转自 https://endlesslethe.com/easy-to-learn-ols.html
前言
最小二乘法在统计学的地位不必多言。本文的目的是全面地讲解最小二乘法,打好机器学习的基础,后面的系列文章会继续讲解最小二乘的正则化。
核心思想
最小二乘法是勒让德( A. M. Legendre)于1805年在其著作《计算慧星轨道的新方法》中提出的。它的主要思想就是求解未知参数,使得理论值与观测值之差(即误差,或者说残差)的平方和达到最小:
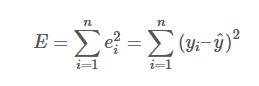
观测值yiy_i就是我们的多组样本,理论值y^\hat y就是我们的假设拟合函数。目标函数也就是在机器学习中常说的损失函数EE,我们的目标是得到使目标函数最小化时候的参数。
所谓最小二乘,其实也可以叫做最小平方和,其目的就是通过最小化误差的平方和,使得拟合对象无限接近目标对象。换句话说,最小二乘法可以用于对函数的拟合。
直观理解
均方误差有非常好的几何意义,它对应了常用的欧几里德距离。在线性回归中,最小二乘法就是试图找到一条直线,使所有样本到直线的欧氏距离之和最小。
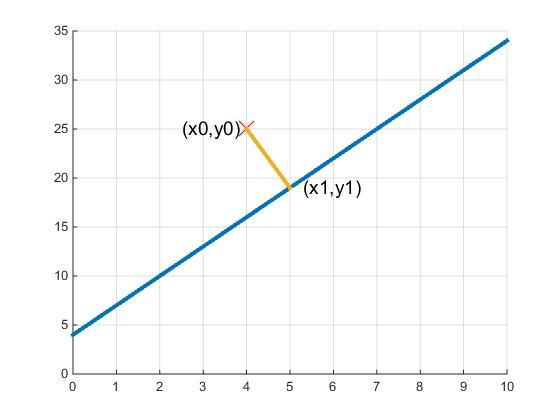
假设有一条直线y=ax+by=ax+b,要在这条直线上找到一点,距离(x0,y0)(x_0,y_0)这个点的距离最短。如果用绝对值的方法寻找,也就是取min(|y−y0|+|x−x0|)\min(|y-y_0|+|x-x_0|),由于绝对值最小为0,所以最小的情况就是x=x0x=x_0或者y=y0y=y_0处,如下图1所示。

如果用平方和的方法寻找,就是取min(y–y0)2+(x–x0)2\min {{(y – {y_0})^2} + {(x – {x_0})^2}},可以看出该式是两点间距离公式,也就是距离的概念。那么最短的距离,就是点到直线的垂线,如下图2所示。
事实上,最小二乘法的解θ=(XTX)–1XTY\theta= {\left( {{X^T}X} \right)^{ – 1}}{X^T}Y正符合投影矩阵的公式:将Y向量投影到X构成的平面上。
Note:最小二乘法用途很广,不仅限于线性回归。
通用解法
列出损失函数EE,样本值用来xix_i表示
对参数求导,解得最小值
此时的参数即为所求
对真值的估计
可以说整部数理统计学的历史,就是对算术平均不断深入研究的历史。而最小二乘法可以解释为什么多次测量取算术平均的结果就是真值,比如估计身高可以测三次后取平均。
当我们对于某个未知量θ\theta观测mm次,记每次的结果为xix_i
E=∑i=1me2i=∑i=1m(xi–nn)2
E = \mathop \sum \limits_{i = 1}^m e_i^2 = \mathop \sum \limits_{i = 1}^m {\left( {{x_i} – nn} \right)^2}
求导得
∑i=1n–(xi–a)=0
\mathop \sum \limits_{i = 1}^n – \left( {{x_i} – a} \right) = 0
所以θ=x¯=∑xim\theta = \bar x = \frac{{\mathop \sum \nolimits^ {x_i}}}{m}
直线拟合/多元线性回归
求导计算最小值是通用解法,但矩阵法比代数法要简洁,且矩阵运算可以取代循环,所以现在很多书和机器学习库都是用的矩阵法来做最小二乘法。
对于函数hθ(x1,x2,…xn)=θ0+θ1x1+…+θnxn{h_{\theta}}({x_1},{x_2},…{x_n}) = {\theta_0} + {\theta_1}{x_1} + … + {\theta_n}{x_n},我们将其的矩阵形式记作:

故损失函数定义为:(系数1/2是为了简化计算添加的,求迹前和求迹后值不变)
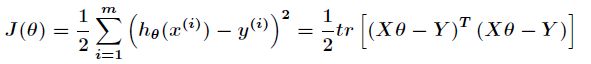
应用矩阵迹的计算公式:
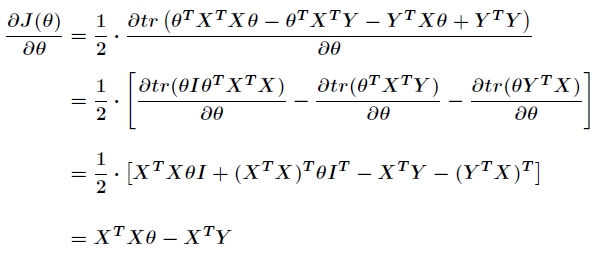
令上式为0,解得θ=(XTX)–1XTY\theta= {\left( {{X^T}X} \right)^{ – 1}}{X^T}Y
Note:矩阵求导坑多,使用迹来计算比较方便。
线性回归的t检验
记n为回归方程的特征个数,m为样本数
S回=∑i=1m(y^–y¯¯¯)
S_回=\sum_{i=1}^m(\hat y – \overline y)
S剩=∑i=1m(yi–y^)
S_剩=\sum_{i=1}^m(y_i – \hat y)
总平方和(SST)可分解为回归平方和(SSR)与残差平方和(SSE)两部
MSR=SSR/k
MSR = SSR / k
MSE=SSE/(n–k–1)
MSE = SSE / (n – k – 1)
F=MSRMSE=S回/kS剩/(n–k–1)
F = \frac{{MSR}}{{MSE}} = \frac{{{S_回}/k}}{{{S_剩}/(n – k – 1)}}
若用样本计算的F>F0.05(k,n–k–1)F > F_{0.05} (k , n – k – 1),则拒绝H0H_0,则回归方程在显著性水平α=0.05\alpha=0.05下是显著的
最小二乘法的适用场景
当样本量mm很少,小于特征数nn的时候,这时拟合方程是欠定的,需要使用LASSO。当m=nm=n时,用方程组求解。当m>nm>n时,拟合方程是超定的,我们可以使用最小二乘法。
局限性
首先,最小二乘法需要计算(XTX)–1{\left( {{X^T}X} \right)^{ – 1}}逆矩阵,有可能逆矩阵不存在,这样就没有办法直接用最小二乘法。
第二,当样本特征n非常的大的时候,计算逆矩阵是一个非常耗时的工作,甚至不可行。建议不超过10000个特征。
第三,如果拟合函数不是线性的,这时无法使用最小二乘法,需要通过一些技巧转化为线性才能使用。
最小二乘法和M估计
在统计数据时,难免会遇到异常值,即人为误差。而这种误差对结果的影响远比系统误差大,比如将1记录成10。所以我们使用稳健性来评价一个方法对异常值的敏感程度。
最小二乘法是一种稳健性较差的方法,原因在于其目标函数是误差的平方,是一个增长很快的函数。
所以不难想到,对于E=∑f(xi)E = \mathop \sum \nolimits^ f({x_i}),我们可以取f(x)=|x|f(x)=|x|
来减小函数的增长速度。
统计学家休伯将这一想法用于对一个未知量θ\theta参数估计的情况,即:
xi=θ+eix_i=\theta+e_i,取定函数ρ\rho,找出使函数M(θ)=∑i=1mρ(xi–θ)M\left( {\theta} \right) = \mathop \sum \limits_{i = 1}^m \rho({x_i} – \theta)达到最小的θ^\hat \theta,将其作为θ\theta的估计值。θ^\hat \theta称为θ\theta的M估计。
M估计是一类估计,主要包括ρ(u)=u2\rho(u)=u^2的最小二乘法和ρ(u)=|x|\rho(u)=|x|的最小一乘法。M估计也可以和最小二乘法一样,推广到多元线性回归,称为稳健回归,但是因为难于计算等局限,应用并不广泛。
Note:最小一乘法对未知参数θ的估计值θ^=xi的中位数\hat \theta =x_i的中位数
最小二乘法和正则化
