第一次作业
代码结构分析
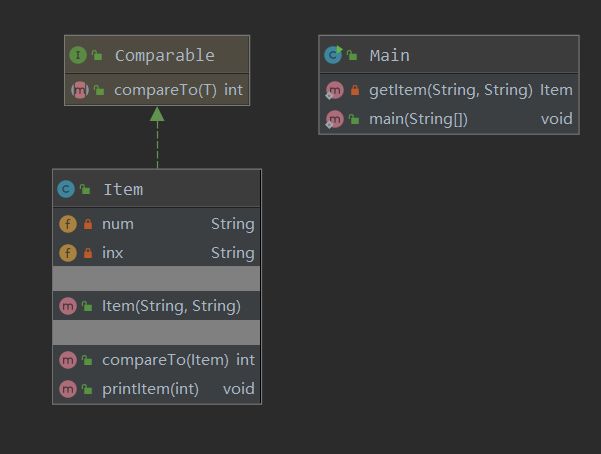
UML类图如下:
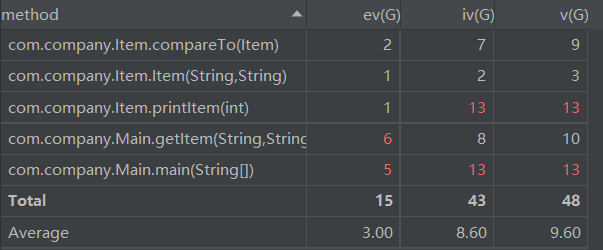
度量分析:
本次作业我的思路是先去除空格及其他空白字符,然后利用正则表达式读取每一项,再求导并存储在TreeSet中输出。
本次作业我只使用了两个类,主类和项类。可以看到我还停留在面向过程的思维当中,方法的耦合度和复杂度都很高,不利于测试和发现bug。
分析bug
在覆写compareTo方法的过程中,我犯了一个严重的错误。由于TreeSet是由二叉树实现的,所以compareTo函数返回的值会决定当前的元素是放在左子树还是右子树。在compareTo函数中,我用两个元素的指数来比较大小,这样可以保证相同指数的项会被合并。但问题是当指数不同时我选择比较两个项系数的大小(方便让正数项在第一位),这就导致了严重的问题。如果两项指数相同,有可能没法正常合并;如果系数相同,有可能丢失其中一项。
互测中发现bug
互测中我稍微阅读了一下其他同学的代码,发现有同学可能是提前写了之后的作业,但是没有注释掉格式判断的部分,导致输出了WF。
对象创建模式
本次作业我创建对象使用了getItem方法,本质上是先对输入的字符串进行判断(常数还是幂函数),然后直接返回求导的Item对象。但是缺点是复杂度比较高,出现bug很难发现。拓展性也一般,需要加比较多的判断条件。应该采用工厂模式比较好。
心得体会
要知其然还有知其所以然,要不然就有可能出现一些看起来莫名其妙的bug,其实就是自己的理解还不够,不知道一些操作是比较危险的,很容易出现问题。
第二次作业
代码结构分析
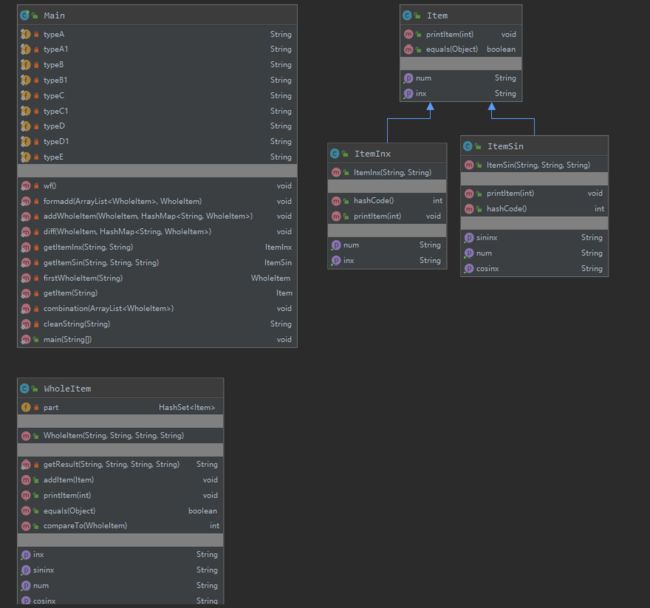
UML类图如下:
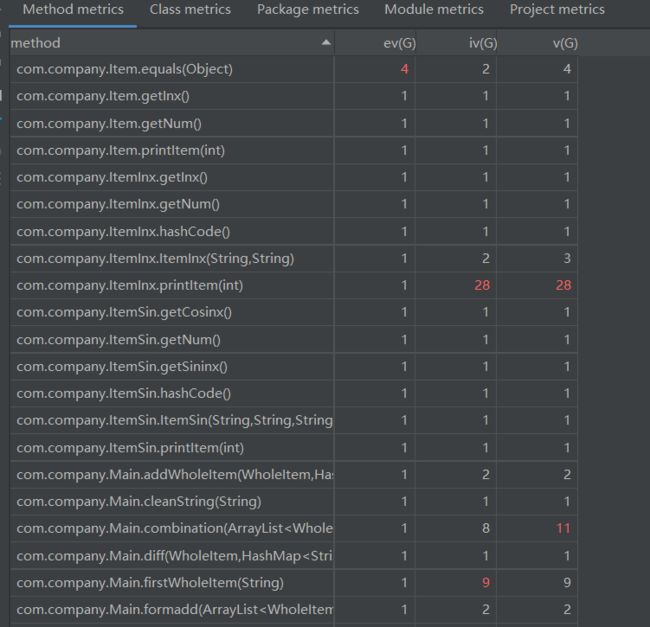
度量分析:
本次作业我为了方法的简洁性决定放弃拓展性。直接使用数学公式将每一项求导之后用hashMap合并。读入和判断的过程基本与上一次作业思路一致,增加了正则表达式的项。
本次作业的复杂度稍有进步,但还是有特别复杂的方法,需要改进。
