对话系统 | (4) 任务型对话系统基础
本篇博客内容主要来自第十四届中国中文信息学会暑期学校暨中国中文信息学会《前沿技术讲习班》— 张伟男、车万翔《任务型对话系统》
PPT下载链接
文章目录
- 1. 任务型对话系统概述
- 2. 任务型对话系统关键技术
- 自然语言理解
- 对话管理
- 对话状态追踪
- 对话策略优化
- 自然语言生成
- 端到端任务型对话系统
- 3. 评价方法与评测任务
- 4. 总结和趋势展望
1. 任务型对话系统概述
- 人机对话系统四大功能/分类

2. 任务型对话系统关键技术
- 任务型对话系统结构


自然语言理解

- 领域与意图识别
是一个分类问题。
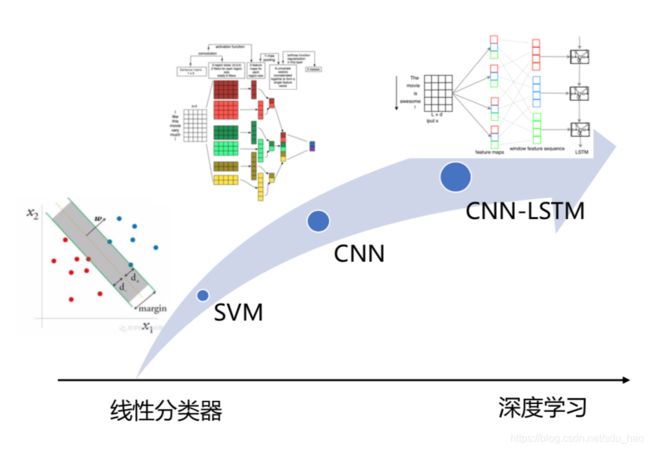
- 语义槽填充
是一个序列标注任务。

- 研究热点
- 意图识别与槽填充联合学习
- 语境相关的自然语言理解
- 基于小样本学习的自然语言理解
(一) 意图识别与槽填充联合学习
1)意图识别与槽填充不是相互独立而是紧密联系的;
2)传统独立的建模意图识别和槽填充,既会引出错误级联, 也无法利用共有的知识。
例如:如果这句话意图是 WatchMovie,那么这句话包含的 Slot槽值应该是电影相关而不是音乐相关。

共享编码的双任务学习
Xiaodong Zhang and Houfeng Wang. 《A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding》 IJCAI2016.
1)首次使用RNN-based (GRU)的方法联合建模意图识别和槽填充任务
2)GRU的每一个时刻出来的向量进行槽填充任务(序列标注)
3)GRU编码句子后通过max- pooling层得到该句的表示进行意图识别
4) 通过共享的GRU层来进行两个任务的联合学习,从而隐式的学习两者的关系

序列标注as解码问题
Bing Liu and Ian Lane. 《Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling》 [Interspeech 2016]
1)首次将Sequence-to-Sequence+Attention的方法用到了联合建模意图 识别和槽填充任务上,并达到了2016年的SOTA结果
2)还是采取共享的序列编码Encoder来联合隐式学习两个任务的关系

用意图控制槽填充
Chih-Wen Goo, Guang Gao. et al. 《Slot-Gated Modeling for Joint Slot Filling and Intent Prediction.》 NAACL2018.
1)首次利用Slot-gate 机制来显式的建模了槽填充任务和意图识别任务之间的关系
2)g越大,表示Intent和Slots的关系越大

用意图辅助槽填充
Changliang Li, Liang Li and Ji Qi. 《A Self-Attentive Model with Gate Mechanism for Spoken Language Understanding.》 EMNLP2018.
1)使用Gate机制利用信息来指导槽填充任务的进行,显式的利用了 Intent的信息。
2) 首次探索了自注意力机制在该任务上的作用,并取得了好的性能

总结

基于Stack-propagation的联合学习
《A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding》 EMNLP2019
1)一种多任务学习框架
2)任务之间有层次依赖关系


(二)语境相关的自然语言理解

-
任务核心关注点
1)哪些历史对话轮次可以帮助当前轮次对话的理解?
2)这些历史对话对当前对话传递了哪些有用的信息?

