本任务需求:
爬取豆瓣阅读所有书籍的书名、出版社、评分、简介等相关信息。
豆瓣的网页比较干净整洁,链接很有规律
本文具体逻辑顺序:
先获取书籍类目及网址
获取每个类目所有页面的链接
获取书籍名、出版社、评分等信息
衔接前面4部分的代码。
一、获取豆瓣阅读所有类目及链接
https://book.douban.com/tag/
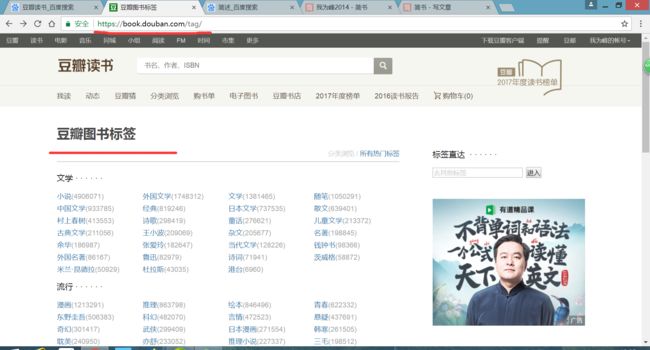
image.png
代码
from pyquery import PyQuery as pq
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
#这里我还是使用requests库作为网络请求库,方便定制
resp = requests.get('https://book.douban.com/tag/', headers=headers)
tags_doc = pq(resp.text)
#获取豆瓣读书标签页的标签列表,此处返回的是PyQuery对象
tags_doc = pq(url='https://book.douban.com/tag/')
#查看https://book.douban.com/tag/的html数据信息
print(tags_doc.html())
#检验发现总共有6个大类(科技、经管、生活、文化、流行文学)
#print(len(tags_doc('.tagCol')))
"""
我们要获取大类下面的小类名(如文学中包含小说、外国文学、杂文等)及小类目的链接
"""
for a in tags_doc('.tagCol').items('a'):
print(a)
"""
与上面打印的a是相同的
for tag in tags_doc('.tagCol'):
for a in pq(tag).items('a'):
print(a)
"""
我们整理下上面的代码,写成一个专门获取小类目及链接的函数
def fetch_tags():
"""
获取豆瓣阅读各个类名的标签名及链接
:return: 形如[(tag_name,link),(tag_name2,link2)...]的列表
"""
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
# 获取豆瓣读书标签页的标签列表,此处返回的是PyQuery对象
resp = requests.get('https://book.douban.com/tag/',headers=headers)
tags_doc = pq(resp.text)
tagnames = []
# 获取class="tagCol"的table标签,提取table中的很多个a标签
for tag in tags_doc('.tagCol').items('a'):
#a标签中的href值
#link = 'https://book.douban.com'+tag.attr('href')
#a标签夹住的文本内容
tag_name = tag.text()
tagnames.append(tag_name)
return tagnames
二、获取某个标签的书籍信息
以“小说”类书籍为例,网址是这样的
#小说第一页网址
"https://book.douban.com/tag/小说?start=0&type=T"
#小说第二页网址
"https://book.douban.com/tag/小说?start=20&type=T"
。。。#小说第n页的网址 (n-1)*20
"https://book.douban.com/tag/小说?start={num}&type=T".format(num=(n-1)*20)

image.png
代码
url = 'https://book.douban.com/tag/{tag}?start={num}&type=T'
resp = requests.get(url.format(tag='小说',num=0))
p_doc = pq(resp.text)
"""
class="paginator"的div节点
选取div中为a的直接子节点
从所有的a节点中选择最后一个a节点。
获取这个a节点的文本内容,即为总的页面数
"""
pages = p_doc('.paginator').children('a').eq(-1).text()
#获取该标签所有的页面网址
purls = []
for page in range(pages):
purl = url.format(tag='小说',num=page*20)
purls.append(purl)
我们将上面的代码整理为一个函数
def tag_page_urls(tag='小说'):
"""
获取某类标签所有的网址
:param tag: 书籍小类目名,如小说
:return: 返回该类目所有页面的网址
"""
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
url = 'https://book.douban.com/tag/{tag}?start={num}&type=T'
resp = requests.get(url.format(tag=tag, num=0),headers=headers)
p_doc = pq(resp.text)
pages = p_doc('.paginator').children('a').eq(-1).text()
# 获取该标签所有的页面网址
purls = []
for page in range(int(pages)):
purl = url.format(tag=tag, num=page * 20)
purls.append(purl)
return purls
三、获取每个页面中书籍的信息
获取书籍具体信息,以小说类第一页例子,想办法获取该页所有的书籍信息。以此类推,换个网址,其他的页面的书籍信息也可以获取。
purl = 'https://book.douban.com/tag/小说?start=0&type=T'
resp = requests.get(purl,headers=headers)
p_doc = pq(resp.text)
for book in p_doc.items('.info'):
#print(type(book)) #
#找class=”info“的div
#div的直接子节点
#从子节点中找a标签
#获取a标签的title属性值
title = book.children('h2').find('a').attr('title')
#出版社 获取class=”info“的div的class=”pub“的子节点的文本内容
public = book.children('.pub').text()
#评论数
comments = book.find('.pl').text()
#书籍简介 获取class=”info“的div倒数第二个子节点的文本
description = book.children().eq(-2).text()
print(title,public,comments,description)
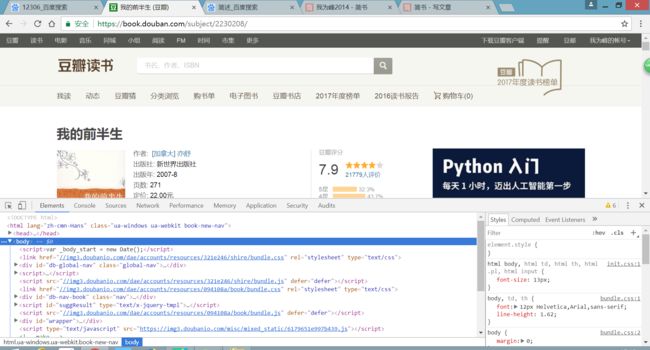
image.png
整理上面的代码,封装为函数
