【Tensorflow】LeNet-5训练MNIST数据集
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。根据其他博客,利用MNIST训练LeNet-5网络,并做了测试。
目录
1.LeNet-5网络
2.LeNet-5代码
3.测试结果
代码地址
1.LeNet-5网络
1.1 网络结构

1.2 各层详解
-
输入层
输入图像尺寸归一化为32*32
-
C1层---卷积层
输入:32*32
kernel:5*5
卷积核个数:6
输出:28*28 [strip = 1,no padding,(32-5)/ 1 +1 = 28]
神经元数量:28*28*6
可训练参数:(5*5+1)*6(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器)
连接数:(5*5+1)*6*28*28
详细说明:对输入图像进行第一次卷积运算(使用 6 个大小为 5*5 的卷积核),得到6个C1特征图(6个大小为28*28的 feature maps, 32-5+1=28)。我们再来看看需要多少个参数,卷积核的大小为5*5,总共就有6*(5*5+1)=156个参数,其中+1是表示一个核有一个bias。对于卷积层C1,C1内的每个像素都与输入图像中的5*5个像素和1个bias有连接,所以总共有156*28*28=122304个连接(connection)。有122304个连接,但是我们只需要学习156个参数,主要是通过权值共享实现的。
-
S2层---下采样层(池化)
输入:28*28
kernel:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
kernel个数:6
输出:14*14(28/2 * 28/2)
神经元数量:14*14*6
可训练参数:2*6(和的权+偏置)
连接数:(2*2+1)*6*14*14
详细说明:第一次卷积之后紧接着就是池化运算,使用 2*2核 进行池化,于是得到了S2,6个14*14的 特征图(28/2=14)。S2这个pooling层是对C1中的2*2区域内的像素求和乘以一个权值系数再加上一个偏置,然后将这个结果再做一次映射。于是每个池化核有两个训练参数,所以共有2x6=12个训练参数,但是有5x14x14x6=5880个连接。
-
C3层---卷积层
输入:14*14 S2中所有6个或者几个特征map组合
kernel:5*5
卷积核种类:16
输出:10*10 [(14 - 5)/ 1 +1 = 10]
C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合
存在的一个方式是:C3的前6个特征图以S2中3个相邻的特征图子集为输入。接下来6个特征图以S2中4个相邻特征图子集为输入。然后的3个以不相邻的4个特征图子集为输入。最后一个将S2中所有特征图为输入。
则:可训练参数:6*(3*25+1)+6*(4*25+1)+3*(4*25+1)+(25*6+1)=1516【个人理解:3*5*5+1个bias】
连接数:10*10*1516=151600
详细说明:第一次池化之后是第二次卷积,第二次卷积的输出是C3,16个10x10的特征图,卷积核大小是 5*5. 我们知道S2 有6个 14*14 的特征图,怎么从6 个特征图得到 16个特征图了? 这里是通过对S2 的特征图特殊组合计算得到的16个特征图。具体如下:
C3的前6个feature map(对应上图第一个红框的6列)与S2层相连的3个feature map相连接(上图第一个红框),后面6个feature map与S2层相连的4个feature map相连接(上图第二个红框),后面3个feature map与S2层部分不相连的4个feature map相连接,最后一个与S2层的所有feature map相连。卷积核大小依然为5*5,所以总共有6*(3*5*5+1)+6*(4*5*5+1)+3*(4*5*5+1)+1*(6*5*5+1)=1516个参数。而图像大小为10*10,所以共有151600个连接。
C3与S2中前3个图相连的卷积结构如下图所示:
上图对应的参数为 3*5*5+1,一共进行6次卷积得到6个特征图,所以有6*(3*5*5+1)参数。 为什么采用上述这样的组合了?论文中说有两个原因:1)减少参数,2)这种不对称的组合连接的方式有利于提取多种组合特征。
-
S4层---池化层
输入:10*10
kernel:2*2
采样方式:4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid
采样种类:16
输出featureMap大小:5*5(10/2)
神经元数量:5*5*16=400
可训练参数:2*16=32(和的权+偏置)
连接数:16*(2*2+1)*5*5=2000
详细说明:S4是pooling层,窗口大小仍然是2*2,共计16个feature map,C3层的16个10x10的图分别进行以2x2为单位的池化得到16个5x5的特征图。这一层有2x16共32个训练参数,5x5x5x16=2000个连接。连接的方式与S2层类似。
-
C5层---卷积层
输入:5*5 S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类:120
输出featureMap大小:1*1(5-5)/1 + 1
可训练参数/连接:120*(16*5*5+1)=48120
详细说明:C5层是一个卷积层。由于S4层的16个图的大小为5x5,与卷积核的大小相同,所以卷积后形成的图的大小为1x1。这里形成120个卷积结果。每个都与上一层的16个图相连。所以共有(5x5x16+1)x120 = 48120个参数,同样有48120个连接。C5层的网络结构如下:
-
F6层---全连接层
输入:1*1 C5 120维向量
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数
可训练参数:84*(120+1)=10164
详细说明:6层是全连接层。F6层有84个节点,对应于一个7x12的比特图,-1表示白色,1表示黑色,这样每个符号的比特图的黑白色就对应于一个编码。该层的训练参数和连接数是(120 + 1)x84=10164。ASCII编码图如下:
F6层的连接方式如下:
-
输出层---全连接层
2.LeNet-5代码
2.1 部分注解
# padding mnist 28x28->32x32
def mnist_reshape_32(_batch):
batch = np.reshape(_batch,[-1,28,28])
num = batch.shape[0]
batch_32 = np.array(np.random.rand(num,32,32),dtype=np.float32)
for i in range(num):
batch_32[i] = np.pad(batch[i],2,'constant',constant_values=0)
return batch_32MNIST数据集大小为28x28,LeNet-5网络输入图像全部归一化为32x32,本文没有修改网络结构,直接对MNIST数据pad为32x32.