-
联合训练领域识别、意图分类和槽填充
-
历史对话状态和当前轮次表示经过非线性变换以预测当前轮次领域,意图,槽。
Yangyang Shi et al., 《Contextual Spoken Language Understanding Using Recurrent Neural Networks》, IEEE International Conference on Acoustics, Speech and Signal Processing, 2015
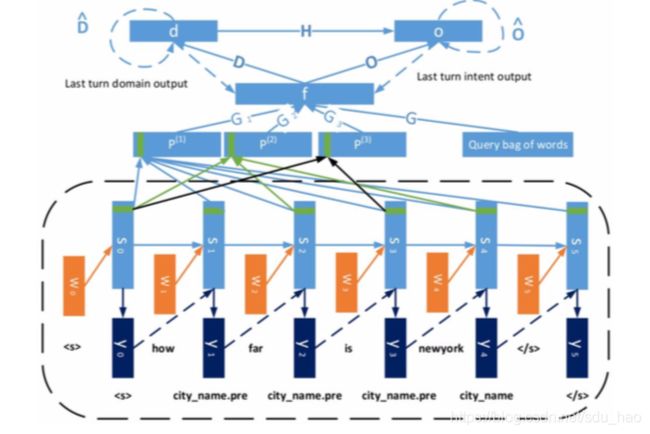
-
利用端到端记忆网络对历史对话进行表示,学习到的表 示作为槽填充模型输入的一部分
Yun-Nung Chen et al., 《End-to-End Memory Networks with Knowledge Carryover for Multi-Turn Spoken Language Understanding》, INTERSPEECH 2016
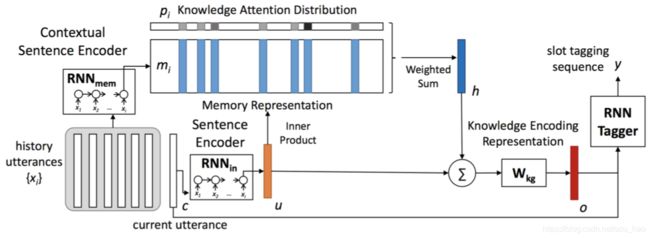
-
利用递归神经网络对历史对话进行编码,融合时序信息
-
输入的历史对话表示与当前对话表示经过前向网络进行融合
Ankur Bapna et al., 《Sequential Dialogue Context Modeling for Spoken Language Understanding》, SIGDIAL 2017

-
在记忆网络中加入了时间、用户角色注意力机制
Yun-Nung Chen et al., 《Dynamic Time-Aware Attention to Speaker Roles and Contexts for Spoken Language Understanding》, ASRU 2017

-
在记忆网络中加入了衰退注意力机制
离得越近,影响越大。
Shang-Yu Su et al., 《Learning Time-Decay Attention for Contextual Spoken Language Understanding in Dialogues》, NAACL 2018

-
将对话逻辑推理和自然语言理解进行多任务学习,对话逻辑推理作为辅助任务帮助学习对话历史更好的表示。
He Bai et al., 《Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference》, ACL 2019

(三)基于小样本学习的自然语言理解
- 背景
1)深度学习方法很成功,但是需要大量的标注数据
2)人类非常擅长通过极少量的样本识别一个新物体,
比如小孩子只需要少量的图片就可以认识什么是斑马,什么是犀牛。
我们希望模型也可以利用领域外经验和小量样本进行学习
3) 真实应用往往需要频繁适应新的领域和新需求
新的领域数据不足;
新的标签类别;
频繁重新训练的开销往往难以接受的
小样本学习(few-shot learning)
小样本学习是专门解决前面提到问题的机器学习分支

-
K-way N-shot 分类任务
1)支持集(Support Set):K类别,N实例
2)查询集(Query Set):未见类别

-
方法分类
1)Model相关的方法:设计适用于小样本的模型架构
2)Metric/distance/similarity Based方法:利用样本间距离度量来预测新数据类别
3)Optimization Based方法:学习多任务通用初始化参数或者参数更新方法
小样本学习 - Metric Based方法
-
背景
1)基于参数学习的方法往往无法避免地会过拟合到小样本上
2)相反,很多非参数化的方法(最近邻、K-近邻、Kmeans)是不需要优化参数的,因此可以避免过拟合 -
Metric Based 方法
1)对样本间距离分布进行建模,使得同类样本靠近,异类样本远离
2) Metric与类别无关,可以轻松泛化到新的类别和任务上 -
孪生网络(Siamese Network)
Koch, Gregory, Richard Zemel, and Ruslan Salakhutdinov. 《“Siamese neural networks for one-shot image recognition.”》 ICML 2015.
通过有监督的方法学习两个样本的相似性,在新任务上重用特征提取器以实现小样本分类。

