机器学习实战——K-近邻法、KD树
机器学习实战专辑part2——K-近邻法@[适合初学小白超详细!]
前段时间忙小论文和专利,写博客耽搁了好久,终于终于有时间可以继续写了,虽然没记录在博客上,但是学习依然没有松懈,废话不多说,今天欢迎我们的主角登场,K-近邻法。
一、K-近邻法基本概念
K-近邻法也叫KNN是一种基本分类与回归方法,一般是用来解决分类问题,它的输入为实例的特征向量,对应于特征空间的点,输出为实例的类别,可以取多类。K-近邻法假设给定一个训练数据集,其中实例的类别已定,分类时,对新的实例,根据其K个最近邻训练实例的类别,通过多数表决的等方式进行预测。K-近邻法没有显式的学习过程。
思路
K-近邻是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
三个基本要素
1.K值的选择
对于k值的选择,没有一个固定的经验,一般根据样本的分布,选择一个较小的值,可以通过交叉验证选择一个合适的k值。
选择较小的k值,就相当于用较小的领域中的训练实例进行预测,训练误差会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是泛化误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
选择较大的k值,就相当于用较大领域中的训练实例进行预测,其优点是可以减少泛化误差,但缺点是训练误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测器作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
一个极端是k等于样本数m,则完全没有分类,此时无论输入实例是什么,都只是简单的预测它属于在训练实例中最多的类,模型过于简单。
举个栗子说明一下K值的选择对分类结果的影响:
如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
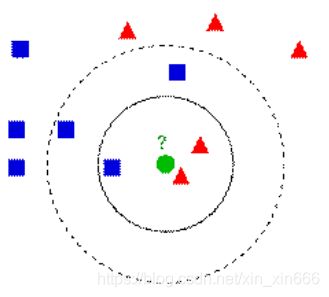
由此也说明了KNN算法的结果很大程度取决于K的选择。
2.距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映,那么如何度量这个距离呢?一般我们选择欧式距离或更为一般的Lp距离。
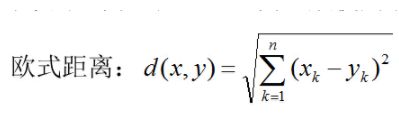
其中p=2,根据不同的p值选择,也即不同的距离度量方法,确定的最近邻点是不同的。
3.分类决策规则
k-近邻法中的分类决策规则往往是多数表决,即由输入实例的K个邻近的训练实例中的多数类决定输入实例的类。多数表决规则等价于经验风险最小化。
二、实现k-近邻法伪代码
对未知类别属性的数据集中的每个点依次执行以下操作:
(1)计算已知类别数据和当前点之间的距离
(2)按照距离递增次序排序
(3)选取与当前距离最小的K个点
(4)确定前K个点所在类别的出现频率
(5)返回前K个点出现频率最高的类别作为当前点的预测分类
三、K近邻法python代码实现
from numpy import *
import operator
def createDataSet():
group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #我觉得可以这样理解,每一种方括号都是一个维度(秩),这里就是二维数组,
#最里面括着每一行的有一个方括号,后面又有一个,就是二维,四行
labels=['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k): #inX是你要输入的要分类的“坐标”,dataSet是上面createDataSet的array,就是已经有的,
#分类过的坐标,label是相应分类的标签,k是KNN,k近邻里面的k
dataSetSize=dataSet.shape[0] #dataSetSize是sataSet的行数,用上面的举例就是4行
diffMat=tile(inX,(dataSetSize,1))-dataSet #前面用tile,把一行inX变成4行一模一样的(tile有重复的功能,dataSetSize是重复4遍,
# 后面的1保证重复完了是4行,而不是一行里有四个一样的),然后再减去dataSet,
#是为了求两点的距离,先要坐标相减,这个就是坐标相减
sqDiffMat=diffMat**2 #上一行得到了坐标相减,然后这里要(x1-x2)^2,要求乘方
sqDistances=sqDiffMat.sum(axis=1) #axis=1是列相加,,这样得到了(x1-x2)^2+(y1-y2)^2
distances=sqDistances**0.5 #开根号,这个之后才是距离
sortedDistIndicies=distances.argsort() #argsort是排序,将元素按照由小到大的顺序返回下标,比如([3,1,2]),它返回的就是([1,2,3])
classCount={}
for i in range(k):
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1 #get是取字典里的元素,如果之前这个voteIlabel是有的,
#那么就返回字典里这个voteIlabel里的值,如果没有就返回0(后面写的),
#这行代码的意思就是算离目标点距离最近的k个点的类别,
#这个点是哪个类别哪个类别就加1
soredClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#key=operator.itemgetter(1)的意思是按照字典里的第一个排序,{A:1,B:2},要按照第1个(AB是第0个),即‘1’‘2’排序。reverse=True是降序排序
return soredClassCount[0][0] #返回类别最多的类别
输入以下语句进行测试:
group,labels=createDataSet()
classify0([0,0],group,labels,3)
返回B即为正确结果。
四、实战
1.使用K-近邻算法改进约会网站的配对效果
from numpy import *
import operator
from collections import Counter
import matplotlib
import matplotlib.pyplot as plt
###导入特征数据
def file2matrix(filename):
fr = open(filename)
contain = fr.readlines()###读取文件的所有内容
