模型压缩经典论文SqueezeNet:AlexNet level accuracy with 50x fewer parameters and less 0.5MB model size论文详解
ICLR2017 的SqueezeNet为模型压缩领域最经典的文章之一。
论文链接:http://arxiv.org/abs/1602.07360
代码链接:https://github.com/DeepScale/SqueezeNet
目录
一、简介
1.1 作者
1.2 SmallerCNN的优点
层间传递少
占用带宽小
更易部署于硬件
1.3 贡献点
二、方法
2.1 网络结构设计技巧
用1x1卷积核替代3x3
减少输入通道的个数
延后下采样这样卷积层具有更大的激活层(actiavation maps)
2.2 Fire Module(重点)
2.3 squeezeNet架构
2.4 其他细节
2.5 实现平台
三、评估
3.1 网络结构图
3.2 性能对比
四、CNN微结构
4.1 Fire module的超参数
4.2 Squeeze Ratio
4.3 1x1与3x3滤波器的比例
五、CNN宏结构
六、个人总结
一、简介
1.1 作者
Forrest N.Iandola为deepscale的创始人之一,UC berkeley。
韩松为深鉴科技创始人加首席科学家。模型压缩和硬件实现领域的大牛,
1.2 SmallerCNN的优点
层间传递少
分布式训练的时候,小的CNN具有更少的层间通信,对于分布式的并行训练具有很好的优化性能。
占用带宽小
例如从云端向自动化车辆传递时,小的CNN占用更少的带宽
更易部署于硬件
FPGA等其他硬件平台其内存很少,所以小的CNN具有更少的
1.3 贡献点
精度达到AlexNet的级别并且比alexNet少了50x参数
用模型压缩的技巧可以将SqueezeNet压缩到0.5MB的参数量(比AlexNet小510x)
二、方法
从CNN结构层面设计出更少参数的CNN
引入Fire module,用此模块可以更好的构建CNN结构
运用相关的设计技巧设计了SqueezeNet
2.1 网络结构设计技巧
用1x1卷积核替代3x3
比3x3有9倍的运行速度
减少输入通道的个数
一层之中,总的参数量为 (输入通道个数)×(输出通道个数)×(3×3滤波器的大小)。所以作者通过减少输入通道的个数来减少3x3卷积和的个数,从而减少参数量。这个具体通过squeeze layers来实现。
延后下采样这样卷积层具有更大的激活层(actiavation maps)
每层卷积层的输出激活层的长宽通常有下面这些控制:
输入图像的大小(例如 256×256)
CNN中下采样的架构的选择
通常情况下下采样都是采用步长>1的卷积或者池化来实现。如果早期的层具有很大的步长,则后面的层就更容易有小的activation maps。我们的理念是获得大的activation map具有更好的分类精度。
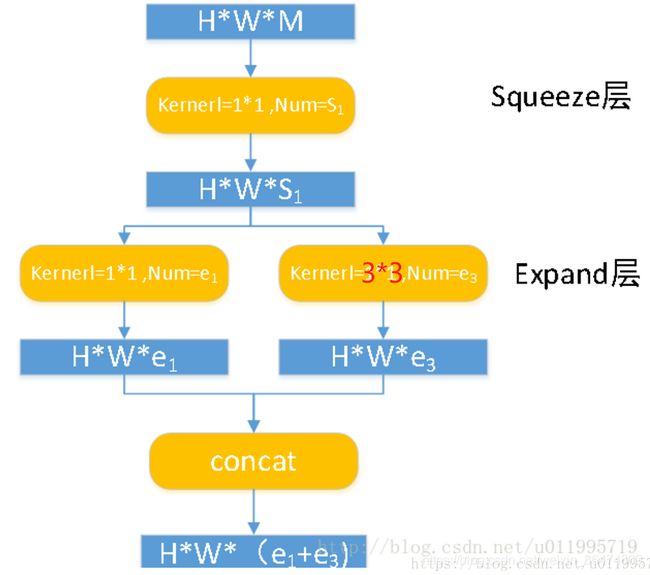
2.2 Fire Module(重点)
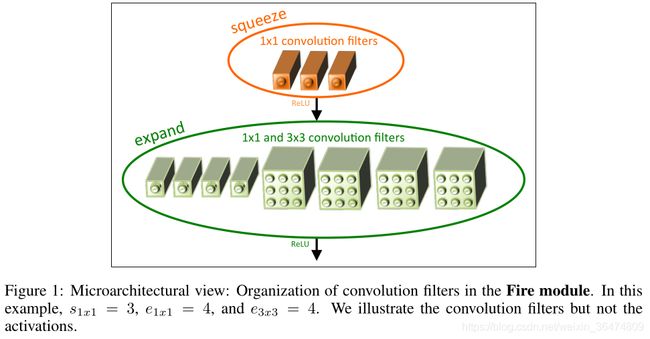
引入squeeze层,用1x1的卷积进行层的挤压,然后用1x1和3x3来对层进行扩张,expand。通过这样减少权重的个数,先squeeze,然后expand,从而获得更少的权重参数:
queeze convolution layer:只使用1∗1卷积 filter
expand layer:使用1∗1和3∗3卷积 filter的组合
Fire module中使用3ge可调的超参数:s1x1(squeeze convolution layer中1∗1 filter的个数)、e1x1(expand layer中1∗1 filter的个数)、e3x3(expand layer中3∗3filter的个数)
使用Fire module的过程中,令s1x1< e1x1 + e3x3,这样squeeze layer可以限制输入通道数量,
具体结构如下:
2.3 squeezeNet架构
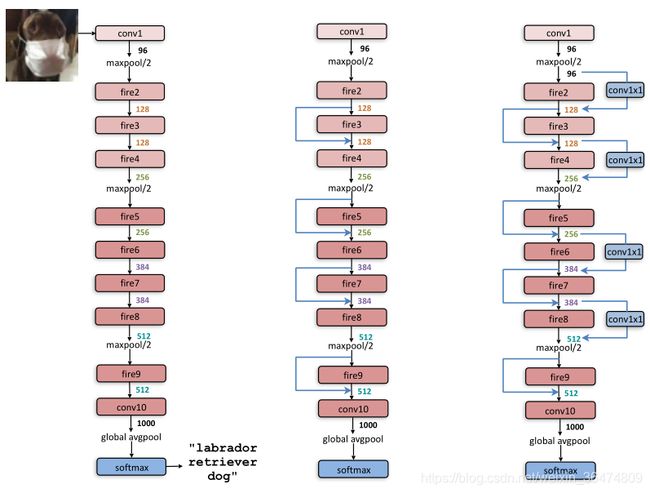
卷积层1之后跟了8个fire模块,以卷积层10结尾。conv1,fire2-9, conv10
在conv1、fire4、fire8 和 conv10 之后执行最大池化,步长为2.
