论文笔记:Recurrent Convolutional Neural Networks for Text Classification
1 Abstract
文本分类是NLP的一项重要的基础任务。传统的文本分类需要特征工程,需要人类参与。而深度学习能够自动提取特征不需要人的参与。本文采用周期循环神经网络比卷积神经网络能够更加减少噪声,利用最大池化层选取一句话中最重要的特征。
首先在学习词的表达的时候,采用双向循环结构获取文本信息,比传统的基于窗口的神经网络更能减少噪声,而且在学习文本表达时可以大范围的保留词序。其次使用最大池化层获取文本主要成分,自动判断哪个特征在文本分类过程中起更重要的作用。2 introduction
文本分类在很多应用中是非常重要的一部分。such as web searching, information filtering, and sentiment analysis。
feature representation:
- bag-of-words: where unigrams, bigrams, n-grams or some exquisitely designed patterns are typically extracted as features.
- several feature selection methods: frequency, MI, pLSA, LDA
- 传统的特征表达方法经常忽略了上下文的信息和词序信息,以及语义信息。
- 高阶n-gram,tree kernels被应用在特征表达,但是也有稀疏的缺点,影响准确性。
- word embedding: word2vec 能够捕捉更多语法和语义特征。
- 效果完全依赖于文本树的构建,并且构建文本树所需的时间是O(n^2). 并且两个句子的关系也不能通过一颗树表现出来。因此不适合与长句子或者文本。
- 优点:获取上下文信息。
- 缺点:有偏的模型(biased model),后面的词占得重要性更大。这样不好,因为每个词都可能是重要的词。
- 所以:Thus, it could reduce the effectiveness when it is used to capture the semantics of a whole document, because key components could appear anywhere in a document rather than at the end.
- 优点:无偏的模型(unbiased model),能够通过最大池化获得最重要的特征。
- Thus, the CNN may better capture the semantic of texts compared to recursive or recurrent neural networks.
- 时间复杂度:O(n)
- 缺点:CNN卷积器的大小固定,如果选小了容易造成信息的丢失;如果选大了,会造成巨大的参数空间。
- 所以:Therefore, it raises a question: can we learn more contextual information than conventional window-based neural networks and represent the semantic of texts more precisely for text classification.
双向循环结构:比传统的基于窗口的神经网络噪声要小,能够最大化地提取上下文信息。
We apply a bi-directional recurrent structure, which may introduce considerably less noise compared to a traditional window- based neural network, to capture the contextual information to the greatest extent possible when learning word repre- sentations. Moreover, the model can reserve a larger range of the word ordering when learning representations of texts.
We employ a max-pooling layer that automatically judges which features play key roles in text classification, to capture the key component in the texts.
3 related work
文本分类
- 传统的文本分类主要关注3个主题:特征工程,特征选择和使用不同的机器学习模型。
特征工程:广泛使用的特征工程是bag-of-words
For feature engineering, the most widely used feature is the bag-of-words feature. In addition, some more complex features have been designed, such as part-of-speech tags, noun phrases (Lewis 1992) and tree kernels (Post and Bergsma 2013).
Feature selection aims at deleting noisy features and improving the classification performance. The most common feature selec- tion method is removing the stop words (e.g., “the”). Ad- vanced approaches use information gain, mutual informa- tion (Cover and Thomas 2012), or L1 regularization (Ng 2004) to select useful features
Machine learning algorithms often use classifiers such as logistic regression (LR), naive Bayes (NB), and support vector machine (SVM). However, these methods have the data sparsity problem.
- 深度学习网络和词向量的研究解决了数据稀疏的问题。
词向量的研究使我们测量两个词向量的相似度来表征两个词之间的相似度。
With the pre-trained word embeddings, neural networks demonstrate their great performance in many NLP tasks. Socher et al. (2011b) use semi-supervised recursive autoen coders to predict the sentiment of a sentence. Socher et al. (2011a) proposed a method for paraphrase detection also with recurrent neural network. Socher et al. (2013) introduced recursive neural tensor network to analyse sentiment of phrases and sentences. Mikolov (2012) uses recurrent neural network to build language models. Kalchbrenner and Blunsom (2013) proposed a novel recurrent network for di- alogue act classification. Collobert et al. (2011) introduce convolutional neural network for semantic role labeling.
