2-4、模型选择
目录
- 一、将数据集拆分为训练/测试集(一次)
- 二、交叉验证生成器:K折交叉验证时的数据集索引拆分方法
- 1、K折交叉验证抽样
- 2、指定次数重复K折交叉验证抽样
- 3、分层K折交叉验证抽样
- 4、有放回抽样(自助法抽样Boot Strapping)
- 三、交叉验证
- 1、获取得分
- 2、进行预测
- 3、进行交叉验证(可获得每折的具体结果)
- 4、通过交叉验证计算学习曲线(判断欠拟合/过拟合)
- 4-2、验证曲线(通过网格搜索超参数得出学习曲线)
- 5、网格搜索:通过设置参数字典进行交叉验证(用于调参)
在调参过程中,由于是根据测试集测试模型效果的,因此测试集的信息会泄露进模型,从而使得模型效果变好:
方法一:应该单独取一数据集作预测来查看预测(模型)的效果。即训练集做训练(训练模型)、评价集选模型(通过得分评价模型挑选出一个模型中最合适的参数)、测试集检验结果(对参数最佳的多种模型进行选择,从而得到最佳模型)。
方法二:将训练集做训练、评价集选模型合为一个,做交叉验证(如网格搜索)来获得一个模型的最佳参数;用测试集选择不同模型中最佳者。但不是绝对意义的,有时直接将数据集分为训练和测试集进行建模效果可能更好,尤其是样本量较少时。
1、拆分数据集为训练集和测试集,训练集用于训练模型参数,测试集用于预测并评价模型效果(得分)。
2、用训练集进行建模,获取参数估计。
3、用测试集进行预测,获取得分,从而进行模型评价。
4、也可以通过K折交叉验证,用测试集建模的同时获取模型评价(通常5折即可),用于比较不同模型的优劣。然后再用测试集合查看预测效果,确定一个模型的最佳效果。
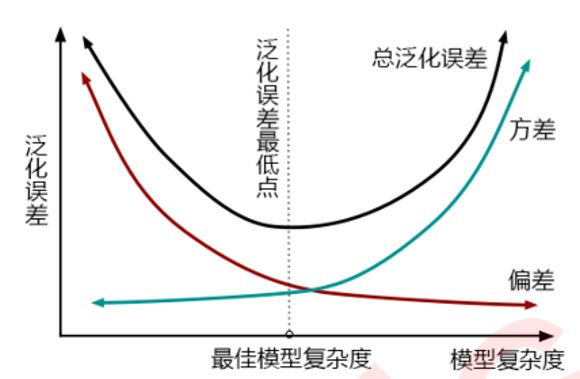
选择模型,最终是选择一个泛化误差最小的模型
from sklearn import model_selection一、将数据集拆分为训练/测试集(一次)
抽样时要尽可能保持数据分布的一致性,避免引入额外的偏差。
X_train, X_test, y_train, y_test = model_selection.train_test_split(data, target, test_size, train_size,
random_state, shuffle, stratify)将列表、数组、矩阵或DataFrame随机拆分为训练集和测试集构成的元组(X_train, X_test, y_train, y_test)(若输入是稀疏的则返回scipy.sparse.csr_matrix,否则数据类型同输入)。
data、target是位置参数,分别为特征数组或矩阵、目标数组后矩阵。test_size指定测试集的大小,小数则表示占比,整数表示样本量,缺失默认0.25。train_size指定训练集的大小。random_state指定随机数种子。shuffle是否在拆分前先打乱原数据,为False时stratify必须为None。stratify是用来标识分层的数组作为分层抽样依据,为None时将按顺序拆分为训练和测试集。
一般将训练样本和测试样本分为8:2或7:3。更好的方式是将数据分为3份:训练集:交叉验证数据集:测试集=6:2:2(交叉验证数据集用于选择模型,测试集用于测试准确性,使选择模型与评价预测性能分开)。
二、交叉验证生成器:K折交叉验证时的数据集索引拆分方法
仅实例化(未考虑数据分布),需用split()返回**(训练集索引, 测试集索引)**构成的生成器。也可直接作为交叉验证的cv参数值。k折交叉验证会导致性能下降,通常选择k有3、5、10。对于复杂模型(数据较多,百万条以上)可以直接用单次拆分训练/测试集建模(大数据量下样本的变化基本不会引起模型的变化),但小样本下不同。
通常是现将数据分为训练和测试集,在训练集上再用交叉验证选择最优模型。只用用测试集作为真正的测试。
1、K折交叉验证抽样
将数据拆分为k份(尽可能均分),每次取一份做测试集,其余做训练集。通常用于回归或者样本相对均衡的数据。
model_selection.KFold(n_splits=3, shuffle=False, random_state=None)返回(train_idx, test_idx)构成的索引迭代器。将数据集通过索引连续的(不分层)拆分成训练集/测试集,之后在交叉验证中每次取一折作为测试样本,其余作为训练样本。
n_splits指定数据集拆分次数(K折)。shuffle是否在拆分前分层。random_state随机种子。
方法:split(X, y=None, groups=None)对X、y进行抽样拆分,返回(train_idx, test_idx)构成的索引迭代器,每个元素都是一个索引构成的列表,整体是从0开始的,只是大小同样本量。groups指定样本对应的组,用于抽样。
get_n_splits()获取交叉验证的折次。同n_splits。
2、指定次数重复K折交叉验证抽样
对数据重复指定次数的k折交叉验证,避免一次K折交叉验证中可能因抽样使样本分布发生变化的缺陷。