- 原文第五层输入是5*5*16的featuremap,该层卷积核为5x5,所以相当于一个全连接层。
- loss中加入正则项,避免过拟合
tf.add_to_collection('losses', _reg(fc5_weight))2.2 完整代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
from PIL import Image
WIDTH = 32
HEIGHT = 32
training_epochs = 20000
training_batch = 32
display_step = 50
test_step = 100
mnist = input_data.read_data_sets('../MNIST_data/',one_hot=True)
x_test = mnist.test.images
y_test = mnist.test.labels
xs = tf.placeholder(tf.float32,[None,WIDTH,HEIGHT],name='x_data')
ys = tf.placeholder(tf.float32,[None,10],name='y_data')
keep_prob = tf.placeholder(tf.float32,name='keep_prob')
def weight_variable(shape, name):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=name)
def bias_variable(shape, name):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=name)
# x:输入 W:权重
def conv2d(x, W, padding):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=padding)
def relu_bias(x,bias,name):
return tf.nn.relu(tf.nn.bias_add(x,bias),name=name)
# x:输入
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def inference(_input,_reg):
x_data = tf.reshape(_input,[-1,32,32,1])
# 第一层:卷积层,过滤器的尺寸为5×5,深度为6,不使用全0补充,步长为1。
# 尺寸变化:32×32×1->28×28×6
with tf.variable_scope('Layer1_Conv'):
conv1_weight = weight_variable([5,5,1,6],'conv1_weight')
tf.summary.histogram('Layer1_Conv/weights',conv1_weight)
conv1_bias = bias_variable([6],'conv1_bias')
tf.summary.histogram('Layer1_Conv/biases', conv1_bias)
conv1 = conv2d(x_data,conv1_weight,'VALID')
conv1_relu = relu_bias(conv1,conv1_bias,'conv1_relu')
tf.summary.histogram('Layer1_Conv/output', conv1_relu)
# 第二层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
# 尺寸变化:28×28×6->14×14×6
with tf.name_scope('Layer2_Pooling'):
pool2 = max_pool_2x2(conv1_relu)
tf.summary.histogram('Layer2_Pooling/output', pool2)
# 第三层:卷积层,过滤器的尺寸为5×5,深度为16,不使用全0补充,步长为1。
# 尺寸变化:14×14×6->10×10×16
with tf.variable_scope('Layer3_Conv'):
conv3_weight = weight_variable([5, 5, 6, 16], 'conv3_weight')
tf.summary.histogram('Layer3_Conv/weights', conv3_weight)
conv3_bias = bias_variable([16], 'conv2_bias')
tf.summary.histogram('Layer3_Conv/biases', conv3_bias)
conv3 = conv2d(pool2, conv3_weight, 'VALID')
conv3_relu = relu_bias(conv3, conv3_bias, 'conv3_relu')
