
前言
当我们谈起分布式系统,我们就不可避免的谈论CAP理论,所谓CAP理论指的是在分布式系统的设计中,没有一种设计可以同时满足 Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)3个特性,这三者不可得兼. CAP中的C指的就是我们今天要谈论的线性一致性(linearizability )或者叫强一致性.
我们常常讲Raft和Paxos是一个强一致的复制协议,不过这里存在一些微妙的区别,要实现线性一致性,在共识算法的基础上我们仍然需要做许多工作.
本篇文章我们会讨论线性一致性以及CockroachDB的实践和优化.
线性一致性
什么是线性一致性,在回答这个问题之前,我们先看一个案例.
李雷和韩梅梅在各自的家里同时收看里约奥运会中国女排对战塞尔维亚的决赛直播,最后中国女排3:1战胜对手,获得冠军,李雷打电话给韩梅梅,告诉她这个好消息,但是韩梅梅说我这里比赛还没有结束呢.显然这个结果是不符合我们预期的,实际上它也不是符合线性一致性的。对 韩梅梅来说,他希望看到的结果应该是和 李雷一样最新的比赛结果,而不是一个旧的结果。
分布式系统通常会是多个副本,那么多个副本复制会存在延迟 ,因此我们从不同的副本看到的数据就存在不一致, 线性一致性的基本的想法是让一个系统看起来好像只有一个数据副本,而且所有的操作都是原子性的。有了这个保证,即使实际中可能有多个副本,应用也不需要担心它们。
从client的视角来看,线性一致性系统需要满足如下约束:
单个client上操作都是顺序的,即一个操作执行结束后才开始下一个操作,没有并发.
多个client如果存在并发,那么可能返回旧值也可能返回新值.
任何一个客户端返回新值之后,以后所有的读取(所有的客户端)都将返回新值.
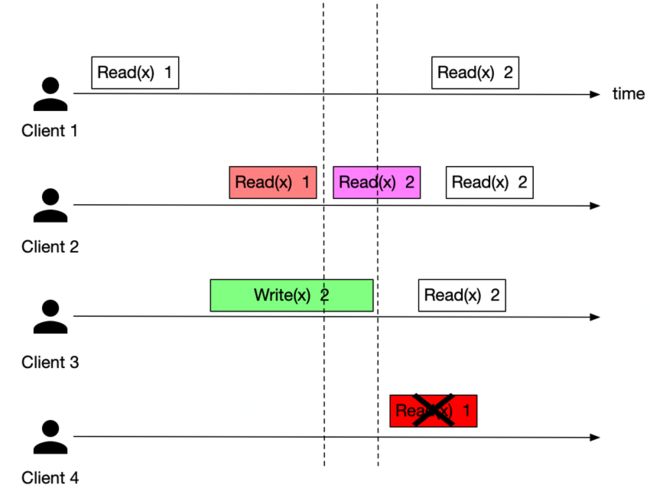
如上图所示, client 4就不满足线性一致性.
Raft
Raft是一个强一致的共识算法,它有三种角色:领导者(Leader),选举候选人(Candidate),跟随者(Follower),任何时候只有Leader有权利向raft group的其他成员复制日志,即数据流向永远都是从Leader流向Follower,并且日志都是顺序复制,顺序确认,顺序应用.因此对于写操作,Raft满足线性一致性.
对于读操作,稍微麻烦一些,主要是因为Raft存在Leader切换,脑裂的问题.存在三种一致性读取方法.

Raft log read
这种方案跟写操作没什么区别,所有的读操作也需要提交raft log,所有的副本都需要执行读操作.这样所有的读操作可以满足线性一致性,但是问题是存在日志复制和提交的开销,读写操作会相互干扰,造成性能不足.
ReadIndex
Read Index不需要raft log复制,但是执行读操作之前需要确认当前的Leader是否仍然是Leader,因此执行之前Leader需要主动向其他成员发送一次心跳来确认自己仍然是Leader.因为存在脑裂的问题,导致读到脏数据.
Leader 节点执行 ReadIndex 的流程如下:
记录当前的 commit index,称为 ReadIndex
向 Follower 发起一次心跳,如果收到大多数节点回复,那就能确定当前节点仍然是Leader节点.
等待状态机至少应用到 ReadIndex 记录的 Log
执行读请求,将结果返回给 Client
这里面有两个关键点,一个是记录当前的commit index而不是apply index,这是因为存在这样一种场景,当发生leader切换的时候,虽然新的leader拥有之前leader所有的已经commit的日志,但是两者的applyindex可能不同,因此只有使用commit index当作read index才能保证读取的线性一致性,另一个关键点是等待状态机至少应用到read index才执行读操作,这里的道理是不言自明的.
对于read index我们也可以从follower上执行读操作,在读之前follower先向leader要一下当前的commit index(当然leader需要发心跳确认自己当前仍然是leader),然后在follower上等待状态机应用到至少read index位置,开始执行读操作. ETCD就是采用这种方式实现一致性读.
ReadIndex不需要复制日志,对写操作没有什么干扰,但是仍然需要额外的网络开销,因此延迟还是比较大.
Lease Read
Lease Read的基本思想是避免Leader发送额外的心跳来确认身份,它使用lease,这个lease比选举超时时间要小,这样可以保证lease期内保证不会发生选举,因此就没有发送心跳确认身份的必要了,这样可以大幅提升读的吞吐,降低延迟.
