flink1.11 学习篇--DataStream API
什么能被转化成流?
Flink 的 Java 和 Scala DataStream API 可以将任何可序列化的对象转化为流。Flink 自带的序列化器有
- 基本类型,即 String、Long、Integer、Boolean、Array
- 复合类型:Tuples、POJOs 和 Scala case classes
而且 Flink 会交给 Kryo 序列化其他类型。也可以将其他序列化器和 Flink 一起使用。特别是有良好支持的 Avro。
Java tuples 和 POJOs
Flink 的原生序列化器可以高效地操作 tuples 和 POJOs
Tuples
对于 Java,Flink 自带有 Tuple0 到 Tuple25 类型。
Tuple2 person = Tuple2.of("Fred", 35);
// zero based index!
String name = person.f0;
Integer age = person.f1; POJOs
如果满足以下条件,Flink 将数据类型识别为 POJO 类型(并允许“按名称”字段引用):
- 该类是公有且独立的(没有非静态内部类)
- 该类有公有的无参构造函数
- 类(及父类)中所有的所有不被 static、transient 修饰的属性要么是公有的(且不被 final 修饰),要么是包含公有的 getter 和 setter 方法,这些方法遵循 Java bean 命名规范。
public class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
. . .
};
}
Person person = new Person("Fred Flintstone", 35);
Scala tuples 和 case classes
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.api.common.functions.FilterFunction;
public class Example {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream flintstones = env.fromElements(
new Person("Fred", 35),
new Person("Wilma", 35),
new Person("Pebbles", 2));
DataStream adults = flintstones.filter(new FilterFunction() {
@Override
public boolean filter(Person person) throws Exception {
return person.age >= 18;
}
});
adults.print();
env.execute();
}
public static class Person {
public String name;
public Integer age;
public Person() {};
public Person(String name, Integer age) {
this.name = name;
this.age = age;
};
public String toString() {
return this.name.toString() + ": age " + this.age.toString();
};
}
} Stream 执行环境
每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
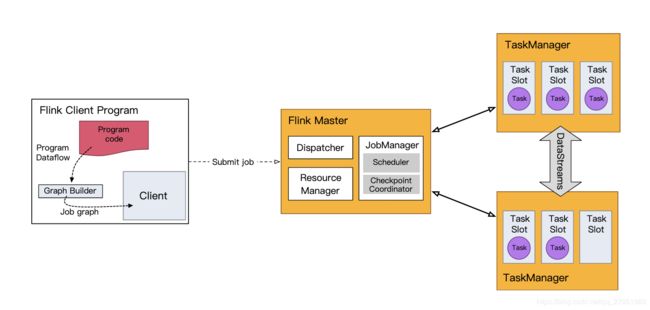
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
注意,如果没有调用 execute(),应用就不会运行。
基本的 stream source
上述示例用 env.fromElements(...) 方法构造 DataStream 。这样将简单的流放在一起是为了方便用于原型或测试。StreamExecutionEnvironment 上还有一个 fromCollection(Collection) 方法。因此,你可以这样做:
List people = new ArrayList();
people.add(new Person("Fred", 35));
people.add(new Person("Wilma", 35));
people.add(new Person("Pebbles", 2));
DataStream flintstones = env.fromCollection(people); 另一个获取数据到流中的便捷方法是用 socket
DataStream lines = env.socketTextStream("localhost", 9999) 或读取文件
DataStream lines = env.readTextFile("file:///path"); 在真实的应用中,最常用的数据源是那些支持低延迟,高吞吐并行读取以及重复(高性能和容错能力为先决条件)的数据源,例如 Apache Kafka,Kinesis 和各种文件系统。REST API 和数据库也经常用于增强流处理的能力(stream enrichment)。
基本的 stream sink
上述示例用 adults.print() 打印其结果到 task manager 的日志中(如果运行在 IDE 中时,将追加到你的 IDE 控制台)。它会对流中的每个元素都调用 toString() 方法。
输出看起来类似于
1> Fred: age 35
2> Wilma: age 35
1> 和 2> 指出输出来自哪个 sub-task(即 thread)
In production, commonly used sinks include the StreamingFileSink, various databases, and several pub-sub systems.
调试
在生产中,应用程序将在远程集群或一组容器中运行。如果集群或容器挂了,这就属于远程失败。JobManager 和 TaskManager 日志对于调试此类故障非常有用,但是更简单的是 Flink 支持在 IDE 内部进行本地调试。你可以设置断点,检查局部变量,并逐行执行代码。如果想了解 Flink 的工作原理和内部细节,查看 Flink 源码也是非常好的方法。