4 Model
Word Representation Learning
使用双向RNN分别学习当前词 w i w_i wi的左上下文表示 c l ( w i ) c_l(w_i) cl(wi)和右上下文表示 c r ( w i ) c_r(w_i) cr(wi),再与当前词自身的表示 e ( w i ) e(w_i) e(wi)连接,构成卷积层的输入 x i x_i xi。具体如下:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ c_l(w_i) = f(…
e ( w i − 1 ) e(w_{i-1}) e(wi−1)is the word embedding of word w i − 1 w_{i-1} wi−1,which is a dense vector with ∣ e ∣ |e| ∣e∣ real value elements.
任何文档中第一个单词的左侧上下文使用相同的共享参数 c l ( w 1 ) c_{l}(w_{1}) cl(w1),最后一个单词的右侧上下文共享参数 c r ( w n ) c_{r}(w_{n}) cr(wn).
使用此模型时间复杂度仅为O(n),与文本长度呈线性相关,大大地消除了歧义。
然后将 x i x_i xi作为 w i w_i wi的表示,输入到激活函数为tanh,kernel size为1的卷积层,得到 w i w_i wi的潜在语义向量(latent semantic vector) y i ( 2 ) y^{(2)}_i yi(2),具体如下:
y i ( 2 ) = t a n h ( W ( 2 ) x i + b ( 2 ) ) y^{(2)}_i=tanh(W^{(2)}x_i+b^{(2)}) yi(2)=tanh(W(2)xi+b(2))
将kernel size设置为1是因为 x i x_i xi中已经包含 w i w_i wi左右上下文的信息,无需再使用窗口大于1的filter进行特征提取。但是需要说明的是,在实践中仍然可以同时使用多种kernel size的filter,如[1, 2, 3],可能取得更好的效果,一种可能的解释是窗口大于1的filter强化了 w i w_i wi的左右最近的上下文信息。此外,实践中可以使用更复杂的RNN来捕获 w i w_i wi的上下文信息如LSTM和GRU等。
Text Representation Learning
经过卷积层后,获得了所有词的表示,然后在经过最大池化层和全连接层得到文本的表示,最后通过softmax层进行分类。具体如下:
(1) Max-pooling layer
y ( 3 ) = max i = 1 n y i ( 2 ) y^{(3)}=\max \limits_{i=1}^{n} y^{(2)}_i y(3)=i=1maxnyi(2)
(2) Fully connected layer
y ( 4 ) = W ( 4 ) y ( 3 ) + b ( 4 ) y^{(4)}=W^{(4)}y^{(3)}+b^{(4)} y(4)=W(4)y(3)+b(4)
(3) Softmax layer
p i = exp ( y i ( 4 ) ) ∑ k = 1 n exp ( y k ( 4 ) ) p_i=\frac{\exp(y^{(4)}_i)}{\sum_{k=1}^n \exp(y^{(4)}_k)} pi=∑k=1nexp(yk(4))exp(yi(4))
下图为上述过程的一个图解:

如图所示,先经过1层双向LSTM,该词的左侧的词正向输入进去得到一个词向量,该词的右侧反向输入进去得到一个词向量。再结合该词的词向量,生成一个 1 * 3k 的向量。
再经过全连接层,tanh为非线性函数,得到y2。
再经过最大池化层,得出最大化向量y3.
再经过全连接层,sigmod为非线性函数,得到最终的多分类。
Training
训练网络参数 θ = { E , b ( 2 ) , ( 4 ) , c l ( w 1 ) , c r ( w n ) , W ( 2 ) , W ( 4 ) , W ( l ) , W ( r ) , W ( s l ) , W ( s r ) } θ = \left\{E,b^{(2)},^{(4)},c_{l}(w_{1}),c_{r}(w_{n}), W^{(2)},W^{(4)},W^{(l)},W^{(r)},W^{(sl)},W^{(sr)}\right\} θ={E,b(2),(4),cl(w1),cr(wn),W(2),W(4),W(l),W(r),W(sl),W(sr)}
最大化关于 θ θ θ 的对数似然函数,使用随机梯度下降法来优化训练目标。
此处使用了一个常用技巧,即神经网络中的所有参数由均匀分布初始化而成。最大值或最小值的量级等于“fan-in”的平方根,“fan-in”是模型中上一层的网络节点数。
Pre-training Word Embedding
Recent research shows that neural networks can converge to a better local minima with a suitable unsupervised pre-training procedure。
本文中使用的是Skip-gram模型。
5 Experiments
Datasets
- **20Newsgroups1** qwone.com/˜jason/20Newsgroups/ 数据集包含20个新闻组的信息,我们使用日期版本并选择四种主要类别(综合,政治,娱乐和宗教).