当(XTX)–1{\left( {{X^T}X} \right)^{ – 1}}不存在,即XTXX_TX不满秩时,θ\theta无唯一解。
故考虑在原先的A的最小二乘估计中加一个小扰动λI\lambda I,使原先无法求广义逆的情况变成可以求出其广义逆,使得问题稳定并得以求解。有:
θ^=(XTX+λI)–1XTY\hat \theta= {\left( {{X^T}X} + \lambda I \right)^{ – 1}}{X^T}Y
而此时对应的损失函数为
J(θ)=∑i=1m(yi–θTxi)2+λ||θ||22
J(\theta ) = \mathop \sum \limits_{i = 1}^m {({y_i} – {\theta ^T}{x_i})^2} + \lambda || \theta || _2^2
上式称为岭回归(ridge regression),通过引入L2范数正则化。
当然也可以将L2范数替换为L1范数。对应有
J(θ)=∑i=1m(yi–θTxi)2+λ||θ||1
J(\theta ) = \mathop \sum \limits_{i = 1}^m {({y_i} – {\theta ^T}{x_i})^2} + \lambda || \theta || _1
上式称为LASSO。
对于L2范数,本质上其实是对误差的高斯先验。
而L1范数则对应于误差的Laplace先验。
最小二乘法的理论证明
拉普拉斯指出随机误差应满足正态分布,而高斯创造性地发明并使用极大似然法证明了最小二乘法。
故测量误差服从高斯分布的情况下, 最小二乘法等价于极大似然估计。
对于任何拟合方程都有:y=y^+ey = \hat y + e
因为e∼N(0,σ2)e \sim N(0,{\sigma^2}),故y∼N(y^,σ2)y \sim N(\hat y,{\sigma^2})
由极大似然估计,L(θ)=∏if(yi)L(\theta ) = \mathop \prod \limits_i f({y_i})
L=1(2π−−√σ)nexp{–12σ2∑i=1n(yi–y^)2}=1(2π−−√σ)nexp–12σ2∑i=1ne2i
L = \frac{1}{{{{\left( {\sqrt {2\pi } \sigma } \right)}^n}}}exp\left\{ { – \frac{1}{{2{\sigma ^2}}}\sum\limits_{i = 1}^n {{{\left( {{y_i} – \hat y} \right)}^2}} } \right\} = \frac{1}{{{{\left( {\sqrt {2\pi } \sigma } \right)}^n}}}exp{ – \frac{1}{{2{\sigma ^2}}}\sum\limits_{i = 1}^n {e_i^2} }
Note:数学的发展史很多时候是不符合逻辑顺序的。事实上,高斯当时是循环论证最小二乘法的,推理有缺陷。而后拉普拉斯才弥补了这一点。其中故事可以见《数理统计学简史》。
参考文献
I. 《数理统计学简史》 陈希孺著
II. 《机器学习》 周志华著
III.正态分布的前世今生(二)
IV. 最小二乘法的本质是什么?
V.最小二乘法小结
VI.到底什么是最小二乘法?
VII.最小二乘法和线性回归及很好的总结
VIII.最小二乘法与岭回归的介绍与对比
IX.最小二乘法
X.最优化理论·非线性最小二乘
XI.Linear least squares, Lasso,ridge regression有何本质区别?
XII.为什么最小二乘法对误差的估计要用平方?
AlgorithmMachine LearningmathMathjax教程