model_selection.RepeatedKFold(n_splits=5, n_repeats=10, random_state=None)n_splits指定拆分次数(K折)。n_repeats指定重复k折交叉验证的次数。
3、分层K折交叉验证抽样
根据标签各水平值的比例,对数据进行分层K折交叉验证抽样交,从而保持数据中各类别的比例和原始数据一致。是K折交叉验证的变种,通常用于分类任务,尤其是类别不均衡时,从而保持原数据特性。
model_selection.StratifiedKFold(n_splits=3, shuffle=False, random_state=None)n_splits指定拆分次数(K折)。shuffle指定是否分层。
4、有放回抽样(自助法抽样Boot Strapping)
有放回地采集m个样本(样本可以出现多次,也可以一次也出现)。样本始终不出现的概率为 l i m ( 1 − 1 m ) m − > 1 e = 0.368 lim(1-\frac{1}{m})^m -> \frac{1}{e}=0.368 lim(1−m1)m−>e1=0.368,即在多次抽样后有36.8%(1/3)的样本从未被抽到。因此可以将抽到的样本作为训练集,为抽到的样本做测试集,从而确保在尽可能使用全样本的情况下又能有新样本做测试使用。
将数据按指定大小的训练集拆分k次,数据拆分是有放回的,即本次拆分后,下次重新从初始状态拆分。
model_selection.ShuffleSplit(n_splits=10, test_size="default", train_size=None, random_state=None)n_splits指定数据集拆分次数(K折)。test_size、train_size指定测试集占样本量的比例或测试集大小。random_state随机种子。
方法:split(X)对数组拆分,返回(train_index, test_index)构成的索引(源数据中位置)生成器。
get_n_splits(X)返回对数组X进行的拆分次数。
三、交叉验证
1、获取得分
model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1,
verbose=0, fit_params=None, pre_dispatch="2*n_jobs")返回每折运算得分结果构成的数组。值都是负值(前边加负号即可)。
estimator是模拟器,即执行fit()和predict()方法的对象。X是特征数组。y是标签数组。groups是因变量的分组标签变量(数组),用于将数据分为训练集/测试集。scoring计算得分的函数名称(metrics中的方法名,如"f1_macro"、"accuracy"等)或可调用对象(用metrics.make_scorer(函数)生成)。cv指定进行k折交叉验证,可以是None(3折交叉验证)、整数、一个拆分数据集的实例化对象(KFold()、ShuffleSplit())、一个生成训练/测试集的可迭代对象;对None、整数若模拟器是分类器且y是分类变量则用StratifiedKFold方法,否则用KFold方法。n_jobs指定使用CPU核数。verbose控制显示程度。fit_params以字典形式传递给模拟器的predict()方法的参数。pre_dispatch用于控制并行运算。
2、进行预测
model_selection.cross_val_predict(estimator, X, y=None, groups=None, cv=None, n_jobs=1, verbose=0,
fit_params=None, pre_dispatch='2*n_jobs', method='predict') 返回各样本在每折交叉预测结果的最终合成(投票?)后的结果数组。用于做误差分析,减小因样本变化对模型的影响
estimator是模拟器,即执行fit()和predict()方法的对象。X是特征数组。y是标签数组。groups是因变量的分组标签变量(数组),用于将数据分为训练集/测试集。cv指定进行k折交叉验证,可以是None(3折交叉验证)、整数、一个拆分数据集的实例化对象(KFold()、ShuffleSplit())、一个生成训练/测试集的可迭代对象;对None、整数若模拟器是分类器且y是分类变量则用KFold方法,否则用KFold方法。n_jobs指定使用CPU核数。verbose控制显示程度。fit_params以字典形式传递给模拟器的参数。pre_dispatch指定分发的最多任务数,超出的将被杀死。method指定传递给模拟器的方法名称,有"predict"、“predict_proba”、“predict_log_proba”、“decision_function”(对排序后的因变量)。
3、进行交叉验证(可获得每折的具体结果)