- **Fudan set2** 2www.datatang.com/data/44139 and 43543 复旦大学文件分类集合是一个中文文件分类集合,包含20个分类,包括艺术教育和能源。
- **ACL Anthology Network3** old-site.clsp.jhu.edu/˜sbergsma/Stylo/ 该数据集包含了由ACL和相关组织发布的科学文献。它由五种语言注解:英语,日语,德语,中文和法语。
- **Stanford Sentiment Treebank4** nlp.stanford.edu/sentiment/ 这个数据集包含了电影评论解析,和五种标签:非常消极,消极,中立,积极,非常积极。
Experiment Settings
数据预处理:
- 英文:use the Stanford Tokenizer5 to obtain the tokens
- 中文:use ICTCLAS6 to segment the words
- 不去停用词
ACL和SST有预定义的training、development和testing separation,其他数据集10%development和90%training。
评价指标20Newsgroups用Macro-F1,其他用accuracy。
超参数设置:
- the learning rate of the SGD: 0.01
- the hidden layer size: 100
- the size of the context vector: 50 (left + right = 100)
- the vector size of the word embedding: 50
- Pre-training Word Embedding:
- using the default parameter in word2vec with the Skip-gram algorithm.
- use Wikipedia dumps in both English and Chinese
###Comparison of Methods
- Bag of Words/Bigrams + LR/SVM
文本分类的基准主要使用单词或双词作为特征的机器学习算法。
分别使用LR和SVM(www.csie.ntu.edu.tw/˜cjlin/liblinear),每个特征的权重为术语出现的频率。 - Average Embedding + LR
这个基准使用词嵌入的平均权重,随后应用到一个softmax层。每个单词的权重是它词频-逆向文件频率的值 - LDA
在集中分类任务中,基于LDA的方法能够较好捕获文本的语义。我们选择两种方法用于比较:ClassifyLDA-EM和Labeled-LDA。 - Tree Kernels
使用各种tree kernel作为特征,是ACL母语分类任务中最先进的工作。列举两个主要方法用以比较:the context-free grammar (CFG) produced by the Berkeley parser (Petrov et al. 2006) and the reranking feature set of Charniak and Johnson (2005) (C&J)。 - RecursiveNN
我们使用两种递归结构比较:the Recursive Neural Network (RecursiveNN) (Socher et al. 2011a) 和它的改进版本 the Recursive Neural Tensor Networks (RNTNs)。 - CNN
选择卷积神经网络用于比较。它的卷积内核只是简单的级联了预定义窗口大小的词嵌入。
Results and Discussion
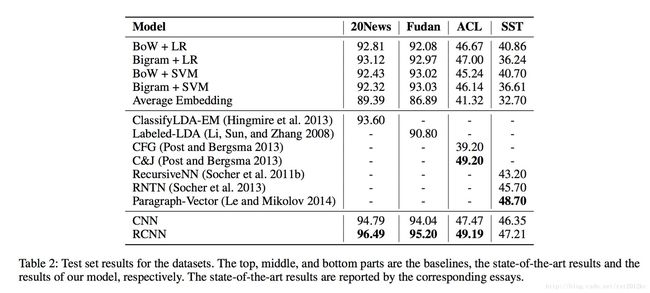
-
NN vs. traditional methods: 在该论文的所有实验数据集上,神经网络比传统方法的效果都要好
- It proves that neural network based approach can effective compose the semantic representation of texts.
- Neural networks can capture more contextual information of features compared with traditional methods based on BoW model, and may suffer from the data sparsity problem less.
-
Convolution-based vs. RecursiveNN: 基于卷积的方法比基于递归神经网络的方法要好
- The convolution-based framework is more suitable for constructing the semantic representation of texts compared with previous neural networks.
