每个prototype前面的系数。当然除此之外对于每个anchor还要产生分类及回归的系数。
具体来说,我们来详细计算一下参数:
输入的特征图先生成 anchor。每个像素点生成 3 个 anchor,比例是 1:1、1:2 和 2:1。五个特征图的 anchor 基本边长分别是 24、48、96、192 和 384。基本边长根据不同比例进行调整,确保 anchor 的面积相等。
上图是p3-p7其中某一个对应的head,每一个特征图分支都对应上图这样一个head结构。
接下来以 P3 为例,标记它的维度为 W3×H3×256,那么它的 anchor 数就是 a3 = W3×H3×3。接下来 Prediction Head 为其生成三类输出:
-
类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a3×81;
-
位置偏移,维度为 a3*4;
-
mask coefficient,维度为 a3*32。
对 P4-P7 进行的操作是相同的,最后将这些结果拼接起来,标记 a* = a3 + a4 + a5 + a6 + a7,得到:
- 全部类别置信。因为 COCO 中共有 81 类(包括背景),所以其维度为 a*×81;
- 全部位置偏移,维度为 a*×4;
- 全部 mask coefficient,维度为 a*×32。
4. InstanceMasks组装
得到prototypes和cofficients后我们使用如下公式实现线性组合以及非线性化——进行组装:
先矩阵相乘再对结果sigmoid。其中P是prototype masks矩阵,为h×w×k,C是n个在NMS(其实是作者提出的Fast NMS,为了介绍YOLACT思路流畅,我把FastNMS放在下一节介绍,这里可以先认为是NMS,作用是一样的)以及得分阈值存活下来的实例对应的cofficients矩阵,为n×k。结果M为h×w*n,即n个实例,每个都有一张h×w的全局结果。
最后剪切实例Masks,在训练时,使用groud truth的bounding box来切割;在验证时,使用预测的bounding box来切割。切割后根据设定的阈值,进行实例的二值化,将实例与背景分开。
loss fuction
其中前两项为框分类及回归的loss,使用了SSD中设计的loss function。最后一项关于Mask的loss本文设计为,是结果M与GroudTruth之间的pixel-wise二分类交叉熵,即:
计算时,是用ground truth的bounding box分成每个区域进行计算,以能够在prototype中保留小的物体。
5.Fast NMS
Fast NMS算法的操作,知乎Yang Xuangan的文章通过具体例子的方式讲解非常易懂:
经过本文第3节中Head网络,得到位置偏移后,可以通过 anchor 的位置加上位置偏移得到 RoI 位置。然后FastNMS(代替传统NMS)去掉冗余的ROI。
为了便于理解,下面依旧举例说明FastNMS。假设我们有 5 个 RoI,对于 person 这一类,按照置信度由高到低分别是 b1、b2、b3、b4 和 b5。接下来通过矩阵运算得出它们彼此之间的 IoU,假设结果如下:
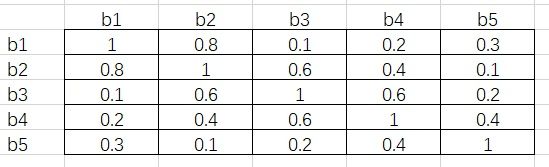
接下来将这个矩阵的下三角和对角线元素删去,得到下面的结果:

这其中的每一个元素都满足行号小于列号。接下来对每一列取最大值,得到 [-, 0.8, 0.6, 0.6, 0.4]。假设阈值为 0. 5,即 IoU 超过 0.5 的两个 RoI 需要舍弃掉置信度低的那一个。根据最大值,b2、b3 和 b4 对应的列都超出了阈值,所以这三个 RoI 会在这一步舍去。
这样做的原因是,由于每一个元素都是行号小于列号,而序号又是按照置信度从高到低降序排列的,因此任一元素大于阈值,代表着这一列对应的 RoI 与一个比它置信度高的 RoI 过于重叠了,需要将它舍去。
这里需要注意的是,b3 虽然和 b2 过于重叠(IoU 为 0.6),但 b3 与 b1 的 IoU 只有 0.1,而 b2 与 b1 的 IoU 为 0.8。按照传统 NMS 算法,b2 会在第一轮循环中被舍去,这样 b3 将会被保留。这也是 Fast NMS 与 NMS 不同的地方,即原文所述:we simply allow already-removed detections to suppress other detections, which is not possible in traditional NMS.

如上图所示,FastNMS用微弱的效果代价还换取了较大的速度提升。
6.代码 实验
文章比较新,官方开源代码就是pytorch1.0的,整体结构清晰明了,阅读学习、运行都可直接使用。我用ResNet101-FPN在COCO上训练,50epoch后准确率如下,速度为9.87fps?(2080Ti)
| all | .50 | .55 | .60 | .65 | .70 | .75 | .80 | .85 | .90 | .95 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| box | 31.63 | 51.22 | 48.92 | 46.01 | 42.76 | 38.77 | 33.46 | 27.19 | 18.76 | 8.15 | 1.03 |
| mask | 29.31 | 47.50 | 44.84 | 42.13 | 38.81 | 35.05 | 30.62 | 25.26 | 18.07 | 9.21 | 1.64 |
参考及引图:
https://openaccess.thecvf.com/content_ICCV_2019/papers/Bolya_YOLACT_Real-Time_Instance_Segmentation_ICCV_2019_paper.pdf
https://zhuanlan.zhihu.com/p/76470432
https://github.com/dbolya/yolact