我的NLP实践之旅
我的NLP实践之旅
- 零基础入门NLP - 新闻文本分类
- 比赛介绍
- 赛事数据
- 评价标准
- 结果提交
- 赛题理解
- one-hot介绍
- embeding介绍
- LSTM介绍
- 结语
首先,介绍一下个人情况吧。本人本科2本,大四的时候努力了一下,考了个211学校的硕士,自动化专业,自从毕业以后已经度过了2年的时光,在这段时间里自己陆陆续续的学习了机器学习和深度学习的知识,不过总是感觉实践不够,毕竟自己一个人感觉一直孤军奋战,这次参加了DataWhale的组队学习,希望通过这种方式克服自己拖沓的毛病。好啦,不说了,开始说比赛吧!
零基础入门NLP - 新闻文本分类
本次新人赛是Datawhale与天池联合发起的0基础入门系列赛事第三场,赛题以自然语言处理为背景,要求选手根据新闻文本字符对新闻的类别进行分类,这是一个经典文本分类问题。通过这道赛题可以引导大家走入自然语言处理的世界,带大家接触NLP的预处理、模型构建和模型训练等知识点。
比赛介绍
赛事数据
赛题以新闻数据为赛题数据,数据集报名后可见并可下载。赛题数据为新闻文本,并按照字符级别进行匿名处理。整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐的文本数据。
赛题数据由以下几个部分构成:训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本。为了预防选手人工标注测试集的情况,我们将比赛数据的文本按照字符级别进行了匿名处理。处理后的赛题训练数据如下:
| label | text |
|---|---|
| 6 | 57 44 66 56 2 3 3 37 5 41 9 57 44 47 45 33 13 63 58 31 17 47 0 1 1 69 26 60 62 15 21 12 49 18 38 20 50 23 57 44 45 33 25 28 47 22 52 35 30 14 24 69 54 7 48 19 11 51 16 43 26 34 53 27 64 8 4 42 36 46 65 69 29 39 15 37 57 44 45 33 69 54 7 25 40 35 30 66 56 47 55 69 61 10 60 42 36 46 65 37 5 41 32 67 6 59 47 0 1 1 68 |
在数据集中标签的对应的关系如下:
{‘科技’: 0, ‘股票’: 1, ‘体育’: 2, ‘娱乐’: 3, ‘时政’: 4, ‘社会’: 5, ‘教育’: 6, ‘财经’: 7, ‘家居’: 8, ‘游戏’: 9, ‘房产’: 10, ‘时尚’: 11, ‘彩票’: 12, ‘星座’: 13}
评价标准
评价标准为类别f1_score的均值,选手提交结果与实际测试集的类别进行对比,结果越大越好。
结果提交
提交前请确保预测结果的格式与sample_submit.csv中的格式一致,以及提交文件后缀名为csv
赛题理解
这是一个典型的NLP文本分类问题,通过一篇文章及其内容预测文章标题的分类,由于文章长度不同,首先第一步要做的就是对文章的内容序列进行embeding处理,embeding的通常处理方式为先调用keras中的one_hot函数进行单词的处理,下面介绍一下one_hot
one-hot介绍
顾名思义,所谓的one-hot就是一种独热向量编码方式,例如下面代码:
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
X = [['Male', 1], ['Female', 3], ['Female', 2]]
enc.fit(X)
enc.categories_
enc.transform([['Female', 1], ['Male', 4]]).toarray()
#输出:[array(['Female', 'Male'], dtype=object), array([1, 2, 3],dtype=object)]
enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]])
#输出array([[1., 0., 1., 0., 0.],[0., 1., 0., 0., 0.]])
enc.get_feature_names(['gender', 'group'])
#输出:array([[1., 0., 1., 0., 0.],[0., 1., 0., 0., 0.]])
上述代码是sklearn的OneHotEncoder的官方示例代码,其中OneHotEncoder为sklearn提供的独热向量编码函数,数据对与第一列有两种取值,对与第二列有三种取值,所以对应匹配出的one-hot维度有5个向量,分别对应了所有的取值情况,而对于[‘Male’, 4]的第二列这种未在训练集中出现过的数据,则直接忽略了第二个维度。更多内容请参考:官方介绍.
