深度学习笔记(20) 端到端学习
深度学习笔记(20) 端到端学习
- 1. 端到端的深度学习概念
- 2. 语音识别的端到端学习
- 3. 人脸识别的端到端学习
- 4. 机器翻译的端到端学习
- 5. 非端到端
- 6. 端到端的优缺点
- 7. 端到端的关键问题
1. 端到端的深度学习概念
深度学习中最令人振奋的最新动态之一就是端到端深度学习的兴起
简而言之,以前有一些数据处理系统或者学习系统,它们需要多个阶段的处理
端到端深度学习就是忽略所有这些不同的阶段,用单个神经网络代替它
2. 语音识别的端到端学习
来看一些例子,以语音识别为例
目标是输入x,一段音频,把它映射到一个输出y,就是这段音频的听写文本
所以传统上,语音识别需要很多阶段的处理
首先会提取一些特征,一些手工设计的音频特征
比如MFCC,这种算法是用来从音频中提取一组特定的人工设计的特征
在提取出一些低层次特征之后,可以应用机器学习算法在音频片段中找到音位
所以音位是声音的基本单位,比如说“Cat”这个词是三个音节构成的,Cu-、Ah-和Tu-
算法就把这三个音位提取出来
然后将音位串在一起构成独立的词
然后将词串起来构成音频片段的听写文本
所以,和这种有很多阶段的流水线相比,端到端深度学习做的是训练一个巨大的神经网络,输入就是一段音频,输出直接是听写文本
事实证明,端到端深度学习的挑战之一是,可能需要大量数据才能让系统表现良好
比如,只有3k小时数据去训练语音识别系统,那么传统的流水线效果真的很好
但当拥有非常大的数据集时,比如10k小时数据或者100k小时数据
这样端到端方法突然开始很厉害了
需要大数据集才能让端到端方法真正发出耀眼光芒
如果数据量适中,那么也可以用中间件方法,可能输入还是音频
然后绕过特征提取,直接尝试从神经网络输出音位
3. 人脸识别的端到端学习
端到端学习也可以在其他阶段用
就如人脸识别,首先是找到人脸
然后放大图像的那部分,并裁剪图像,使人脸居中显示
然后再喂到神经网络里,让网络去学习,估计身份
总的来说就是,是弄清楚脸在哪里,再弄清楚这是谁
两步法更好原因:
一是解决的两个问题,每个问题实际上要简单得多
二是两个子任务的训练数据都很多
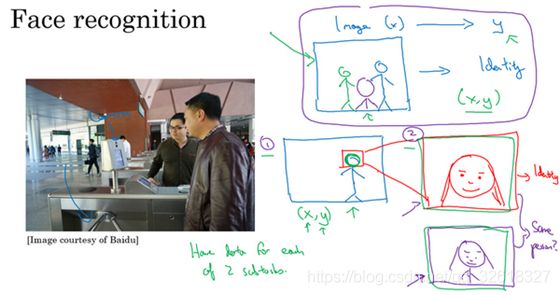
具体来说,有很多数据可以用于人脸识别训练,对于这里的任务1来说,任务就是观察一张图
找出人脸所在的位置,把人脸图像框出来
所以有很多数据,有很多标签数据(x,y)
其中x是图片,y是表示人脸的位置,可以建立一个神经网络,可以很好地处理任务1
然后任务2,也有很多数据可用,比如说数百万张人脸照片
所以输入一张裁剪得很紧凑的照片,今天业界领先的人脸识别团队有至少数亿的图像,可以用来观察两张图片,并试图判断照片里人的身份,确定是否同一个人
相比之下,如果想一步到位,这样(x,y)的数据对就少得多
其中x是门禁系统拍摄的图像,y是那人的身份
因为没有足够多的数据去解决这个端到端学习问题
但却有足够多的数据来解决子问题1和子问题2
实际上,把这个分成两个子问题,比纯粹的端到端深度学习方法,达到更好的表现
不过如果有足够多的数据来做端到端学习,也许端到端方法效果更好
但在今天的实践中,并不是最好的方法
4. 机器翻译的端到端学习
再来看几个例子,比如机器翻译
传统上,机器翻译系统也有一个很复杂的流水线
比如英语机翻得到文本,然后做文本分析
基本上要从文本中提取一些特征之类的,经过很多步骤
最后会将英文文本翻译成法文
因为对于机器翻译来说的确有很多(英文,法文)的数据对
端到端深度学习在机器翻译领域非常好用
那是因为现在可以收集x-y对的大数据集
就是英文句子和对应的法语翻译
5. 非端到端
比如说希望观察一个孩子手部的X光照片,并估计一个孩子的年龄
这个问题的典型应用,是儿科医生用来判断一个孩子的发育是否正常

