《商务数据分析》读书笔记(六)
6.相似性,近邻,和聚类
基本概念:计算用数据描述的相似性; 用相似性预测;作为基于相似性分割的聚类
基本技巧:找到相似条目;最近邻方法;聚类理论;计算相似性的距离矩阵
相似性和距离
最近邻推理
例子:威士忌分析
最近邻预测模型
多少近邻和多大影响
几何解释,过拟合,和复杂度控制
最近邻理论的问题
关于相似性和近邻一些重要的技术细节
异质属性
*其他距离函数
*组合函数:从近邻计算分数
聚类
例子:重访威士忌分析
分层聚类
重访最近邻:围绕质心的聚类
例子:聚类商务新闻故事
理解聚类结果
*用监督学习生成聚类描述
退后一步:解决商务问题VS数据探索
总结
第六章 相似性,近邻和聚类
这一章讲了很多相似性的实际应用案例,也是我学习商业问题数据分析思路的好材料。
选择距离最近的几个样本点,综合它们的结果(用1/距离**2作为权重,它趋近于更小,甚至0),决定预测点的目标值。
权重计分减少了决定要用几个最近邻的重要性。因为加上了与距离平方呈倒数的权重,那些距离远的样本点的权重会大大降低,也就不用考虑太多。有些方法甚至k=n(全部样本数),因为它们使用权重来减少远距离点的影响。
几何解释,过拟合和复杂度控制
可视化模型很有教益,对于很多模型甚至不止本领域,可视化都有用。
KNN模型边界没有规律,反复无常,而且k越小,越厉害,对变化越敏感。k=1,模型最复杂。
联想之前提到的控制模型复杂度的通用方法,我们可以用交叉验证或是网状交叉验证(或说嵌套交叉验证)的方法,变换不同k值,来生成不同复杂度的模型,择优选用。
可理解性
在实际应用中,算法的可理解性非常重要。在医学和法律领域,KNN可以很好的给人解释。
但是在授权方面,KNN有他的局限,比如有个人申请抵押贷款,银行用了KNN,它不能给人答复“你的抵押申请被拒绝了,因为和你相似的一个人没有履行义务”!!!
KNN的特性就是解释性不强,所以,如果对算法有可理解性和辩护性(给别人解释为什么要用这个算法)的要求,KNN应该避免。
维度和域知识
KNN模型需要给特征值进行缩放,否则范围较大的特征值相当于有了更大的权重。涉及距离计算的时候,要特别注意这一点。
还有一个问题,是将不重要的特征考虑进去。
knn相对于其他模型必须进行特征选择,其他模型比如引入了惩罚函数的逻辑回归,在数值上避免了不相关特征的影响。
特征选择这个过程需要领域知识,不光是进行特征筛选,还可以用于手动添加不同模特征的权重。
计算效率
在生成模型的过程中,除了存储原始数据,基本不须计算耗费。但是在分类或预测的时候,需要耗费更多计算资源,如时间,因此,KNN对于需要快速决策的场合并不适合。比如线上购物决策。
一些关于相似性和近邻的重要技术细节
异质属性
欧几里得距离度量:
![]()
聚类
没有预先设定目标值的分组
聚类问题:
我们理解我们的客户是谁吗?
我们能开发更好的产品吗?
在数据中找到自然组分叫非监督分割,或聚类。
在数据探索中常常用到聚类。是为了对
某一个商务内容有一定的理解。
分级聚类 。