model_selection.cross_validate(estimator, X, y=None, groups=None, scoring=None, cv=’warn’, n_jobs=None, verbose=0, fit_params=None, pre_dispatch=‘2*n_jobs’, return_train_score=’warn’, return_estimator=False, error_score=’raise-deprecating’)返回字典,键是test_score(测试集得分)、train_score(训练集的分)、fit_time(拟合时间)、score_time(计算得分时间)、estimator,对应的值是每折的建模结果。
groups指定用分层抽样时所依据的数据。scoring指定计算得分的方法名称或函数(只能返回一个值),可以通过列表、字典或列表得到多个得分,None用拟合器自身的得分计算方法。cv指定交叉验证的折次(为整数或None且是分类拟合器,则用StratifiedKFold分层抽样,否则用KFold)或自定义的样本拆分实例。fit_params指定拟合器的参数字典。return_train是否返回交叉训练时训练集的得分,默认warn同True。return_estimator是否返回各折交叉验证所拟合到的模型。error_score指定计算得分出错时的默认值,"raise"产生异常并终止、"raise-deprecating"会在产生异常通告FurtureWarning;对refit步无效。
4、通过交叉验证计算学习曲线(判断欠拟合/过拟合)
2、对高偏差和地方插的处理方法:1)增加特征以降低偏差;2)减少正则化以降低偏差,但会提高方差
1、判断方法:
1)检测训练集和测试集学习曲线间的间隔: 间 隔 = 测 试 误 差 − 训 练 误 差 间隔=测试误差-训练误差 间隔=测试误差−训练误差,间隔越大,方差越大。
2)查看训练集误差及变化:若算法方差很小,则改变数据集时所产生的变化也较小。训练集方差较小,间隔很大,则可能过拟合。
3)若随样本量增加,训练集误差减少和测试集误差增加,则增加数据量有助于提高模型。

model_selection.learning_curve(estimator, X, y, groups=None, train_sizes=np.array([0.1, 0.325, 0.55, 0.775, 1.]),
cv=None, scoring=None, exploit_incremental_learning=False, n_jobs=1,
pre_dispatch="all", verbose=0, shuffle=False, random_state=None) 返回数组构成的元组(训练集大小列表, 训练集得分数组(每行是一次数据拆分对应的交叉验证的得分), 测试集得分数组(每行是一次数据拆分对应的交叉验证的得分)),用于反映训练集和测试集得分随训练集大小变化的情况,从而判断高偏差(欠拟合)还是高方差(过拟合)。
estimator是模型估计器(有fit()和predict()方法)。X是样本特征数组。y是目标变量(对非监督模型是None)。groups是长度同样本量的数组,用于对样本进行分组。train_sizes是各次取的训练集样本量占总样本的比例,整数时为具体样本量,用于生成学习曲线数据(之后再进行k折交叉验证)。cv指定交叉验证的次数(K折交叉验证,默认3),或是用于交叉验证拆分数据的生成器(如ShuffleSplit())、产生训练/测试集的生成器(train_test_split())(若模型是分类器,且y是二分类或多分类,则用StratifiedKFold,否则用KFold)。scoring指定计算得分方法的字符串或函数,也可以是None。exploit_incremental_learning若模型支持增量学习,则可设为True加快学习速度。n_jobs指定并行计算任务量。pre_dispatch。verbose指定显示的信息级别,整数值越大信息越多。shuffle是否在指定训练集大小基础上进行分层抽样。random_state指定随机种子。
可以结合学习曲线(对同一参数的不同值作为x轴,得分作为y轴)选择一个参数的最佳值。根据 泛 化 误 差 = b i a s 2 + v a r + ϵ 2 泛化误差=bias^2+var+\epsilon^2 泛化误差=bias2+var+ϵ2(对回归,bias就是(1-R方)),通过得分选择模型主要是在模型相对稳定时考虑偏差,若模型不稳定(尤其数据量少时),可将方差也考虑进去,即以泛化误差中可控部分 b i a s 2 + v a r bias^2+var bias2+var作为y轴制作学习曲线:通过交叉验证获取每个参数值对应得分的均值和方差,再将得分转换为偏差bias,如对回归是 ( 1 − R 2 ) 2 + v a r s (1-R^2)^2+vars (1−R2)2+vars
4-2、验证曲线(通过网格搜索超参数得出学习曲线)