处理这个例子的一个非端到端方法,就是照一张图,然后分割出每一块骨头
所以就是分辨出那段骨头应该在哪里,那段骨头在哪里,那段骨头在哪里,等等
然后,知道不同骨骼的长度,可以去查表
查到儿童手中骨头的平均长度来估计年龄,所以这种方法实际上很好
相比之下,如果直接从图像去判断孩子的年龄,那么需要大量的数据去直接训练
但这种做法今天还是不行的,因为没有足够的数据来用端到端的方式来训练这个任务
所以在这个例子中,端到端深度学习效果很好
所以端到端深度学习系统是可行的,它表现可以很好,也可以简化系统架构,不需要搭建那么多手工设计的单独组件
但它也不是灵丹妙药,并不是每次都能成功
6. 端到端的优缺点
假设正在搭建一个机器学习系统
要决定是否使用端对端方法,了解端到端深度学习的一些优缺点
这样就可以根据一些准则,判断应用程序是否有希望使用端到端方法
应用端到端学习的一些好处
第一个好处是端到端学习真的是只让数据说话
第二个好处是简化设计工作流程,无需花太多时间去手工设计功能和中间表示方式
这里有一些缺点,首先,它可能需要大量的数据
另一个缺点是,它排除了可能有用的手工设计组件
7. 端到端的关键问题
学习算法有两个主要的知识来源
一个是数据,另一个是手工设计的任何东西,可能是组件,功能,或者其他
所以,在构建一个新的机器学习系统时是否使用端到端深度学习的关键问题是
是否有足够的数据能够直接学到从x映射到y足够复杂的函数
现在还没有正式定义过这个词 “必要复杂度(complexity needed)”
但直觉上,如果想从x到y的数据学习出一个函数
就是看着这样的图像识别出图像中所有骨头的位置
那么也许这像是识别图中骨头这样相对简单的问题
也许系统不需要那么多数据来学会处理这个任务
给出一张人物照片,也许在图中把人脸找出来不是什么难事
所以也许不需要太多数据去找到人脸,或者至少可以找到足够数据去解决这个问题
相对来说,把手的X射线照片直接映射到孩子的年龄,直接去找这种函数,直觉上似乎是更为复杂的问题
最后讲一个更复杂的例子,
吴恩达老师一直在花时间帮忙主攻无人驾驶技术的公司 drive. ai
造出一辆能自主行驶的车,这不是端到端的深度学习方法
可以把车前方的雷达、激光雷达或者其他传感器的读数看成是输入图像
但是为了说明起来简单,就说拍一张车前方或者周围的照片
然后驾驶要安全的话,必须能检测到附近的车,也需要检测到行人,需要检测其他的东西
之后就需要计划路线,需要决定如何摆方向盘引导车子的路径,还要发出合适的加速和制动指令
从传感器或图像输入到检测行人和车辆,深度学习可以做得很好
但一旦知道其他车辆和行人的位置或者动向,选择一条车要走的路
这通常用的不是深度学习,而是用所谓的运动规划软件完成的
如果学过机器人课程,一定知道运动规划
然后决定了你的车子要走的路径之后
还会有一些其他算法,控制算法可以产生精确的决策确定方向盘应该精确地转多少度,油门或刹车上应该用多少力
所以这个例子就表明
如果想使用机器学习或者深度学习来学习某些单独的组件
那么应用监督学习时,应该仔细选择要学习的x到y映射类型
这取决于那些任务可以收集数据
相比之下,谈论纯端到端深度学习方法是很激动人心的
输入图像,直接得出方向盘转角
但是就目前能收集到的数据而言
还有现在能够用神经网络学习的数据类型而言
这实际上不是最有希望的方法
这种纯粹的端到端深度学习方法
其实前景不如这样更复杂的多步方法
目前能收集到的数据,还有现在训练神经网络的能力是有局限的
这就是端到端的深度学习,有时候效果拔群
但也要注意应该在什么时候使用端到端深度学习
参考:
《神经网络和深度学习》视频课程
相关推荐:
深度学习笔记(19) 多任务学习
深度学习笔记(18) 迁移学习
深度学习笔记(17) 误差分析(二)
深度学习笔记(16) 误差分析(一)
深度学习笔记(15) 人的表现
谢谢!