计算两两样本点之间的距离,最近的两个形成一类,然后将这一类当做一个样本点,如此迭代,直到最后所有样本都被分类为止。
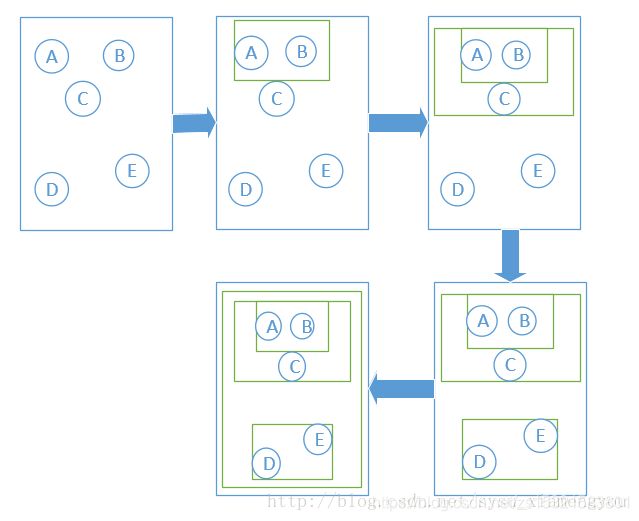
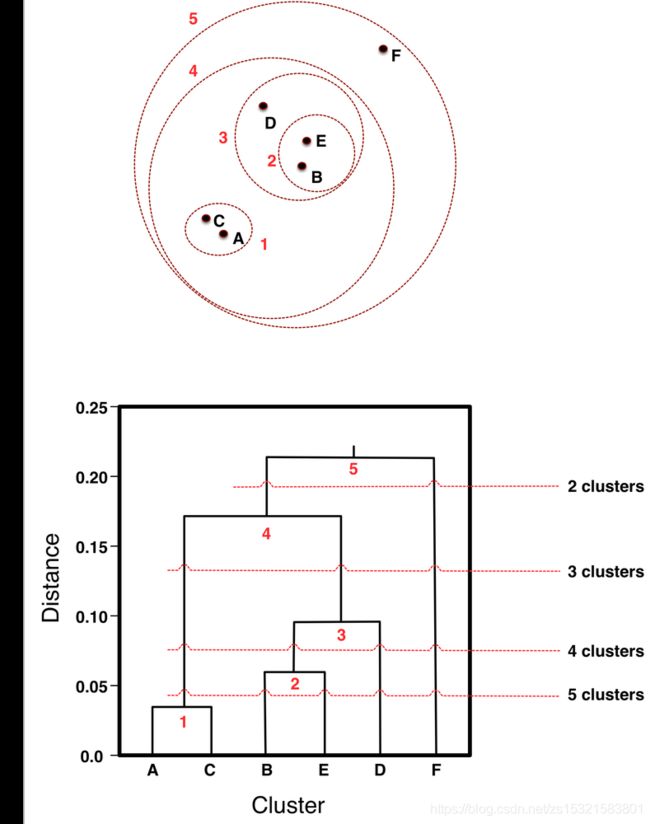
好处是可以允许分析师看到各个组分——数据相似性的地貌——在决定要从中抽取的聚类数目之前。可以选择几个分类。层级聚类可以输出dendrogram——系统树图。
基于质心的聚类:
最流行的基于质心的聚类是k均值聚类(k-means聚类)。
k意味着想找到多少个类,means意味着质心(因为质心是通过各个特征值平均找到的)。
1)从N个样本随机选取K个样本作为质心
2)对剩余的每个样本测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
至于计算时间,k均值算法效率很高,相对于层级聚类。
这里举了一个给大量新闻故事(文本)聚类的例子,其中涉及到文本挖掘,需要先看一下第十章。
K均值聚类常被用于前期数据探索。
比如本章举了一个例子,将大量的关于APPLE的新闻用k均值聚类分成9种。每种各进行一些描述。
其中有些很有趣,有些根本没任何意义。
统计中有一句话:有相关性不等于有因果性。
文本分析类似:句法相似不代表语义相似。
尽管如此,聚类仍然可以让我们提前看到隐藏的结构。聚类可以给我们提供新的有趣的数据挖掘的建议。
理解聚类的结果
聚类的结果或是系统树图或是几个样本群。我们能从中得到什么理解?这点很重要,因为我们经常用聚类进行数据探索。最重要的就是理解是否发现了某些新的东西,如果有,是什么?
方法之一是从集群中随机抽出几个看看。
做数据挖掘(事实上任何事情)之前,为了提高效率,要尽己所能的定义目标。
如果CRISP-DM展示的,我们应该为业务理解、数据理解小循环中,投入足够多的时间,知道我们有一个坚定的,具体的我们要解决的问题定义。
努力思考我们到底要什么东西,还有,反向思考,如果我们得到了自己想要的结果,我们就真的能够解决眼前的商务问题了吗?要先设定框架,然后再具体去试试,养成规划的习惯。
与此相比,非监督问题经常更具有探索性。我们有个概念如果我们能够给公司,新闻或威士忌聚类,我们能够更好地理解业务,因此能够改善些东西。然而,我们可能并没有准确的规划。但是这有一种平衡,如果在初始阶段我们没有在问题定义上投入足够多的时间,在评估阶段我们要花更多时间。(总之就是问题定义非常重要,如果你不知道自己要去哪儿,就永远无法成功到达)
对于聚类问题,评估阶段需要充分应用创造力和业务知识。
书中举了一个用聚类改善决策的例子:
他们聚类了GE资本现存的客户基于他们在信用卡,付账和账单上的相似性以及对公司的盈利能力。最终,他们将所有客户聚成5类(花得多还的多,花的多但是不按时还。。。)。对于不同类的客户,要设定不同的信用额度
这就是一个例子,他们用聚类找到了更好的进行精准预测的思路。
当然,总结聚类结果这个过程少不了业务知识。聚类结果反过来应用到了最初的信用额度划线决策中!
总结