搭建多人共用的GPU服务器
-
-
-
- 背景
- 需求
- 调研
- 安装
- 配置
- 配置LXD
- 配置网桥
- 新建容器
- 安装驱动
- 配置显卡
- 共享目录
- nvidia-uvm
- 桌面环境
- CUDA与cuDNN
- 其他
- 总结
- 参考
-
-
背景
目前实验室GPU使用情况是:大部分同学的配有单台1080/TITAN Xp。后来购入了两台4卡的机器,老师的意思是希望可以作为服务器使用,能够多人同时使用,互不影响。于是便开始了本次折腾,记录采坑经历。
通过本文,多卡读者可以实现分配每块GPU给特定同学使用,也可以多人共用多块GPU。单卡读者可以实现多人共用一块GPU。
需求
说需求之前先来列一下机器配置:
CPU: i7-6850K CPU
内存:DDR4 2400Hz 32G *4
存储:512G SSD *1 + 4TB 机械 *3
显卡:TITAN Xp *4
需求很明显:像使用一台带有GPU的自己的机器一样使用服务器。
具体来说要满足:
- 不同用户之间不能相互影响且可以同时使用
- 用户要能方便地访问自己的“机器”
- 用户有所有权限
- 用户不被允许直接操作宿主机
- 灵活配置GPU,可以每一分一块GPU,只有一个人用的时候可以用四块。
- 上网方便,使用自己的校园网帐号上网,可以使用IPV6
调研
首先可以肯定,Ubuntu多用户下可能存在误删其他同学文件,所需软件版本不兼容,GPU使用需要代码中指定等问题。
经过多方调研对比,在此省略xx字,最终选择使用LXD来搭建容器,实现上述需求。
我主要看好LXD:
- 相比LXC更简单,功能更强大
- 相比部署应用用的Docker更时候做操作使用的容器
- 相比KVM更轻便
- 支持GPU等设备Passthrough
- 调研过程中看到的资料足够满足我实现上述需求
- 支持RESTful API
所以整体思路是通过LXD容器实现多用户共用GPU服务器。
主要参考文献见文章最后一章节。
安装
安装过程主要安装了
- ZFS 用于管理物理磁盘,支持LXD高级功能
- LXD 实现虚拟容器
- bridge-utils 用于搭建网桥
sudo apt install zfs
sudo apt -t xenial-backports install lxd
sudo apt install bridge-utils配置
配置LXD
sudo lxd init,按照提示,这里我选择将第一块1TB的机械硬盘通过ZFS作为容器的存储后端。当提示是否创建bridge时,选择否。lxd init创建的bridge每个容器通过宿主机用NAT上网,我更希望每个人分配一个IP,通过自己的校园网上网。如果不需要,请选择是并忽略下一个章节。
配置网桥
修改/etc/network/interfaces,内容如下:
auto lo
iface lo inet loopback
auto br0
iface br0 inet dhcp
bridge_ports enp14s0
iface enp14s0 inet manual其中enp14s0可通过ifconfig查看网卡信息得到。
配置LXDlxc network attach-profile br0 default eth0。配置完成后需要重启下机器。
新建容器
如果你网速可以:lxc launch ubuntu:xenial yourContainerName可以试试直接下载,100M多点。
如果有网速不行建议添加清华大学的镜像,并且IPV6正好免校园网流量:
lxc remote add tuna-images https://mirrors.tuna.tsinghua.edu.cn/lxc-images/ --protocol=simplestreams --public
lxc image list tuna-images:之后使用lxc launch tuna-images:biasOrfootprint yourContainerName新建容器。
安装驱动
lxc exec yourContainerName bash可进入容器bash,在容器中显卡驱动不需要安装内核文件,只需要sudo sh /NVIDIA-Linux-x86_64-xxx.xx.run --no-kernel-module进行安装。
