中文分词:最大匹配法简示
对于变得强大,首先你能尽量做的,就是接受弱小的事实。
各国语言的表达方式不同,书写方式也不同。自然语言处理中,最先做的,也是最基础的就是分词。我们知道,英文分词不存在什么困难。Why?因为它自动分词了啊。
What is up, man?
让机器分词很简单,空格隔开的两边就是分词结果。what是个词,is是个词......
中文就麻烦了,比如:中华民族是一个伟大的国家。
机器怎么分?最次的分法:
中/华/民/族/是/一/个/伟/大/的/国/家。
和没分一样。再来,“中华”算一个词,“华民”算一个词。怎样让机器知道在这个句子里是:
中华/民族 而不是:
中/华民/族 ?
总之我们语言特点的原因,分词有着这样那样的困难。这次我们来一起玩一个最简单分词方式——匹配法。我尝试着来说清它原理。
我们拿这个句子来说:
他是研究生物化学的。
显然正确分词是:他/是/研究/生物/化学/的。
但里面能够被认定为词的还有:“研究生”,“物化”。
怎样做出正确的分词?
最大匹配法,原理是这样的:

我们需要个词典,里面有全部可能的词,比如上图。我们固定住头,用“菱形”标记下。我们从句子末尾开始向前找,“他是研究生物化学的”有没有在词典里。有,就当成分词。不是的话前移,直到:

只剩下一个字“他”,没得移了。那就将他当成一个词,菱形标记后移:
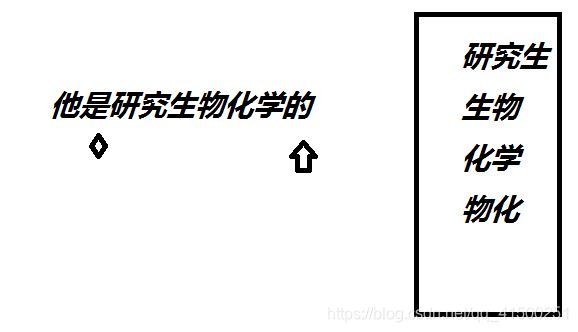
找下一个词,重复上面的步骤。分出“是”:

寻找下一个词:

当我们抠出“研究生”时,判断字典里有,ok,“研究生”是个词。

移动指针找下一个词,找出“物化”。之后是“学”,“的”。
这种方法最终的分词结果是:
他/是/研究生/物化/学的。
此方法叫正向最大匹配法(FMM),从前往后找。反过来,从后往前找就是反向最大匹配法了(BMM)。
我们用python,尝试着实现下。

定义词典和例句,一般词典中是没有那么多单字的,这里为了简单,将单字写入。
我们先来看FMM:
start = 0
while start != len(sentence):
index = len(sentence)
for i in range(len(sentence)):
if sentence[start : index] in dic:
print(sentence[start : index], end='/')
start = index
break
index += -1start(菱形)为起始指针,index(箭头)定位从后往前移动的指针。(用指针不太准确,在Python里面就说下标吧)
while循环每次找出一个分词。
循环的结束条件就是start移到了句子的最后一位上,结束了。
内部的for循环是index移动过程,当sen[start:index]在词典里面时,就跳出循环。更新start值,寻找下一个词。
来看BMM:
result = []
start = len(sentence)
while start != 0:
index = 0
for i in range(len(sentence)):
if sentence[index: start] in dic:
result.append(sentence[index:start])
start = index
break
index += 1
for i in result[::-1]:
print(i,end='/')差不多是一样的,方向变了下,start(菱形)从句子末尾开始,index(箭头)从句子开头向后移。
这里有个点,我们从后找出来不能直接输出,因为最先找到的是“的”这个词,如果按顺序输出的话,句子就反了。所以我们建个list,先把分词放进去,最后反向输出下,就可以了。

棒棒的,BMM就是我们想要的分词结果。
我们再来聊点别的,FMM,BMM的分词结果,我们让机器选哪个呢?肯定不能让人盯着看,哪个对选哪个,那还要机器分哪门子的词。
我们可以指定规则。
两种方法的分词结果,分词数越少,我们就认为它越有可能。因为最差的分词是啥了?
他/是/研/究/生/物/化/学/的。(全是单字词)
所以我们认为词数越少的方法越好,
看我们上面的例子:
FMM分词结果:
他/是/研究生/物化/学/的/
BMM分词结果:
他/是/研究/生物/化学/的/
分词数一样,全是六。肿么办?这种情况下,我们再判断句子中的单字数,谁的单字数越少,我们就认为分词效果越好。
FMM单字数是4:他,是,学,的。
BMM是3:他,是,的。
我们选择BMM。很好,和我们认为对的结果相同。(注意,这种规则不能保证完全正确,只是绝大部分情况下。)
最后,我们来说说,匹配法的不足之处有哪些。
比如,他需要词典。如果词典里面的记录并不全,新兴词很可能识别不出。(skr~skr~ 这种,“品如”啊之类的)
词典容量小了会影响准确率,大了会影响运行效率,矛盾之处。
还有一些歧义句子,比如那个经典的:
南京市长江大桥
我们的理解有两种:
1、南京市长叫江大桥。
2、南京市的长江大桥。
用匹配法分词,不一定会分出很好的结果。这个例子可以。(笑)
比如这个例子:

就不会太好,而基于概率分词时,效果就会好很多。(结合成/分子/时)
对于算法的优化,其实index没必要从句子末尾开始找。我们可以记录词典中最长的词的长度length。每次从start的后面length个位置往前找就可以了。
结束吧。大家有补充的,写下面~