文字检测算法CTPN网络模型及tensorflow版本代码介绍
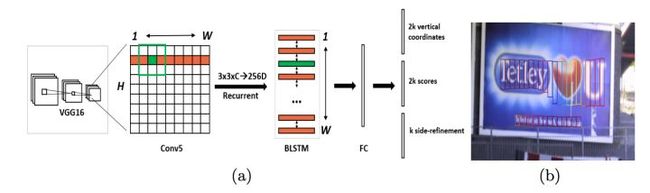
网络结构:
1、基础网络时VGG16,在conv5_3卷积之后的特征图上进行后续处理
2、在conv5_3的特征图之上,使用3x3的卷积核进行滑窗处理,这就是Faster R-CNN中使用的RPN网络
3、然后以特征图的行为单位,将每行内容分别输入到双向LSTM循环网络中,将双向循环网络的输出结果进行concat连接,每个LSTM输出的结果是128维向量,所以每个位置的输出结果是256维的向量,得到的特征图大小就是 H x W x 256
4、在特征图上的每个(h, w)的位置上,后面连接一个全连接层FC,其实也可以使用1x1的卷积层(Faster R-CNN中使用的就是1x1的卷积层),分别得到3个分支,第一个分支表示基于RPN网络在每个(h, w)位置上生成的k个anchor而预测得到的k个推荐框proposal是前景还是背景的得分,可以使用softmax实现,第二个分支表示基于RPN网络在每个(h, w)位置上生成的k个anchor而预测得到的k个推荐框proposal的高度以及proposal高度的中心位置,因为proposal的宽度是固定的16。
关于RPN网络的作用在我之前写的Faster R-CNN中RPN网络总结中有描述,简单总结一下就是,在RPN网络处理阶段,anchor的大小,坐标,以及anchor所属的label(anchor区域中是否包含目标)都是可以提前确定的,然后基于FC全连接层输出的预测结果计算损失函数,以anchor为基准点,使得训练后的模型预测结果更接近GT的真实结果。anchor的具体作用是为了尽量覆盖更多位置、更多尺度的目标,然后以anchor的位置和label为基准,训练模型参数,使得模型预测结果更接近真实值GT。
这里需要说明一下,有些人可能会疑惑,论文里明明白白的写了使用了全连接层FC,大家都知道全连接层要求输入的大小是固定的,而论文里面又说了CTPN实质上一个全卷积网络,可以处理任意大小的图片。问题的根本就在于虽然使用了全连接网络,但是全连接网络是作用于特征图的通道维度上的,特征图的通道维度是确定的,与输入图片的大小无关,所以CTPN可以处理任意大小的图片,其本质上也就是全卷积网络了。
tensorflow版本代码介绍,本篇代码来自于开源项目 text-detection-ctpn,遗憾的是项目中的百度网盘地址已经失效,没有获取到训练数据,训练过程还没跑通。
推理预测阶段:
1)、demo.py代码文件关键函数
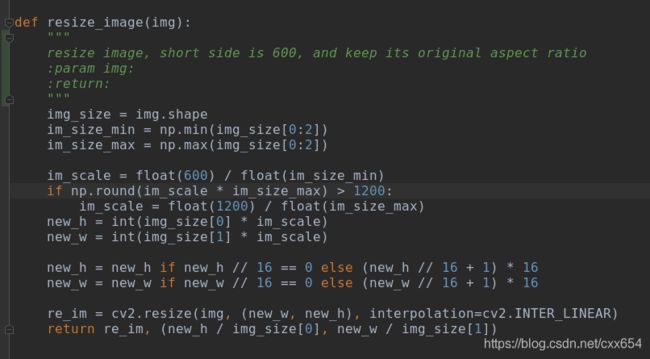
resize_image对输入的图片进行缩放,缩放后的图片短边为600,并保持图片的长宽比不变。
2)、model_train.py代码文件关键函数
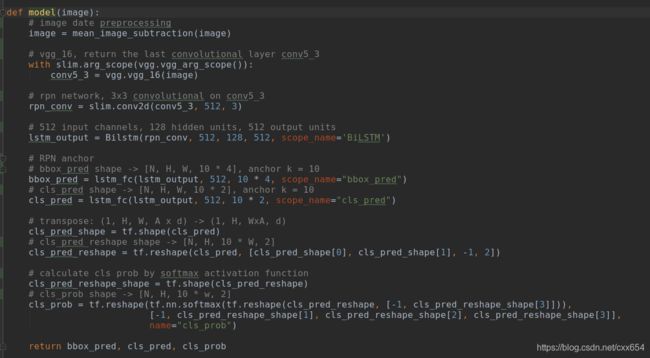
