CS231N Assignment 2 Batch Normalization
CS231N Assignment 2 Batch Normalization 作业
running_mean and running_var:
每次更新running mean相当于把之前的值衰减一些(* momentum),然后把当前的min-batch sample_mean加进去一部分(* (1-momentum))。其实也就是一阶指数平滑平均。在test时,直接使用训练得到的running_mean/var来计算。
这点在原论文中也有提到,在test时:
scale = gamma / (np.sqrt(running_var + epsilon))
x_hat = x * scale + (beta - running_mean * scale) bp部分代码实现:
def batchnorm_backward_alt(dout, cache):
gamma, x, mu_b, sigma_squared_b, eps, x_hat = cache # mu_b == sample_mean; sigma_squared_b == smaple_var
m = x.shape[0]
dx_hat = dout * gamma
dsigma_squared = np.sum(dx_hat * (x - mu_b), axis=0) * -1/2 * np.power((sigma_squared_b + eps),-3/2)
dmu_b = np.sum(dx_hat * -1/np.sqrt(sigma_squared_b + eps), axis=0) + dsigma_squared * np.sum(-2 * (x - mu_b), axis=0) / m
dx = dx_hat / np.sqrt(sigma_squared_b + eps) + dsigma_squared * 2 * (x-mu_b)/m + dmu_b / m
dgamma = np.sum(dout * x_hat, axis=0)
dbeta = np.sum(dout, axis=0)
return dx, dgamma, dbeta照抄论文中的bp推导,用代码实现即可
计算图:
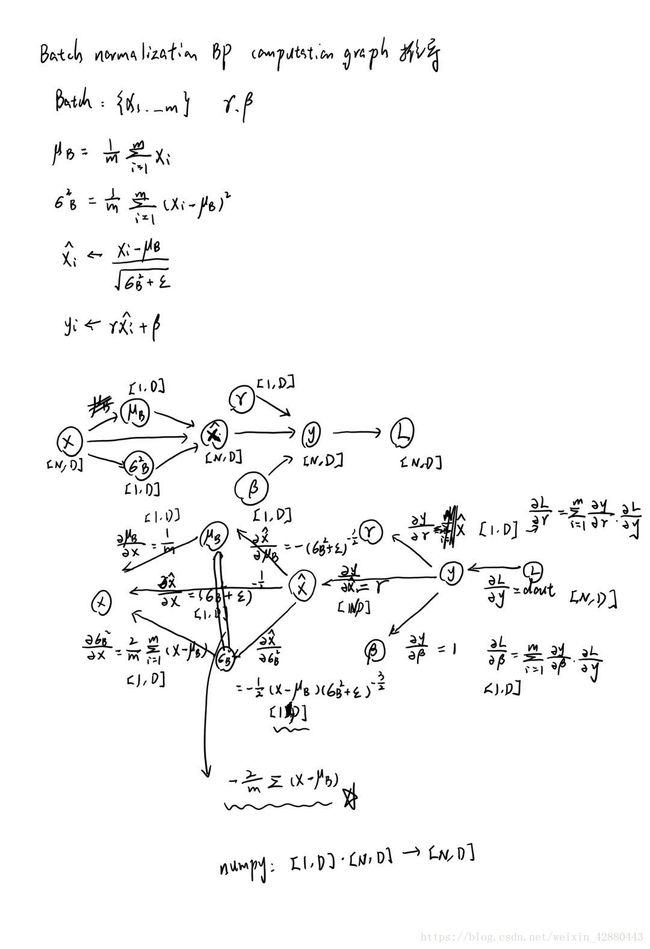
https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html 的推导更加详细
- 每个量的维度要确定,会对dx产生很大影响
- 注意 sigma_square_2 到 mu_b 需要求导
- sum 时,axis = 0 不要漏,否则得到的就是一个值,而不是一个向量
- 下面代码中对应计算图:从右往左,下标递增
def batchnorm_backward(dout, cache):
gamma, x, mu_b, sigma_squared_b, eps, x_hat = cache
m = x.shape[0]
dgamma = np.sum(dout * x_hat, axis=0)
dbeta = np.sum(dout, axis=0)
dx_1 = dout
dx_2 = gamma
dx_hat = dx_2 * dx_1
dx_3_sigma_2 = np.sum(-1/2 * (x - mu_b) * np.power((sigma_squared_b + eps), -3/2) * dx_hat, axis=0)
dx_3_mu = np.sum(-1 / np.sqrt(sigma_squared_b+eps) * dx_hat, axis=0)
dx_3_x = 1 / np.sqrt(sigma_squared_b+eps) * dx_hat
dx_4_mu = -2/m *np.sum(x-mu_b, axis=0) * dx_3_sigma_2 + dx_3_mu
dx_5_mu = 1 / m * dx_4_mu
dx_5_sigma_2 = 2 / m * (x - mu_b) * dx_3_sigma_2
dx = dx_3_x + dx_5_sigma_2 + dx_5_mu
return dx, dgamma, dbetaFully Connected Nets with Batch Normalization
根据提示:”You might find it useful to define an additional helper layer similar to those in the file cs231n/layer_utils.py”
创建helper function(仿照affine_relu_**)
def affine_relu_bn_forward(x, w, b, gamma, beta, bn_param):
a, fc_cache = affine_forward(x, w, b)
bn, bn_cache = batchnorm_forward(a, gamma, beta, bn_param)
out, relu_cache = relu_forward(bn)
cache = (fc_cache, bn_cache, relu_cache)
return out, cache
def affine_relu_bn_backward(dout, cache):
fc_cache, bn_cache, relu_cache = cache
dbn = relu_backward(dout, relu_cache) # 先归一化,再经过激活层
da, dgamma, dbeta = batchnorm_backward_alt(dbn, bn_cache)
dx, dw, db = affine_backward(da, fc_cache)
return dx, dw, db, dgamma, dbeta然后做好和 fc_net.py 的调用衔接
Charlie
杭州
8.8