配置显卡
为容器添加所有GPU: lxc config device add yourContainerName gpu gpu。
添加指定GPU: lxc config device add yourContainerName gpu0 gpu id=0
共享目录
lxc config set yourContainerName security.privileged true
lxc config device add privilegedContainerName shareName disk source=path1 path=path2path1为宿主机路径,path2为容器内路径。
nvidia-uvm
兴冲冲的装好环境,发现TensorFlow无法使用显卡,原因是宿主机没有/dev/nvidia-uvm设备,需要通过以下命令挂载设备:
/sbin/modprobe nvidia-uvm
D=`grep nvidia-uvm /proc/devices | awk '{print $1}'`
mknod -m 666 /dev/nvidia-uvm c $D 0挂载设备到容器:
lxc config device add yourContainerName nvidia-uvm unix-char path=/dev/nvidia-uvm桌面环境
考虑到需要桌面环境的同学,我们通过VNC访问桌面环境。首先尝试的配置Ubuntu自带桌面,多次尝试失败,后来选择使用gnome桌面。
# 可选 --no-install-recommends 安装不必要组建
apt install ubuntu-desktop gnome-panel gnome-settings-daemon metacity nautilus gnome-terminal vnc4server -y在~/.vnc/xstartup文件中加入:
gnome-panel &
gnome-settings-daemon &
metacity &
nautilus &然后即可使用vnc4server,VNC具体使用不再赘述。
CUDA与cuDNN
CUDA与cuDNN安装本质上来讲只是解压文件(头文件,动态库等),所以我把不同版本的CUDA与cuDNN安装到了公共磁盘上,这个公共磁盘通过配置文件默认挂载到所有容器,其他同学在使用时按需添加环境变量和动态库路径即可。
其他
我整体的解决方案是把配置好的容器做成镜像,后续创建从这个镜像创建。这个镜像配置了SSH,VNC,普通用户等。
第二块硬盘通过ZFS管理zpool create A-pool /dev/sdb。通过配置文件挂载到容器。CUDA和cuDNN安装在这里。后续拷贝大型数据集也可以直接通过物理机拷贝。
上网处理可以通过VNC打开浏览器上网外,用上了之前写的一个Python登录校园网的库,可以通过脚本登录网络。
GPU默认通过配置文件挂载到容器。LXD相关操作见参考中的[3],用到了编辑配置文件,快照,镜像等相关操作,本文没有细说。
写份使用说明,并告知用户一定要修改默认SSH和VNC密码。
因为有RESTful API,所以可以做个WEB管理系统,后来发现了lxdui还挺好用:
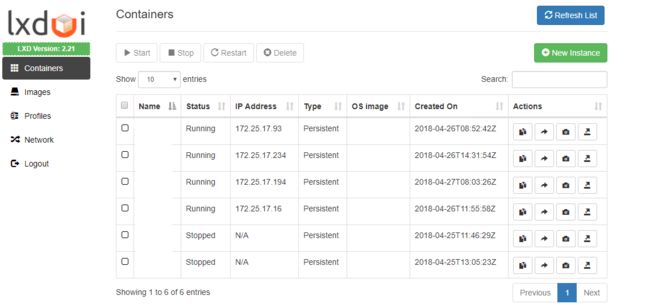
由于加载镜像拖慢速度,对代码简单进行了修改备用。后续准备基于lxdui增加权限控制等功能,每个用户可以方便的对自己的容器进行控制,快照等。
总结
本次折腾完美解决了需求,每个人通过SSH + VNC使用完全属于自己的机器,作为宿主机的管理员,我深知责任重大,更应该严守宿主机密码,常常以删除容器来威胁舍友,耐心帮助同学。
此外,有RESTful API还能做很多好玩的事情。
参考
- [1] https://blog.yangl1996.com/2018/01/11/gpu-passthrough-for-lxc.html
- [2 ]https://abcdabcd987.com/setup-shared-gpu-server-for-labs/
- [3] https://linux.cn/article-7618-1.html