Avro高速序列化、反序列化
--本文主要介绍内存中实现序列化,返回bytes[]用于存储与hbase,以及从hbase取出数据把bytes[] 反序列化为GenericRecord。
Avro存储结构如下:
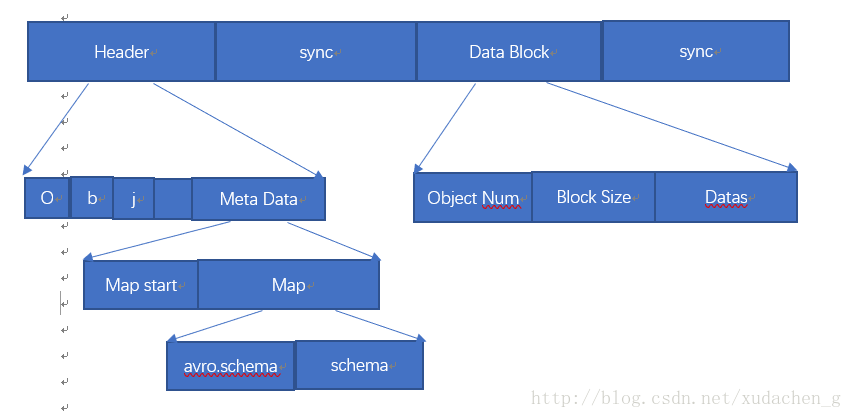
首先,开头4个字符为Obj加上一个long类型的版本号的byte[]数据,MetaData区域存储为一个long类型的map start标记。然后是map,这个map里面存储的key为avro.schema,value为schema转化成的byte[]。sync为16字节同步标记,可以自己设定,或者通过计算获得。Data Block区域存储第一个是Object Num对象数量,Block Size 为块大小,即后面Datas的长度。Datas存储为数据序列化后的数据。最后又是sync 16字节同步标记。
之前项目中为了实现这个需求方法如下:
序列化:
public static byte[]serialize_old(Schemaschema,List
DatumWriter
DataFileWriter
dataFileWriter.create(schema,outputStream);
}
result = outputStream.toByteArray();
}
e.printStackTrace();
}
return result;
}
public static List
List
GenericRecord record = null;
DatumReader
try(ByteArrayInputStream inputStream = new ByteArrayInputStream(value);
DataFileStream
while (dataFileReader.hasNext()) {
record = dataFileReader.next(record);
recordList.add(record);
}
}catch (Exception e){
e.printStackTrace();
}
return recordList;
}
使用以上两种方法进行序列化反序列化发现效率很低,但是他完全按照上图给出的结构进行存储。
于是便找到了下面这种。
序列化:public static byte[] serializeNew(GenericRecord record, Schema schema) {
byte[] result = null;
try (ByteArrayOutputStream out = new ByteArrayOutputStream()){
Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
DatumWriter
writer.write(record, encoder);
encoder.flush();
result = out.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
反序列化:
public static GenericRecord getDeserializeNew(byte[] value,Schema schema){
GenericRecord record = null;
DatumReader
try{
Decoder decoder = DecoderFactory.get().binaryDecoder(value,null);
record = datumReader.read(null,decoder);
}catch (Exception e){
e.printStackTrace();
}
return record;
}
这种方式 是只存储Datas其他信息都不存储。序列化效率是老版本的10倍,反序列化效率是老版本的15倍左右。但是有个缺陷就是它不能反序列化老的序列化过后的数据,同理,它序列化的数据,用老的反序列化不能解。而且如果schema发生了改变,因为它没有存储序列化时候的schema,则无法反序列化数据。于是需要找到兼容老数据的方式。通过上图的结构进行:
序列化逻辑:
/**
* 序列化逻辑
* @param schema Schema 规则(因为大数据处理时候,这些参数一般都先缓存下来再取用)
* @param records 数据
* @param schemaByte schema.toString.getBytes (因为大数据处理时候,这些参数一般都先缓存下来再取用)
* @return value
*/
public static byte[] serilize_list(Schema schema,List
byte[] result = null;
try (ByteArrayOutputStream out = new ByteArrayOutputStream();){
byte[] sync = new byte[16];Encoder encoder = EncoderFactory.get().binaryEncoder(out, null);
GenericDatumWriter
for(int i=0;i
writer.write(records.get(i), encoder);
}
encoder.flush();
获取写入的数据
byte[] value = out.toByteArray();
计算块大小
int blockSize = value.length; out.reset();
// obj加long类型的一个数据,这里需要应用avro包自带数据
encoder.writeFixed(DataFileConstants.MAGIC);
//map start
encoder.writeMapStart();
//当前环境只会出现1
encoder.setItemCount(1);