-
匹配网络(Match Network)
Oriol Vinyals, Charles Blundell, Tim Lillicrap, Daan Wierstra, et al. 《Matching networks for one shot learning.》 Nips 2016.
为支撑集和Query集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。

-
原型网络(Prototype Network)
Snell, Jake, Kevin Swersky, and Richard Zemel. 《“Prototypical networks for few-shot learning.” 》Nips 2017.
1) 每个类别都存在一个原型表达,该类的原型是 support set 在embedding 空间中的均值。
2)分类问题变成在 embedding 空间中的最近邻。

-
关联网络 (Relation Network)
Sung, Flood, et al. 《“Learning to compare: Relation network for few-shot learning.”》 CVPR 2018.
用回归的方式直接建模样本距离。

小样本学习 - 对话 & 自然语言处理中的应用
-
文本分类(意图实别)
Geng R, Li B, Li Y, et al. 《Few-Shot Text Classification with Induction Network》[J]. 2019.
Induction Network;融合了关联网络和原型网络;原型embedding的得到由简单取平均部分换成了胶囊网络的计算。

-
序列标注(命名实体实别)
Fritzler A, Logacheva V, Kretov M. 《Few-shot classification in named entity recognition task 》ACM/SIGAPP 2019
Prototypical NER Network;
把每个词看成独立的样本;使用原型网络独立地对每个词分类;在目标域学习CRF参数。

基于小样本的语义槽填充
《Few-shot Slot Tagging with Collapsed Dependency Transfer and Label-enhanced Task-adaptive Projection Network》 -
如何将小样本学习应用于语义槽标注?
典型的序列标注任务:语义槽标签之间互相影响

-
我们利用CRF模型来建模小样本的序列标注问题
发射概率: 利用metric based方法建模emission score
转移概率: 提出一种回退机制,建模未见标签的转移概率 -
发射概率:测试集与支持集中词语之间的相似度
使用BERT计算。

-
转移概率:标签之间的转移概率
1)目标任务或领域标签与原任务不一致
2)回退到BIO标签,在原领域中统计

标注数据的自动扩充
Yutai Hou, Yijia Liu, Wanxiang Che and Ting Liu. 《Data Augmentation for Dialogue Language Understanding.》 COLING 2018.
- 动机
1)对话技术平台需要用户上传大量的标注数据
2)能否帮助用户自动扩充标注数据,减小标注工作量?

- 模型
Seq2Seq模型;相似的训练数据构成“复述”对

- 样例

对话管理
对话状态追踪
什么是对话状态?
对话状态是人机对话过程中,用户目标(Goal)的达成状态。

什么是对话状态追踪?
对话状态追踪即对话状态估计
例子中对话状态挺明确的,为什么对话状态需要估计?

传统的对话状态追踪方法
Young S , Ga?I? M , Keizer S , et al. 《The Hidden Information State model: A practical framework for POMDP- based spoken dialogue management[J].》 Computer Speech and Language, 2010, 24(2):150-174.
Markov Decision Process (MDP)的方法

Partially Observed MDP (POMDP)的方法


基于深度神经网络的对话状态追踪
多层感知机用于估计和表示对话状态
M. Henderson, B. Thomson and S. Young (2013). 《“Deep Neural Network Approach for the Dialog State Tracking Challenge.”》 SigDial 13, Metz, France.

基于循环神经网络的对话状态追踪
M. Henderson, B. Thomson and S. Young (2014). “Word-Based Dialog State Tracking with Recurrent Neural Networks.” SigDial 2014, Philadelphia, PA.
利用RNN建模对话状态分布;同时建模Slot之间的关联和对话历史

优点:1)n-gram特征;2)slots之间关联;3)对slot保留value 的分布;4)能够通过泛化 来处理未见实例。
缺点:1)单一领域;2)仍然需要特征工程。
多领域对话状态追踪
N. Mrksic, D. O’Seaghdha, B. Thomson, M. Gasic, P-H. Su, D. Vandyke, T-H. Wen and S. Young (2015). 《“Multi-domain Dialog State Tracking using Recurrent Neural Networks.”》 ACL 2015, Beijing.
利用非词表示的特征进行不同领域的迁移学习;
尽管非词表示(Delexicalized)的特征相同,但特定slot模型对相同特征的权重不同。