def books_detail(purl,writer):
"""
获取某页面所有的书籍信息
:param purl: 豆瓣阅读某类标签的某一页面的网址
:param writer: 这是从get_all_books_data函数中生成的writer,用来存储数据
:return: 返回该页面所有书籍的信息
"""
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
resp = requests.get(purl,headers=headers)
p_doc = pq(resp.text)
for book in p_doc.items('.info'):
#print(type(book)) #
title = book.children('h2').find('a').attr('title')
#出版社
public = book.children('.pub').text()
# 评分
rating = book.find('.rating_nums').text()
#评论数
comments = book.find('.pl').text()
#书籍简介
description = book.children().eq(-2).text()
detail = (title,public,rating,comments,description)
writer.writerow(detail)
print(detail)
四、豆瓣阅读爬虫
获取豆瓣所有书籍信息
def get_all_books_data(filename):
"""
开始愉快的爬数据
:param filename: 保存数据的csv文件的文件名
:return:
"""
import csv,time
file = '{}.csv'.format(filename)
with open(file,'a+',encoding='utf-8',newline='') as csvf:
writer = csv.writer(csvf)
writer.writerow(('书籍名','出版社','评论数','简述'))
for tag in fetch_tags():
for purl in tag_page_urls(tag=tag):
print(purl)
books_detail(purl=purl,writer=writer)
time.sleep(1)
get_all_books_data(filename='data')
全部代码
def fetch_tags():
"""
获取豆瓣阅读各个类名的标签名及链接
:return: 形如[(tag_name,link),(tag_name2,link2)...]的列表
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
# 获取豆瓣读书标签页的标签列表,此处返回的是PyQuery对象
resp = requests.get('https://book.douban.com/tag/', headers=headers)
tags_doc = pq(resp.text)
tagnames = []
# 获取class="tagCol"的table标签,提取table中的很多个a标签
for tag in tags_doc('.tagCol').items('a'):
# a标签中的href值
# link = 'https://book.douban.com'+tag.attr('href')
# a标签夹住的文本内容
tag_name = tag.text()
tagnames.append(tag_name)
return tagnames
def tag_page_urls(tag='小说'):
"""
获取某类标签所有的网址
:param tag: 书籍小类目名,如小说
:return: 返回该类目所有页面的网址
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
url = 'https://book.douban.com/tag/{tag}?start={num}&type=T'
resp = requests.get(url.format(tag=tag, num=0), headers=headers)
p_doc = pq(resp.text)
pages = p_doc('.paginator').children('a').eq(-1).text()
# 获取该标签所有的页面网址
purls = []
for page in range(int(pages)):
purl = url.format(tag=tag, num=page * 20)
purls.append(purl)
return purls
def books_detail(purl, writer):
"""
获取某页面所有的书籍信息
:param purl: 豆瓣阅读某类标签的某一页面的网址
:param writer: 这是从get_all_books_data函数中生成的writer,用来存储数据
:return: 返回该页面所有书籍的信息
"""
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'}
resp = requests.get(purl, headers=headers)
p_doc = pq(resp.text)
for book in p_doc.items('.info'):
# print(type(book)) #
title = book.children('h2').find('a').attr('title')
# 出版社
public = book.children('.pub').text()
# 评分
rating = book.find('.rating_nums').text()
# 评论数
comments = book.find('.pl').text()
# 书籍简介
description = book.children().eq(-2).text()
detail = (title, public, rating, comments, description)
writer.writerow(detail)
print(detail)
def get_all_books_data(filename):
"""
开始愉快的爬数据
:param filename: 保存数据的csv文件的文件名
:return:
"""
import csv, time
file = '{}.csv'.format(filename)
with open(file, 'a+', encoding='utf-8', newline='') as csvf:
writer = csv.writer(csvf)
writer.writerow(('书籍名', '出版社', '评论数', '简述'))
for tag in fetch_tags():
for purl in tag_page_urls(tag=tag):
print(purl)
books_detail(purl=purl, writer=writer)
time.sleep(1)
get_all_books_data(filename='data')