encoder.startItem();
//map 里面的数据 avro.schema 和 schema
encoder.writeString("avro.schema");
encoder.writeBytes(schemaByte);
encoder.writeMapEnd();
// byte[] curSync = generateSync();
//16字节同步标记,可以通过计算获取,可以空值
encoder.writeFixed(sync);
//写入对象数量,即 record数量
encoder.writeLong(records.size());
//写入块大小
encoder.writeLong(blockSize);
//写入数据
encoder.writeFixed(value);
//16字节同步标记,可以通过计算获取,可以空值
encoder.writeFixed(sync);
encoder.flush();
out.flush();
//获取结果
result = out.toByteArray();out.reset();
//截取掉一开始写入的record数据,保留后面需要的数据
//result = Arrays.copyOfRange(result,blockSize,result.length);
} catch (IOException e) {
e.printStackTrace();
}
return result;
}
计算sync方法:
private static byte[] generateSync() {
try {
MessageDigest digester = MessageDigest.getInstance("MD5");
long time = System.currentTimeMillis();
digester.update((UUID.randomUUID() + "@" + time).getBytes());
return digester.digest();
} catch (NoSuchAlgorithmException var3) {
throw new RuntimeException(var3);
}
}
反序列化逻辑:
/**
* 反序列化逻辑
* @param value 需要反序列化的value
* @param name 解这个value需要用的schema的名字 可以都传空
* @return
*/
public static List
List
GenericRecord record = null;
try{
byte[] schemaByte = null;
Decoder decoder = DecoderFactory.get().binaryDecoder(value,null);
//过滤掉 头部
decoder.readFixed(magic);
//获取schema 数量
long l = decoder.readMapStart();
//过滤掉schema
if(l > 0L) {
do {
for(long i = 0L; i < l; ++i) {
//得到avro.schema
decoder.readString((Utf8)null).toString();
//得到schema 的 byte[]
ByteBuffer buf = decoder.readBytes((ByteBuffer)null);
schemaByte = buf.array();
}
} while((l = decoder.mapNext()) != 0L);
}
//过滤掉 16字节 同步标记
decoder.readFixed(sync);
//过滤掉 对象 数量
long i = decoder.readLong();
//过滤掉 块大小
decoder.readLong();
//获取最终数据
for(int j=0;j
records.add(record);
}
}catch (Exception e){
e.printStackTrace();
}
return records;
}
其中调用的reader方法如下:
public static Map
/**
* 缓存 reader 以待随时取用
* @param schemaByte
* @param name
* @return reader
*/
public static DatumReader
if(readerMap.containsKey(name)){
Map
Iterator it = byteMap.entrySet().iterator();
while (it.hasNext()){
Map.Entry
byte[] byteKey = mapEntry.getKey();
if(Arrays.equals(byteKey,schemaByte)){
return mapEntry.getValue();
}
}
Schema schema = new Schema.Parser().parse(Bytes.toString(schemaByte));
DatumReader
byteMap.put(schemaByte,reader);
readerMap.put(name,byteMap);
return reader;
}else {
Schema schema = new Schema.Parser().parse(Bytes.toString(schemaByte));
DatumReader
Map
byteReaderMap.put(schemaByte,reader);
readerMap.put(name,byteReaderMap);
return reader;
}
}
这种新的序列化、反序列化,完美与老的序列化,反序列化兼容,并且保证了序列化速度是老的5倍,反序列化是老的10倍。完美解决问题