tf.summary.histogram('Layer3_Conv/output', conv3_relu)
# 第四层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
# 尺寸变化:10×10×6->5×5×16
with tf.variable_scope('Layer4_Pooling'):
pool4 = max_pool_2x2(conv3_relu)
tf.summary.histogram('Layer4_Pooling/output', pool4)
# 原文第五层是5*5的卷积层,因为输入是5*5*16的map,所以这里即相当于一个全连接层。
# 5×5×16->1 x 400
pool4_shape = pool4.get_shape().as_list()
size = pool4_shape[1] * pool4_shape[2] * pool4_shape[3]
pool4_reshape = tf.reshape(pool4,[-1,size])
# 第五层:全连接层,nodes=5×5×16=400,400->120的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×400->64×120
# 训练时,引入dropout,dropout在训练时会随机将部分节点的输出改为0,dropout可以避免过拟合问题。
# 这和模型越简单越不容易过拟合思想一致,和正则化限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声,以此达到避免过拟合思想一致。
with tf.variable_scope('Layer5_FC'):
fc5_weight = weight_variable([size,120],'fc5_weight')
tf.summary.histogram('Layer5_FC/weights', fc5_weight)
fc5_bias = bias_variable([120],'fc5_bias')
tf.summary.histogram('Layer5_FC/biases', fc5_bias)
if _reg != None:
tf.add_to_collection('losses', _reg(fc5_weight))
fc5 = tf.matmul(pool4_reshape,fc5_weight)
fc5_relu = relu_bias(fc5,fc5_bias,'fc5_relu')
fc5_relu = tf.nn.dropout(fc5_relu, keep_prob)
tf.summary.histogram('Layer5_FC/output', fc5_relu)
# 第六层:全连接层,120->84的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×120->64×84
with tf.variable_scope('Layer6_FC'):
fc6_weight = weight_variable([120, 84], 'fc6_weight')
tf.summary.histogram('Layer6_FC/weights', fc6_weight)
fc6_bias = bias_variable([84], 'fc6_bias')
tf.summary.histogram('Layer6_FC/biases', fc6_bias)
if _reg != None:
tf.add_to_collection('losses', _reg(fc6_weight))
fc6 = tf.matmul(fc5_relu, fc6_weight)
fc6_relu = relu_bias(fc6, fc6_bias,'fc6_relu')
fc6_relu = tf.nn.dropout(fc6_relu, keep_prob)
tf.summary.histogram('Layer6_FC/output', fc6_relu)
# 第七层:全连接层(近似表示),84->10的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×84->64×10。最后,64×10的矩阵经过softmax之后就得出了64张图片分类于每种数字的概率,
# 即得到最后的分类结果。
with tf.variable_scope('Layer7_FC'):
fc7_weight = weight_variable([84, 10], 'fc7_weight')
tf.summary.histogram('Layer7_FC/weights', fc7_weight)
fc7_bias = bias_variable([10], 'fc7_bias')
tf.summary.histogram('Layer7_FC/biases', fc7_bias)