优点:1)Lexical+Delexical特征;2)层次化训练实现多领域对话状态追踪
缺点:1)仅在RNN基础上的多阶段训练,严重依赖特征;2)人工定义词汇特征,应 对用户不同的表达方式。
数据驱动的神经置信追踪
N. Mrksic, D. O Seaghdha, T.-H. Wen, B. Thomson and S. Young (2017). 《“Neural Belief Tracker: Data-Driven Dialogue State Tracking.”》 ACL 2017, Vancouver, Canada
- 动机
人工构造的表达slot-value的词典用来匹配用户输入的语义,从而得到slot级别的对话状态表示。

- 借助分布式语义表示学习的优势
无需借助人工构造的词典;语义表示更精确、匹配效果更好。
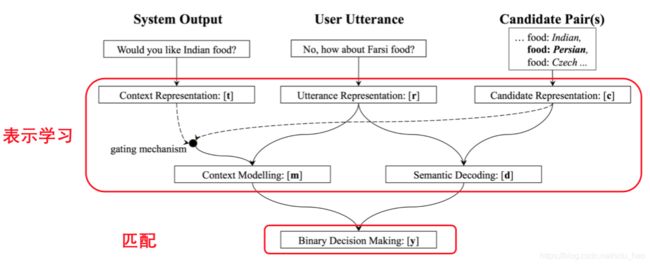
- NBT有什么问题?
句子级的Slot-value对形式的对话状态表示,没有考虑对话历史的置信状态信息;
整体的置信状态更新,采用启发式的方式。

完全可统计学习的NBT
Mrkšić, Nikola, and Ivan Vulić. 《“Fully Statistical Neural Belief Tracking.”》 Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018. - 基于学习的置信更新机制
考虑到对话历史轮次(比如上一轮)的全部slot-value对的置信状态分布;可学习 v.s. 启发式

- 不同领域的槽值可以共享信息
Ramadan, Osman, et al. 《“Large-Scale Multi-Domain Belief Tracking with Knowledge Sharing.”》 In Proc. of ACL 2018.
比如机票、火车票、船票等领域可能共享地点、时间等槽;
能否计算领域无关的槽-值联合概率?
由二元组的二分类变为三元组二分类。

可迁移的对话状态跟踪
Chien-Sheng Wu, et al. 《Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems》 (ACL 2019) - 动机
工业上,往往只可以得到包含槽类型的API,具体的槽值往往是不得而知的。
已有方法假设Ontology存在,但是面临实践中槽值太多,模型太大的问题。
模型无法部署到不同的ontology的domain中。 - 方法
采用带copy机制生成的方式来预测语义槽值(value)。
使用了Slot gate来判断槽当前是:有效 or 未提及 or 不关心。

跨语言对话状态追踪
Chen, Wenhu, et al. 《“XL-NBT: A Cross-lingual Neural Belief Tracking Framework.”》 In Proc. of EMNLP 2018.
目标语言无训练数据。
对训练目标进行分解。
利用双语语料和双语词典从源语言迁移。

对话状态追踪:小结

对话策略优化
什么是对话策略?


基于规则的对话策略
- MIT-ATIS对话系统状态控制流程
对话动作与对话状态绑定成特定序列;
对话策略以对话状态的入栈/出栈的形式配以相应的对话动作实现。

优势:特定领域中效果较好,系统稳定;
劣势:动作序列相对固定;算法与对话过程绑定, 修改算法即修改对话过程;无法应对规定动作外的 用户输入。
基于有限状态自动机的对话策略

基于表格(Form)的对话策略
E-Form是Semantic Frame的一种表示形式。

基于脚本的对话策略
- MIT Galaxy II系统
基于脚本语言实现对话流的控制;对话流即对话动作序列。
优势:任务扩展方便;多层对话管理机制逻辑清晰
劣势:手工定义规则;对话流控制需要预设,对话控制不够灵活
上述对话策略的特点总结
- 对话动作之间独立或局部依赖
- 不对整体的对话动作序列进行建模
- 对话策略的输出仅是下一个动作
基于规划的对话策略
- 规划(Planning):通过创建一个动作序列来实现某个目标的求解方法,并尝试预测执行该规划的效果 (Wasson, 1990)。