count = len(contain)
returnMat = zeros((count,3))
classLabelVector = []
index = 0
for line in contain:
line = line.strip() ###截取所有的回车字符
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]###选取前三个元素,存储在特征矩阵中
classLabelVector.append(listFromLine[-1])###将列表的最后一列存储到向量classLabelVector中
index += 1
##将列表的最后一列由字符串转化为数字,便于以后的计算
dictClassLabel = Counter(classLabelVector)
classLabel = []
kind = list(dictClassLabel)
for item in classLabelVector:
if item == kind[0]:
item = 1
elif item == kind[1]:
item = 2
else:
item = 3
classLabel.append(item)
return returnMat,classLabel#####将文本中的数据导入到列表
##绘图(可以直观的表示出各特征对分类结果的影响程度)
datingDataMat,datingLabels = file2matrix('E:\datingTestSet.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()
## 归一化数据,保证特征等权重
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))##建立与dataSet结构一样的矩阵
m = dataSet.shape[0]
for i in range(1,m):
normDataSet[i,:] = (dataSet[i,:] - minVals) / ranges
return normDataSet,ranges,minVals
##KNN算法
def classify(input,dataSet,label,k):
dataSize = dataSet.shape[0]
####计算欧式距离
diff = tile(input,(dataSize,1)) - dataSet
sqdiff = diff ** 2
squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5
##对距离进行排序
sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标
classCount={}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
###对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel,0) + 1
###选取出现的类别次数最多的类别
maxCount = 0
for key,value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes
##测试(选取10%测试)
def datingTest():
rate = 0.10
datingDataMat,datingLabels = file2matrix('E:\datingTestSet.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
testNum = int(m * rate)
errorCount = 0.0
for i in range(1,testNum):
classifyResult = classify(normMat[i,:],normMat[testNum:m,:],datingLabels[testNum:m],3)
print("分类后的结果为:,", classifyResult)
print("原结果为:",datingLabels[i])
if(classifyResult != datingLabels[i]):
errorCount += 1.0
print("误分率为:",(errorCount/float(testNum)))
###预测函数
def classifyPerson():
resultList = ['一点也不喜欢','有一丢丢喜欢','灰常喜欢']
percentTats = float(input("玩视频所占的时间比?"))
miles = float(input("每年获得的飞行常客里程数?"))
iceCream = float(input("每周所消费的冰淇淋公升数?"))
datingDataMat,datingLabels = file2matrix('E:\datingTestSet2.txt')
normMat,ranges,minVals = autoNorm(datingDataMat)
inArr = array([miles,percentTats,iceCream])
classifierResult = classify((inArr-minVals)/ranges,normMat,datingLabels,3)
print("你对这个人的喜欢程度:",resultList[classifierResult - 1])
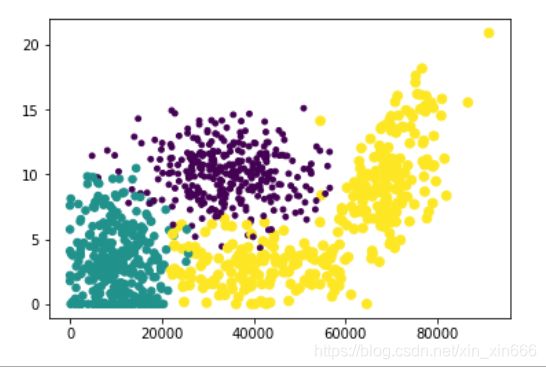
图中,紫色部分为极具魅力,绿色部分为魅力一般,黄色部分为不喜欢
横轴表示每年获取的飞行常客里程数
纵轴表示玩视频游戏所耗时间百分比

五、KD树
kd树是为了降低KNN的时间复杂度,提升其性能的一种数据结构,是一种二叉树,表示对K维空间的一个划分。 使用 kd树,可以对n维空间中的样本点进行存储以便对其进行快速搜索。构造kd树,相当于不断地用垂直于坐标轴的超平面将n维空间进行切分,构成一系列的n维超矩形区域。kd树的每一个节点对应于一个n维超矩形区域。
构造KD树算法
输入:K维空间数据集T
输出:KD树
-
开始:构造根节点,根节点对应于包含T的k维空间的超矩形区域
选择x为坐标轴,以T中所有实例的x坐标的中位数为切分点,将根节点对应的矩 形区域切分为两个子区域。切分由通过切分点并与坐标轴x垂直的超平面实现。
落在此切分超平面上的实例点就是根节点,左子节点对应着坐标小于切分点的子区域,右子节点对应着坐标大于切分点的子区域。 -
重复:还是以该区域所有实例坐标的中位数为切分点,重复步骤1.