if _reg != None:
tf.add_to_collection('losses', _reg(fc7_weight))
result = tf.matmul(fc6_relu, fc7_weight) + fc7_bias
tf.summary.histogram('Layer7_FC/output', result)
return result
# padding mnist 28x28->32x32
def mnist_reshape_32(_batch):
batch = np.reshape(_batch,[-1,28,28])
num = batch.shape[0]
batch_32 = np.array(np.random.rand(num,32,32),dtype=np.float32)
for i in range(num):
batch_32[i] = np.pad(batch[i],2,'constant',constant_values=0)
return batch_32
regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = inference(xs,regularizer)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=tf.argmax(ys,1))
with tf.name_scope('loss'):
loss = tf.reduce_mean(cross_entropy) + tf.add_n(tf.get_collection('losses'))
tf.summary.scalar('loss',loss)
with tf.name_scope('loss'):
train_step = tf.train.GradientDescentOptimizer(.01).minimize(loss)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init = tf.global_variables_initializer()
x_test_32 = mnist_reshape_32(x_test)
with tf.Session() as sess:
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('logs/', sess.graph)
sess.run(init)
for i in range(training_epochs):
batch_xs, batch_ys = mnist.train.next_batch(training_batch) # 28x28
batch_xs_32 = mnist_reshape_32(batch_xs)
sess.run(train_step,feed_dict={xs:batch_xs_32,ys:batch_ys,keep_prob:.3})
if i % display_step == 0:
print('---------------step:%d, training accuracy:%g--------------' % (i, sess.run(accuracy,feed_dict={
xs: batch_xs_32, ys: batch_ys, keep_prob: 1.0})))
rs = sess.run(merged,feed_dict={xs: batch_xs_32, ys: batch_ys, keep_prob: 1.0})
writer.add_summary(rs,i)
if i % test_step == 0:
print("test accuracy %g" % sess.run(accuracy, feed_dict={
xs: x_test_32, ys: y_test, keep_prob: 1.0}))
print('---------------step:%d, training accuracy:%g--------------' % (i, sess.run(accuracy, feed_dict={
xs: batch_xs_32, ys: batch_ys, keep_prob: 1.0})))3.测试结果
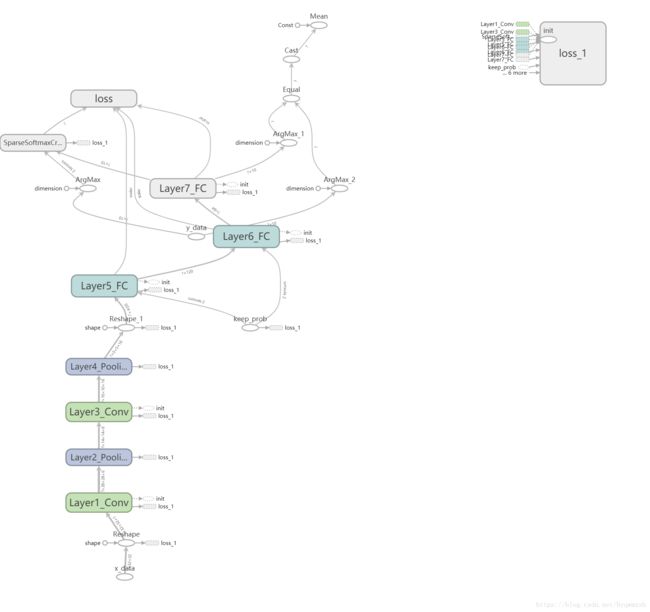
网络结构图:
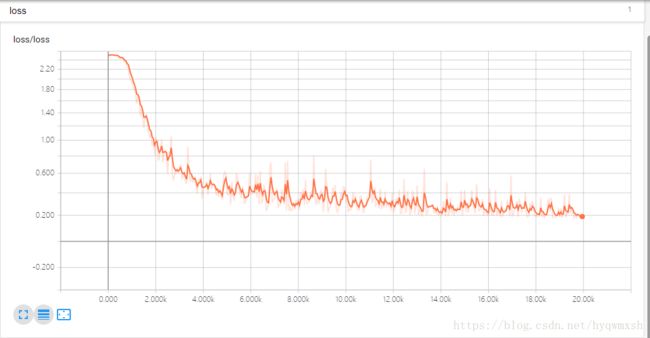
loss:
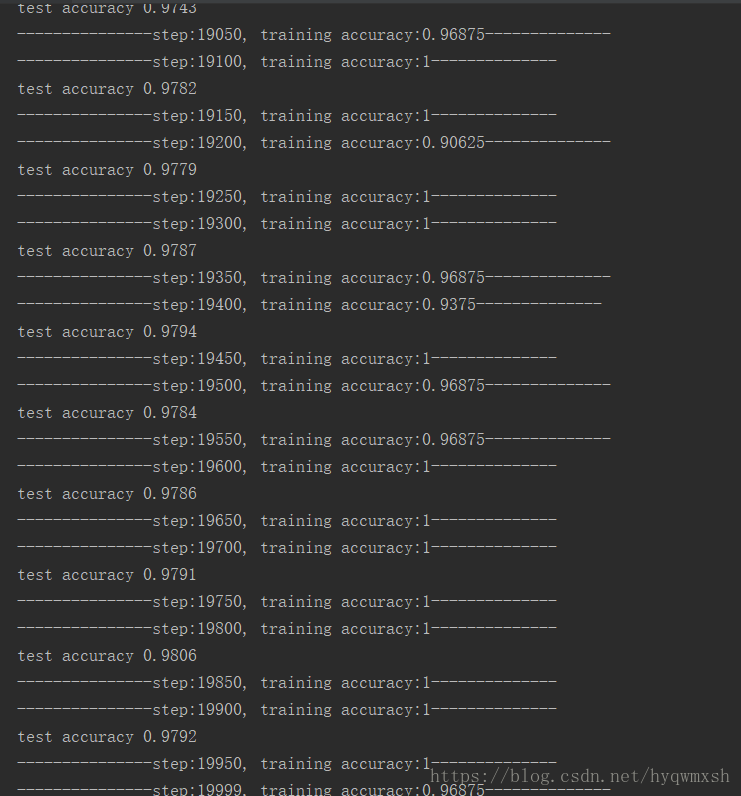
~~还在入门学习中,水平有限,如有错误请指正,谢谢~~
参考链接:
https://blog.csdn.net/enchanted_zhouh/article/details/76855108
http://cuijiahua.com/blog/2018/01/dl_3.html