- 层次化规划方法

以上方法存在的问题 - 对系统错误敏感,鲁棒性差
- 对话策略相对固定,灵活度不够
- 策略和任务绑定,很难在任务间迁移
概率对话管理模型

强化学习与对话管理的对应关系


-
Human-in-the-loop
用户参与到对话过程中,产生反馈信号(用户对于对话的评价),帮助训练模型。 -
对话奖励函数
任务型对话的目标是使用尽可能少的轮次完成用户任务。
对话成功将被赋予较高的奖励(依赖于预设对话轮次目标)。

-
利用概率模型建模对话管理

-
假设:下一轮的对话动作和状态仅依赖当前的对话状态
-
MDP基本要素



为什么对话策略需要优化? -
对话的状态-动作(State-action)空间非常大!
-
精确估计状态间的转移函数非常难!

基于动态规划的对话策略优化 -
基本思想
对于一个给定的初始对话策略,扫描整个对话状态-动作空间,从而递归地估计值函数;
当值函数被计算出来之后,更新初始对话策略为当前对话策略;
重复此过程直至收敛。 -
典型算法

基于采样的对话策略优化 -
动机
尽管基于DP的对话策略优化方法可以通过缩小状态空间表示来 缓解对话状态-动作的空间,然而其基本假设仍然是搜索整个状态空间;
基于采样的方法可以只关注最优和近似最优对话所对应的状态序 列,无需对整个状态空间的探索即可建模对话状态的转移。 -
采样方法的过程

-
Q函数更新

以上方法总结 -
DP算法能够探索整个对话状态-动作空间,理论上能够得到全局最优解,但速度慢
-
采样方法通过搜索最优对话状态序列实现对话状态的转移建模,求解速度快,但不保证全局最优
-
采样方法在实际应用中需要多次采样对话状态转移序列, 而理论上有真实用户参与的在线学习方式,在实际中并 不“实际”
基于用户模拟器的对话策略学习
- 动机
通过用户在线学习对话策略,成本极高;
模拟用户行为进行对话状态-动作空间的探索;
探索范围大,试错成本低。

对话策略优化前沿进展
- 对话策略优化的方向
更简单的对话策略;
更优的Q函数学习;
更客观的奖励函数;
更真实的对话模拟。
神经网络框架下的对话管理
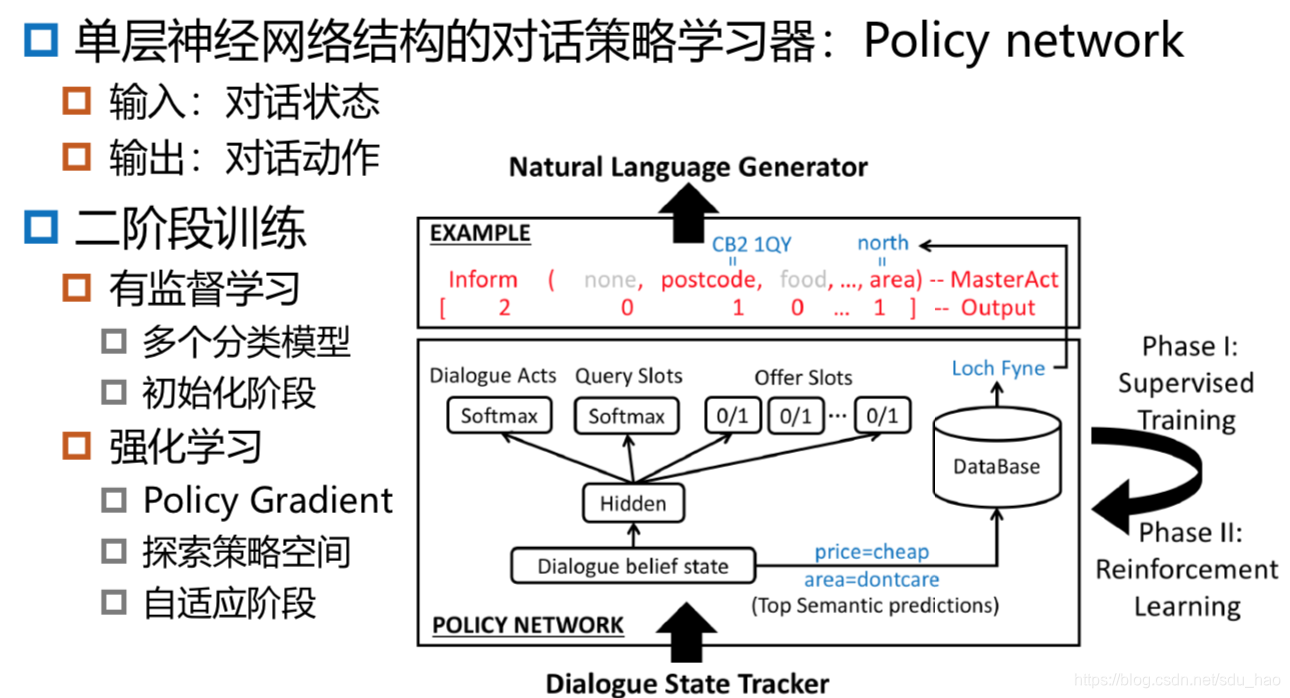
深度Q值网络:DQN
- 利用深度神经网络近似计算Q函数
常用的简单有效的深度神经网络为多层感知机(MLP);
对话策略的学习形式为前馈全连接网络,从而变得更加简单。

