Python计算机视觉编程(八)图像检索
图像检索
- BOW模型
- 基于BOW的图像检索
- 特征提取
- 视觉词典
- TF-IDF
- 常用参数
- 图像检索
- 具体实现流程
BOW模型
Bag-of-words models模型(词袋模型)
词袋模型对于给定的两个文档,进行分割可以建构出一个有n个元素词典,根据词典每个词在两个文档中的出现的频率,表示成两个n维向量。
基于BOW的图像检索
- 特征提取
- 学习视觉词典
- 针对输入特征集,根据视觉词典进行量化
- 把输入图像,根据TF-IDF转化成视觉单词的频率直方图
- 构造特征到图像的倒排表,通过倒排表快速索引相关图像
- 根据索引结果进行直方图匹配
特征提取
采用sift提取特征,以前的博客有具体的描述,就不再提及
视觉词典
-
使用K-meas算法
- 随机初始化 K 个聚类中心
- 重复下述步骤直至算法收敛:
- 对应每个特征, 根据距离关系赋值给某个中心/类别
- 对每个类别, 根据其对应的特征集重新计算聚类中心
-
码本/字典用于对输入图片的特征集进行量化
- 对于输入特征, 量化的过程是将该特征映射到距离其最接近的 codevector,并实现计数
- 码本 = 视觉词典
- Codevector = 视觉单词
TF-IDF
TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的频率。分子是该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和,即前面提到的词袋模型。

逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到:
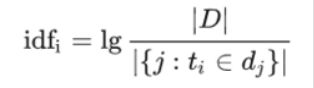
其中
|D|:语料库中的文件总数
j:包含词语的文件数目(即的文件数目)如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用![]()
作为分母。

常用参数
- 视觉单词数量(K-means算法获取的聚类中心) 一般为K=3000~10000. 即图像整体描述的直方图维度为3000~10000.
- 求解近邻的方法一般采用L2-范数: 即 Euclidean 距离.
- 目前普适的视觉单词采用 Lowe 的SIFT特征描述子. 特征点检测采用 DOG (Difference of Gaussians)
图像检索
- 给定输入图像的BOW直方图, 在数据库中查找 k 个最近邻的图像
- 对于图像分类问题, 可以根据这k个近邻图像的分类标签,投票获得分类结果
- 当训练数据足以表述所有图像的时候, 检索/分类效果良好
具体实现流程
必要的准备
PCV的安装在以前的博客中有
pysqlite包pip安装失败,可以下载whl文件安装
最后结果

生成代码所需要的模型文件
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
imlist = get_imlist('image/') ###要记得改成自己的路径
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
voc = vocabulary.Vocabulary('ukbenchtest1')
voc.train(featlist, 20, 1)
with open('image/vocabulary1.pkl', 'wb') as f:
pickle.dump(voc, f)
print 'vocabulary is:', voc.name, voc.nbr_words
将模型数据导入数据库
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
imlist = get_imlist('image/')##记得改成自己的路径
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
with open('image/vocabulary1.pkl', 'rb') as f:
voc = pickle.load(f)
indx = imagesearch.Indexer('testImaAdd1.db',voc)
indx.create_tables()
for i in range(nbr_images)[:1000]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
indx.db_commit()
con = sqlite.connect('testImaAdd1.db',check_same_thread = False)
print con.execute('select count (filename) from imlist').fetchone()
print con.execute('select * from imlist').fetchone()
测试
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
imlist = get_imlist('image/') ##要改成自己的地址
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
with open('image/vocabulary1.pkl', 'rb') as f: ##要改成自己的地址
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd1.db',voc)
q_ind = 0
nbr_results = 2
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print 'top matches (regular):', res_reg
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
model = homography.RansacModel()
rank = {}
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
rank[ndx] = len(inliers)
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print 'top matches (homography):', res_geom
imagesearch.plot_results(src,res_reg[:8]) #常规查询
imagesearch.plot_results(src,res_geom[:8]) #重排后的结果
建立演示程序及Web应用
运行以下代码还需一个serv.conf的配置文件
[global]
server.socket_host = "127.0.0.1"
server.socket_port = 8080
server.thread_pool = 50
tools.sessions.on = True
[/]
tools.staticdir.root = "D:\\stroll\\opencv-py\\7"
tools.staticdir.on = True
tools.staticdir.dir = ""
import cherrypy
import pickle
import urllib
import os
from numpy import *
from PCV.imagesearch import imagesearch
class SearchDemo:
def __init__(self):
self.path = 'image/'
self.imlist = [os.path.join(self.path,f) for f in os.listdir(self.path) if f.endswith('.jpg')]
self.nbr_images = len(self.imlist)
print str(len(self.imlist))+"###############"
self.ndx = range(self.nbr_images)
with open('image/vocabulary1.pkl','rb') as f:
self.voc = pickle.load(f)
self.maxres = 2
self.header = """
<!doctype html>
<head>
<title>Image search</title>
</head>
<body>
"""
self.footer = """
</body>
</html>
"""
def index(self, query=None):
self.src = imagesearch.Searcher('testImaAdd1.db', self.voc)
html = self.header
html += """
<br />
Click an image to search. <a href='?query='> Random selection </a> of images.
<br /><br />
"""
if query:
res = self.src.query(query)[:self.maxres]
for dist, ndx in res:
imname = self.src.get_filename(ndx)
html += ""
html += " "
print imname+"################"
html += ""
else:
random.shuffle(self.ndx)
for i in self.ndx[:self.maxres]:
imname = self.imlist[i]
html += ""
html += ""
print imname+"################"
html += ""
html += self.footer
return html
index.exposed = True
cherrypy.quickstart(SearchDemo(), '/', config=os.path.join(os.path.dirname(__file__),
'service.conf'))
"
print imname+"################"
html += ""
else:
random.shuffle(self.ndx)
for i in self.ndx[:self.maxres]:
imname = self.imlist[i]
html += ""
html += ""
print imname+"################"
html += ""
html += self.footer
return html
index.exposed = True
cherrypy.quickstart(SearchDemo(), '/', config=os.path.join(os.path.dirname(__file__),
'service.conf'))