从model函数中可以明确的看到,模型在VGG16的基础上先进行了3x3的卷积操作,也就是RPN网络中的滑窗操作,然后将滑窗结果输入到双向LSTM。下面看一下双向LSTM中的操作。
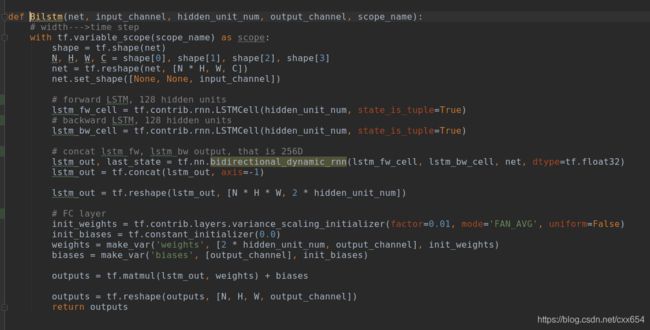
在双向LSTM函数中可以看到,net的形状是[N * H, W, C],其中N * H就是输入到LSTM的batch_size大小,W是输入序列的长度,C是每一步输入到LSTM中的数据维度,可以看到,每一步都是沿着W的方向,将通道C上的向量输入到LSTM中,然后将两个LSTM的输出结果进行连接。按照上面的描述,经过LSTM之后的输出结果要输入到FC全连接层,用于预测proposal的坐标和得分,也就是lstm_fc函数的功能。
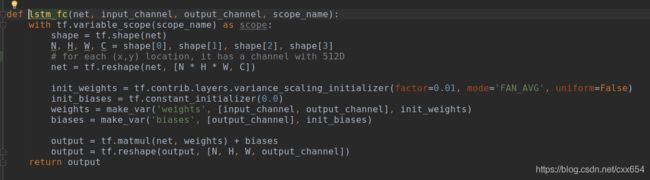
可以看到在lstm_fc函数中,分别在每个(h, w)位置的通道向量上进行FC操作,这也就是前面说的,CTPN中虽然使用了FC全连接层,但本质上仍是一个全卷积网络,因为这里的FC只和通道的大小有关系,与特征图的H和W无关。
在model函数的最后将lstm_fc函数的输出结果使用softmax函数转换为对应的前景和背景的概率。
3)、proposal_layer.py代码文件关键函数
proposal_layer函数用来计算基于RPN的预测结果以及生成的anchor坐标,计算RPN预测结果在最终图像上的坐标,然后对生成的proposal进行裁剪、过滤、NMS得到最终的proposal。
模型训练阶段:
前面粗略介绍了模型的正向推理过程,下面讲一下模型的训练过程。
1)、anchor_target_layer.py代码文件关键函数
anchor_target_layer函数的主要功能是在特征图上的每个位置生成10个anchor,并基于训练数据上的GT坐标位置计算与anchor IoU得到anchor的label。然后对生成的anchor进行筛选、过滤,最终保留128个positive anchor和128个negative anchor,如果positive anchor的数量太少,就是用negative anchor进行填充。
loss函数用来计算模型的损失函数:

从上面代码可以看到,对于分类分支使用交叉熵损失,对于坐标预测分支使用smooth_l1损失,tensorflow版本的代码中没有计算第三个分支。其中,对于分类分支的损失计算的是RPN预测的概率和anchor真是标签之间的损失,回归分支的损失计算的是RPN预测结果与anchor坐标的差异和GT与anchor坐标差异之间的损失。分类和回归损失的计算与Faster R-CNN中一致。
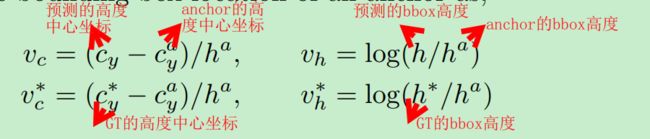

以上简单介绍了CTPN文字检测算法的模型,以及tensorflow版本的代码实现。要想深入理解算法的具体内容,还是要实地研究一下代码的具体实现。以上仅是个人的理解与观点,如有错误,欢迎指正。
道阻且长,加油吧!少年。