奖励函数学习
- 已有对话奖励的特点
对话成功奖励,忽略对话过程的重要性;
真实的、高质量的用户反馈很难获取。

Human-in-the-loop的用户模拟器

自然语言生成

- 从对话动作到自然语言语句的映射

- 自然语言生成的主要步骤
1)文本规划:生成句子的语义帧序列
2)句子规划:生成关键词、句法等结构信息
3)表层规划:生成辅助词及完整的句子
基于模版的自然语言生成
- 人人都能想到的方法

- 特点:简单、机械、成本高,有多少人工就有多少智能
基于规划的自然语言生成
- 流水线式规划生成自然语言语句
Rambow, Owen, Srinivas Bangalore, and Marilyn Walker. 《“Natural language generation in dialog systems.” Proceedings of the first international conference on Human language technology research.》 Association for Computational Linguistics, 2001.

基于统计学习的自然语言生成
Oh, Alice H., and Alexander I. Rudnicky. 《“Stochastic natural language generation for spoken dialog systems.”》 Computer Speech & Language 16.3-4 (2002): 387-407.

基于神经网络的自然语言生成 - 基于RNN语言模型的自然语言生成
T-H. Wen, M. Gasic, D. Kim, N. Mrksic, P-H. Su, D. Vandyke and S. Young (2015). 《“Stochastic Language Generation in Dialogue using Recurrent Neural Networks with Convolutional Sentence Reranking.”》 Sigdial 2015, Prague, Cz.

- 基于LSTM语言模型的自然语言生成
T-H. Wen, M. Gasic, N. Mrksic, P-H. Su, D. Vandyke and S. Young (2015). <“Semantically Conditioned LSTM-based Natural Language Generation for Spoken Dialogue Systems.”> EMNLP 2015, Lisbon, Portugal.

端到端任务型对话系统

端到端生成式对话模型
- 基于层次化循环神经网络的编码解码模型
Serban, Iulian V., et al. 《“Building end-to-end dialogue systems using generative hierarchical neural network models.”》 Thirtieth AAAI Conference on Artificial Intelligence. 2016.
1) EncoderRNN编码对话历史句子(Intra utterance)
2)句子内使用双向RNN建模句子语义表示(Inner utterance)

基于神经网络的端到端任务型对话模型
Wen, Tsung-Hsien, et al. 《“A network-based end-to-end trainable task-oriented dialogue system.”》 arXiv preprint arXiv:1604.04562 (2016). - 模型特点

基于强化学习的端到端任务型对话
Li, Xiujun, et al. 《“End-to-end task-completion neural dialogue systems.”》 arXiv preprint arXiv:1703.01008 (2017). - 端到端的强化学习训练
各个部分是独立的NN模型

端到端任务型对话系统总结 - 任务型对话系统的基本框架没有变
- 利用神经网络代替人工经验和干预的部分
- 每个模块(Modular)统计化、学习化
- 模块之间的联系仍然存在且重要
- 完全端到端的任务型对话系统目前不存在(?)
3. 评价方法与评测任务
任务型对话系统的评价

任务型对话系统的整体评价指标

NLU的评价

DM的评价
- 对话状态追踪
单轮对话句子的动作识别;
多轮对话片段的状态信息识别,例如:主题、对话行为、对话类型等 - 对话策略优化
对话成功率;对话奖励函数评价
NLG的评价

4. 总结和趋势展望
- 总结

- 展望