embeding介绍
实际上embeding就是词向量经由神经网络的处理后生成新的向量的过程。在文章向量生成以后,往往生成的维度较大,且矩阵较为稀疏,需要利用embeding的方式进行降维处理,降维的同时可以保存更多的特征信息。
常用的embeding方式有SkipGram和CBOW

SkipGram的形式如上图所示,其具体作用为用一个词向量预测此词向量的上下文词的内容,词向量的维度为V
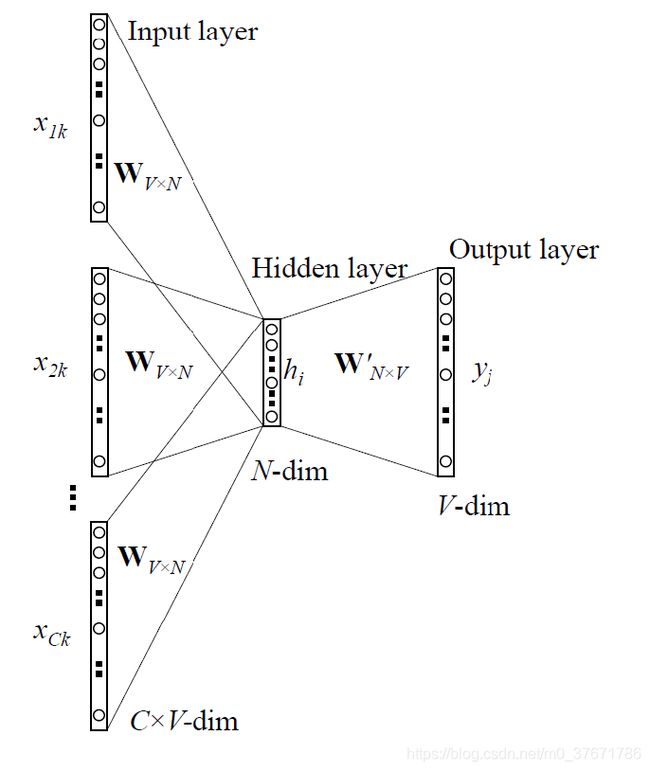
同理,CBOW与SkipGram正好相反,为根据上下文的词向量预测下一个将出现的词,词向量的维度为V,输入词的个数为N
LSTM介绍
上一节中简述了CBOW与SkipGram模型的作用,可以看出这两个模型预测的对象为文本接下来的上下文队列,然而这两种方式预测的时候没有考虑到当前文本的上下文内容,所以在这里简要介绍下LSTM
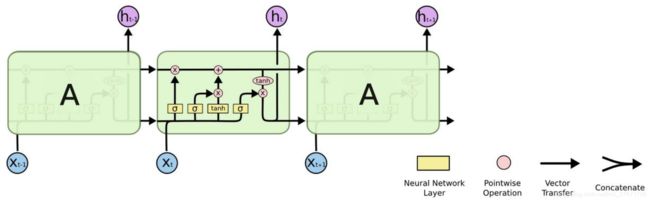
为解决文本预测中的长短时记忆问题,LSTM应运而生,LSTM由三部分所组成,分别为:输入门、输出门、遗忘门
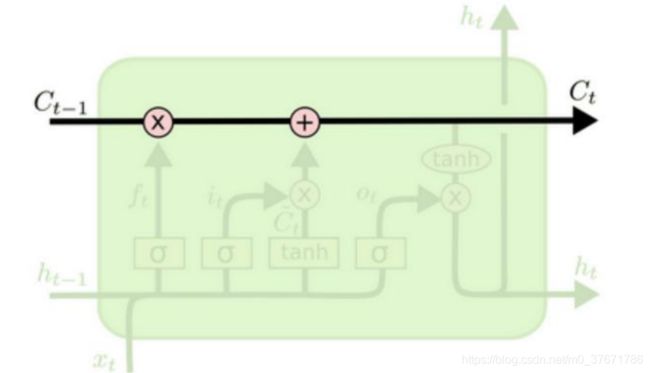
最上面的状态为Ct,其主要作用为接收输入门和遗忘门的数据,以及为输出门提供输出,与神经元内部交互较少。

遗忘门:主要作用为接收上一时刻的状态输出,经过sigmod函数激活后将状态传入Ct。
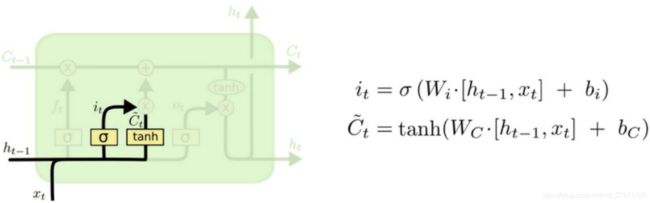
输入门:主要作用为将前一转态处理后分别将其经sigmod函数与tanh函数激活后的结果相乘,并将状态传入Ct中。
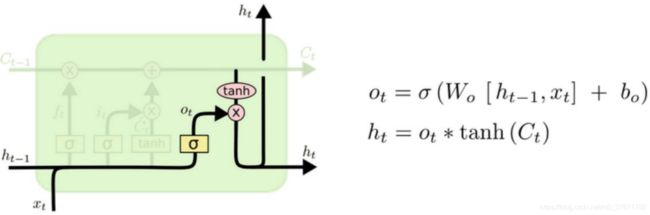
遗忘门:其主要作用为将当前状态信息与上一转态信息相乘,获得当前状态输出。
实现代码:
import pandas as pd
import numpy as np
from tensorflow.keras.preprocessing.text import one_hot
from tensorflow.keras.preprocessing.sequence import pad_sequences
corpus=list(messages['creative_id_seq'])
one_hot_repr=[one_hot(words, 10000) for words in corpus]
sent_length=512
embedded_docs=pad_sequences(one_hot_repr, padding='pre', maxlen=sent_length)
embedded_docs[:2]
这一部分主要是将已得到的文本数据进行one-hot编码并进行embeding,其中主要用到了keras的one_hot函数与pad_sequences函数,其中one-hot函数中的10000代表单词编码最大到10000,而pad_sequences函数作用则为将one-hot后的序列处理成指定的长度。
## 定义LSTM模型
inputs = Input(name='inputs',shape=[512])
## Embedding(词汇表大小,batch大小,每个新闻的词长)
layer = Embedding(10000+1,128,input_length=512)(inputs)
layer = Bidirectional(LSTM(128))(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(2,activation="softmax",name="FC2")(layer)
model1 = Model(inputs=inputs,outputs=layer)
model1.summary()
model1.compile(loss="binary_crossentropy",optimizer=RMSprop(),metrics=["mae"])
这里为LSTM模型的定义,具体为一个embeding层,一个LSTM层以及两个Dense层,不知道这样的定义是否合理,有缺点请在评论区多多指教。
#模型预测
model.fit(X_train, y_train,epochs=1, batch_size=128)
结语
这是我第一次写CSDN的博客,其中应该有许多不足之处,希望大家多多指教。