分析bug
本次作业中指导书说明了不会因为空格字符的位置导致WF。但我误以为空格字符不会导致WF,所以直接去除了所有的空白字符。在强测中出现了非法字符应该输出WF而我的程序却正常运行了。
互测中我的程序出现了下标越界的异常。原因是我错误的在for循环遍历list的过程中remove了元素,这会导致list的长度变化导致越界。我在网上了解到,正确的方法是应该在使用迭代器遍历时才可以remove元素。
互测中发现bug
我使用了几个我自己出现过bug的数据提交,发现有同学没有对连续的三个符号进行处理,直接抛出了异常。
对象创建模式
本次作业我对对象创建模式进行了优化,尝试使用了工厂模式,并将细节的对象创建另外建立了方法,使用起来比较方便,也很容易添加创建的对象。
心得体会
这次的作业让我认识到仔细阅读指导书的重要性,如果没有清晰明了的掌握了需求,那么就不可能写出令人满意的程序。
第三次作业
代码结构分析
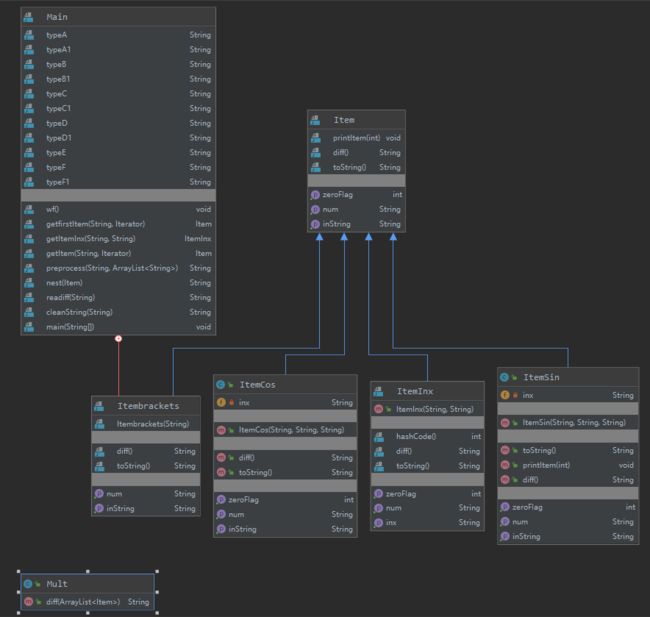
UML类图如下:
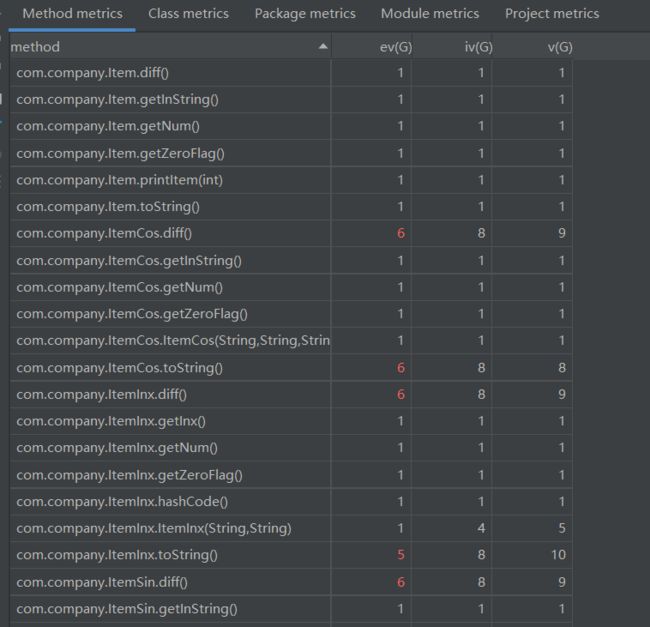
度量分析:
本次作业由于要实现递归,所以除了输入处理和判断之外的部分全部重构了。总体思路是将每一种项建立一个类,实现求导方法,最后由一个统一的父类来管理并输出结果。
可以看到某些方法的复杂度还是有些高,但是不会出现特别高的类了。
分析bug
我在本次作业判断WF的方式是如果某一段字符不匹配任何的正则表达式就说明格式错误。但是由于我的疏忽,漏掉了一个空格,导致括号内的空格前如果有数字就报WF形成了bug。
互测中发现bug
经过学习网上其他人的代码,我也搭建了一个微型的评测机,使用评测机找出了同学们一些bug,同学们的问题主要出现在优化和WF上,有些同学多判断了WF,还有的同学优化出现了纰漏,将不该优化的地方优化掉了,导致输出结果出现了括号里什么都没有的情况。
对象创建模式
本次作业在上一次的基础上添加了几个新类就可以正常使用getItem方法了,说明工厂模式的可拓展性比较好。
心得体会
我觉得本次作业难度上确实比较高,这也使我意识到了良好的代码结构会使程序构建和debug事半功倍。