我们可以看到leaseread严重依赖物理时间,但是在分布式系统中,各个节点的物理时钟存在偏差,因此如果偏差太大,那么这个机制就存在风险.
进化
CockroachDB使用raft共识算法保证range的多个副本之间数据的强一致,对于一致性读操作,前面提到的在raft上基于raft的一致性读方案都不能满足需求.因此CockroachDB引入了range lease.
Lease read的思路类似于Raft Lease Read,但是它解决了因为系统各个节点存在时钟偏差导致不能保证完全线性一致性的问题.Lease 是一个时间片(默认9秒钟),当时间片消耗超过一个阈值(默认是7.2秒)lease holder就会主动续租.Lease设计的一个要点就是需要充分考虑节点之间的时间偏差,因此每次续租,都会更新变更lease holder的最小时间戳,这个时间戳要大于lease timeout timestamp + max timeoffset(最大时钟偏差).这样保证不会出现同时存在多个leaseholder的情况.
CockroachDB节点之间会交叉校验时钟偏差,如果某个节点的时钟偏差大太,那么就会从集群中剔除,因此可以保证不会有节点的时钟偏差超过集群配置的最大时钟偏差(默认是300ms).
从上面章节的论述中,我们看到对于一个需求存在很多种解决方案,这些解决方案各有优劣,其实无论是社会,经济,政治,法律,甚至包括计算机,其中很多的制度,规则,变革的思路都充满了经济学.其中最基本的就是成本收益分析.在计算机领域我们讨论一种解决方案是否妥当,我们也是会讨论成本和收益,这一点随处可见,比如CPU 高速缓存,page cache,指令水流线,超线程技术,数据压缩等等.并且这些都是一段迭代进化的结果,我们去看早起的计算机相关的论文,比如笔者最近正好研究分布式事务框架OCC,就会看到现在看起来并不那么难以理解的逻辑也是经历了几代计算机科学家的努力,演进,优化才达到今天比较成熟的地步,并且这个过程还在继续.经济学上有一个经典的定理叫科斯定理,它说如果交易成本足够低,那么一种资源谁用的好就归谁.这个理论在计算机中如何体现的呢?举个例子吧,内存数据库Redis,它把数据都存储在内存中,只要我们因为高速读写带来的增益大于内存的成本,那么把内存作为数据存储的介质就合情合理.
因此本篇文章主要就是阐述CockroachDB在线性一致性问题上如何选择和进化,以及其内在的经济学逻辑.
Range Lease
如前所述,每一个range的lease holder都会定期向其他副本更新lease,那么对于拥有10000个range(CockroachDB的range默认64MB)table,每秒就有1388次raft日志提交,这是一个很客观的系统开销,并且随着table size的增加range数量也线性增加,比如达到100000个range,每秒就有超过13880次raft提交,对于一个用于100000个range的table来说,它的大小才只有6.4TB,而CockroachDB的设计目标是要支持最大4EB的存储规模,因此这种lease开销就非常大,足以压垮整个系统,lease请求和raft心跳不同,对于raft来说它是一条写命令,因此还需要Apply.
所有的读写都必须由range lease holder负责,但是range lease holder和range raft leader并不是同一个节点.对于读操作没什么,但是写操作就会多一次RPC,因此CockroachDB在提交raft提案的时候如果发现两者不一致,会强制发起transfer leader,保证两个角色在同一个节点上.
因此虽然Rangelease解决了原来Raft Lease read时钟漂移的问题,但是增加了系统负担,并且这种负担随着集群规模扩大而扩大,因此我们需要优化.优化的思路就是减少lease请求.我们注意到集群的节点数量通常相对于range数量要小好几个数量级,一般也就十几台,几百台的规模,只要节点是健康的,那么我们是否可以以更新节点的健康状况,或者也可以理解为Node lease代替Range lease的各自独立的更新呢?
答案是肯定的.
Node Lease
CockroachDB 内部维护了一张Node liveness table,结构如下:

每个节点定期更新自己的Node lease. Node lease的更新逻辑和之前的Range lease一样,这里就再赘述.我们在原来的Range lease中增加了epoch,即Node lease holder的lease epoch,那么如何判断一个range lease holder是否仍然持有lease呢,只要range leaseholder所在Node的lease没有过期,并且range lease中的epoch和node lease中epoch一样,并且Node lease的超时时间要大于读写请求的时间戳+Max time offset,否则返回特定的错误,拒绝执行读写请求.
Range并不需要定期主动更新lease,当执行读写请求之前,首先需要确认当前副本是否是lease holder,如果是,即满足上述的lease条件,那么允许执行操作,如果range lease已经过期,那么检查当前的Node lease,如果epoch一样,说明仍然持有lease,此时需要主动向所有副本更新lease, lease update是一条raft log,各个副本应用lease update请求后,完成租约更新,此时读写命令才可以执行.因此我们可以看到如果一个range一直没有读写访问,那么就无需更新租约,这样确实可以减少很多不必要的开销.
如果有节点失效了,那么等range lease过期之后,因为新的读写请求引起发现续约失败,那么就会重新选择合适的range lease holder,通过transfer lease消息向所有的副本更新新的lease.
CockroachDB允许因为负载均衡等触发的主动transfer lease.
当发生leaseholder transfer时,新的range lease holder是在应用完新的lease update之后才会生效,lease update本身也是一条raft log, raft log的应用是顺序应用,因此当新的租约生效的时候,前一个lease holder产生的写请求都已经在新的lease holder上应用完成了,因此可以保证数据的一致性.