model_selection.validation_curve(estimator, x, y, param_name, param_range, groups=None, cv=None, scoring=None, n_jobs=None, pre_dispatch="all", verbose=0, error_score=nan)通过param_name和param_range指定要进行网格搜索的变量名和值,从而计算出不同值所对应的学习曲线。返回(训练集得分, 测试集得分),进而可以从过拟合欠拟合角度选择合适参数。

5、网格搜索:通过设置参数字典进行交叉验证(用于调参)
model_selection.GridSearchCV(estimator, param_grid, scoring=None, n_jobs=1, iid=True, refit=True,
cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise',
return_train_score='warn')会对param_grid列表中的每个参数字典里的各参数做笛卡尔积来建模(共 d i c t 1 a 1 ∗ d i c t 1 a 2 + d i c t 1 b 1 ∗ d i c t 2 b 2 dict1_a1*dict1_a2+dict1_b1*dict2_b2 dict1a1∗dict1a2+dict1b1∗dict2b2个模型),通过交叉验证返回最优模型(是用apply()进行参数选择和交叉验证的合体)。会用fit和score方法,若在拟合器中有predict、predict_proba、decision_function、transform、inverse_transform方法也可以使用。参考
estimator是模型拟合器,要有fit()和score()方法;可以直接设置模型内不需要改变的参数。param_grid指定模型拟合器的参数字典,字典的键是待选值的列表(会将值进行笛卡尔积组合进入模型来筛选);或是字典的列表(每个字典表示一系列尝试,值是列表,表示各次迭代的参数,会将短元素进行拓展,使一个字典内值的元素长度相同);或是列表(各元素是一次迭代的参数)。scoring指定获得测试集的分的方法,是字符串(如"roc_auc")、函数(自定义得分函数,仅返回一个值)、序列、字典或None(用拟合器的scorer方法)参考。n_jobs指定并行任务量。iid指定各个交叉验证folder的数据分布是否一致。cv指定交叉验证的次数或交叉验证生成器。pre_dispatch指定启动任务前先关闭的任务数量。fefit是否用交叉验证获得的最佳参数组合对整个数据集进行拟合(不再是交叉验证),从而返回更准确的参数;若有多个评价方法则必须指定一个给scoring;使用该参数时实例会有best_estimator_属性,并可以直接使用实例的predict()方法。verbose指定显示等级,10是显示每次训练的结果实时输出。error_score指定拟合器拟合出错时的解决方法,“raise”(产生异常)、数值(作为默认得分,会有报警);对refit=True时,最终都会报错。return_train_score是否返回训练集的得分(通过cv_results_属性获取)。
属性:best_params_最佳模型的参数,在refit=True时有效。
best_estimator_返回最佳拟合模型(测试集得分最高),在refit=False时有效。
best_score_返回最佳拟合模型的交叉验证平均得分,在refit=True时有效。
best_index_返回最佳模型对应的参数在所有参数中的索引位置(全部参数),仅在refit=True时有效。scorer_返回用于计算得分的方法。grid_scores_返回每组参数交叉验证建模后得到的得分的均值、方差、对应的param_grid参数
cv_results_返回各种参数组合建模的结果字典 ,键有’mean_fit_time’, ‘mean_score_time’、‘mean_test_score’(多折交叉验证的平均结果)、‘std_test_score’(同一参数在交叉验证时的方差)等。
classes_返回类别列表。
estimator建树所用的拟合器
方法:fit(X, y=None, groups=None, **fit_params)进行模型拟合。groups指定对数据集X的分组,是数组,用于分层拆分。
predict(X)用最佳参数对应的模型进行预测。仅对refit=True且拟合器支持predict方法时有效。predict_proba(X)拟合概率值。predict_log_proba(X)拟合对数概率值
score(X, y)获得最佳参数对应模型的得分。仅对refit=True且拟合器支持score方法时有效。
transform(X)对数据进行转化,需要拟合器支持。inverse_transform(X)对X根据拟合器进行逆向转换。