-
直到两个子区域没有实例存在时停止,从而形成KD树划分。
伪代码
算法:构建k-d树(createKDTree)
输入:数据点集Data-set和其所在的空间Range
输出:Kd,类型为k-d tree
1.If Data-set为空,则返回空的k-d tree
2.调用节点生成程序:
(1)确定split域:对于所有描述子数据(特征矢量),统计它们在每个维上的数据方差。假设每条数据记录为64维,可计算64个方差。挑选出最大值,对应的维就是split域的值。数据方差大表明沿该坐标轴方向上的数据分散得比较开,在这个方向上进行数据分割有较好的分辨率;
(2)确定Node-data域:数据点集Data-set按其第split域的值排序。位于正中间的那个数据点被选为Node-data。此时新的Data-set' = Data-set \ Node-data(除去其中Node-data这一点)。
3.dataleft = {d属于Data-set' && d[split] ≤ Node-data[split]}
Left_Range = {Range && dataleft}
dataright = {d属于Data-set' && d[split] > Node-data[split]}
Right_Range = {Range && dataright}
4.left = 由(dataleft,Left_Range)建立的k-d tree,即递归调用createKDTree(dataleft,Left_Range)。并设置left的parent域为Kd;
right = 由(dataright,Right_Range)建立的k-d tree,即调用createKDTree(dataleft,Left_Range)。并设置right的parent域为Kd。
具体步骤:
① 待分类样本test_point,初始化best_dist为无穷大;
② 首先从根节点开始搜索,确定当前节点弄得,计算当前节点与test_point之间的距离;
③ 若当前节点与test_point之间的距离小于best_dist,则将当前节点与test_point之间的距离赋值给best_dist;
④ 确定当前节点的划分维度,即split;
⑤ 利用当前结点的划分阈值node.node_data[node.split]来向下搜索,若测试样本当前维的值test_point[split]小于当前节点阈值,则搜索左子树,否则,搜索右子树。
⑥ 采用递归的方式继续对左子树(或右子树)进行搜索,获得best_dist;
⑦ 至此,我们仅搜索了左子树(或右子树),另外一个子树是否要进行搜索呢?答案是需要的,因为我们并不能确定那边没有距离更近的样本点。
⑧ 那这样不是和暴力搜索没有差别了?当然不是!
⑨ 假设测试样本当前维值为test_point[split]=4, 当前结点当前维的值为node.node_data[node.split]=15,所以,我们搜索的是左子树,假设我们搜索完左子树得到的最短距离为best_dist=3, 那我们可以计算当前结点与测试样本在当前维的距离err_dist=node.node_data[split] - test_point[split], 若其大于best_dist,则不需要搜索右子树了,因为根据kd树的结构,右子树所有结点在当前维axis的值肯定大于10,则其与测试样本的距离肯定大于best_dist(因为test_point[split]是小于10的,且某一维度的差值大于best_dist,则其常用距离,不论是欧式或马氏距离,肯定是大于best_dist)。这样我们就可以舍弃一部分区域,从而缩小了搜索空间。
上述方法,将最近邻搜索的时间复杂度从暴力搜索的O(n)降低至O(log(n))基于kd树的最 近邻搜索 K近邻的搜索,其实是通过上述方法,构建长度为K的有界优先队列,保存和不断的更新当前搜索过程中与待分类样本点距离最近的K个样本点的即距离。
六、总结
1.KNN算法优缺点
优点:
① 简单,易于理解,易于实现,无需参数估计,无需训练;
② 对异常值不敏感(个别噪音数据对结果的影响不是很大);
③ 适合对稀有事件进行分类;
④ 适合于多分类问题(multi-modal,对象具有多个类别标签),KNN要比SVM表现要好;
缺点:
① 对测试样本分类时的计算量大,内存开销大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本;
② 可解释性差,无法告诉你哪个变量更重要,无法给出决策树那样的规则;
③ K值的选择:最大的缺点是当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进;
④ KNN是一种消极学习方法、懒惰算法。
2.KNN性能问题
KNN的性能问题也是KNN的缺点之一。使用KNN,可以很容易的构造模型,但在对待分类样本进行分类时,为了获得K近邻,必须采用暴力搜索的方式,扫描全部训练样本并计算其与待分类样本之间的距离,系统开销很大。
作者:小新新
来源:CSDN
版权声明:本文为博主原创文章,转载请附上博文链接!欢迎转载!
参考文献:
[1]《机器学习实战》的第二章内容
[2] 《统计学习方法(李航)》