- The main reason is that CNN can select more discriminative features through the max-pooling layer and capture contextual information through convolutional layer.
- By contrast, RecursiveNN can only capture contextual information using semantic composition under the constructed textual tree, which heavily depends on the performance of tree construction.
- A lower time complexity [O(n)] than the recursive-based approaches [O(n2)]
-
除了ACL和SST,在别的数据集上都是RCNN最好
-
RCNN vs. CFG and C&J: The RCNN可以捕获更长的模式(patterns)
- The RCNN does not require handcrafted feature sets, which means that it might be useful in low-resource languages.
-
RCNN vs. CNN: 在该论文的所有实验数据集上,RCNN比CNN更好
- The reason is the recurrent structure in the RCNN captures contextual information better than window-based structure in CNNs.
Contextual Information
如何能够更有效捕获上下文信息?通过CNNs与RCNNs对比,如下图,可以知道RCNN更好。
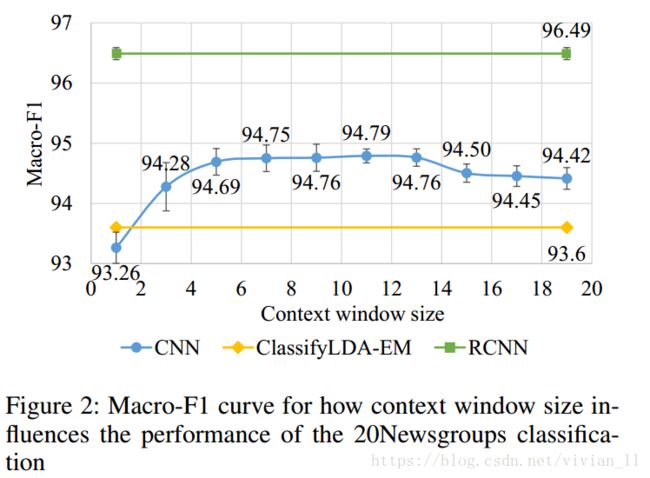
- CNNs使用固定的词窗口(window of words), 实验结果受窗口大小影响
- A small window: a loss of some long-distance patterns,
- Large windows: data sparsity, a large number of parameters are more difficult to train
- RCNNs使用循环结构捕获广泛的上下文信息
- The RCNN could capture contextual information with a recurrent structure that does not rely on the window size.
- The RCNN outperforms window-based CNNs because the recurrent structure can preserve longer contextual information and introduces less noise.
Learned Keywords
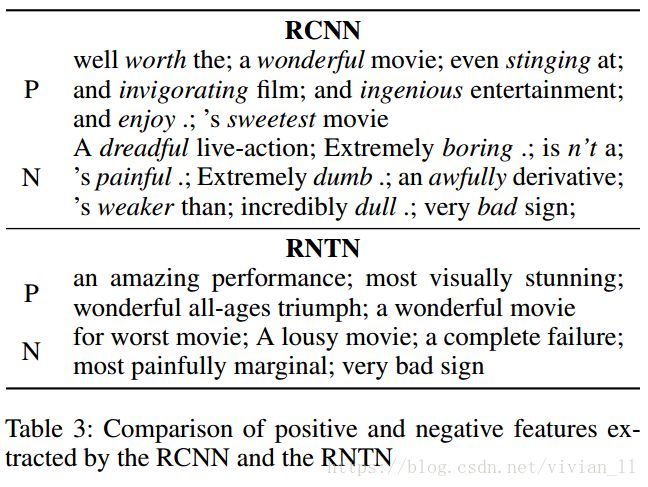
关键词在文本分类任务中非常重要的决策。因此论文列出了RCNN学习到的一些重要关键词(选择max-pooling层中最频繁被选中的词作为中心的trigram),并与RNTN学习到的关键词作为对比,如Table 3。观察到了如下现象:
- In contrast to the most positive and most negative phrases in RNTN(Socheret al. 2013), RCNN does not rely on a syntactic parser, therefore, the presented n-grams are not typically “phrases”.
- The results demonstrate that the most important words for positive sentiment are words such as “worth”, “sweetest”, and “wonderful”, and those for negative sentiment are words such as “awfully”, “bad”, and “boring”.
Conclusion
无新内容,略。