执行fire module是为了减少通道个数
执行较迟的池化是为了增大actiavtion map的大小
2.4 其他细节
为了让1×1卷积和3×3卷积获得一样的宽和高,我们加入了1行或者一列像素的补零,zero-padding
ReLU被应用到squeeze与expand层之中。
在fire9 model之中运用了50%的Dropout
SqueezeNet没有全连接层(fc)
训练时初始化的学习率为0.04,然后逐渐的降低学习率
Caffe架构不支持卷积层之后包含很多filter,所以我们将expand layer实现为两个分开的卷积层。一个是1×1的卷积,一个是3×3的卷积。然后我们将两个结果进行concatenate。这样与同一个层包含1×1与3×3等同
2.5 实现平台
研究将其实现于多个平台上
MXNet (Chen et al., 2015a) port of SqueezeNet: (Haria, 2016)
Chainer (Tokui et al., 2015) port of SqueezeNet: (Bell, 2016)
Keras (Chollet, 2016) port of SqueezeNet: (DT42, 2016)
Torch (Collobert et al., 2011) port of SqueezeNet’s Fire Modules: (Waghmare, 2016)
三、评估
3.1 网络结构图
运用AlexNet的结构,在ImageNet数据集上进行训练。
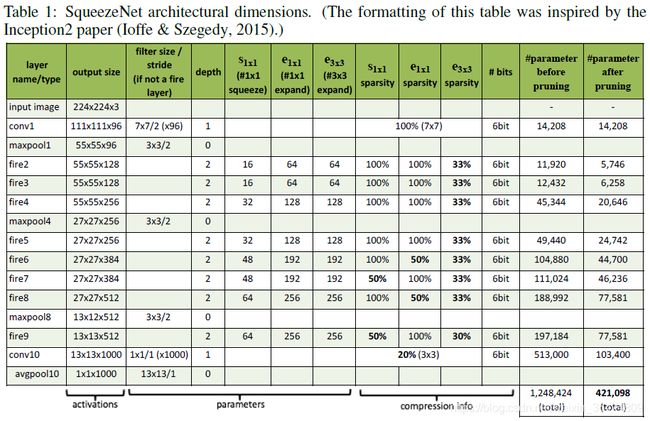
网络结构即上图所示的网络结构,其中用到了方法中提的策略。网络结构如上表。
3.2 性能对比
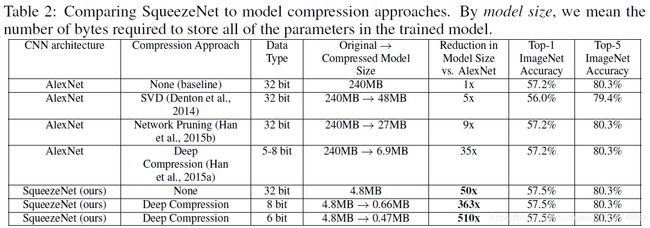
这张表给出了,squeezeNet的SqueezeNet在压缩了很多倍的情况下依然满足了AlexNet同等数量级的准确率。
四、CNN微结构
4.1 Fire module的超参数
在SqueezeNet之中,我们定义了三个超参数,![]()
- basee :Fire module中expand filter的个数
- 每freq个Fire module,我们通过incre增大相应的expand filter的个数
- 对于每一个模型i,expand filters的个数为:
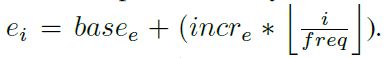
- 总滤波器的个数ei,1x1滤波器的个数e1x1, 3x3滤波器的个数e3x3分别为:
![]()
![]()
![]()
其中,pct3x3即 3x3滤波器所占的expand层的滤波器的比例。
- 压缩率SR(Squeeze Ratio)Squeeze层与expand层之间的滤波器个数的比值:
![]()
![]()
- squeezeNet采用的参数:
![]()
4.2 Squeeze Ratio
SR(Squeeze Ratio压缩比)定义为Squeeze层与expand层之间的滤波器个数的比值。

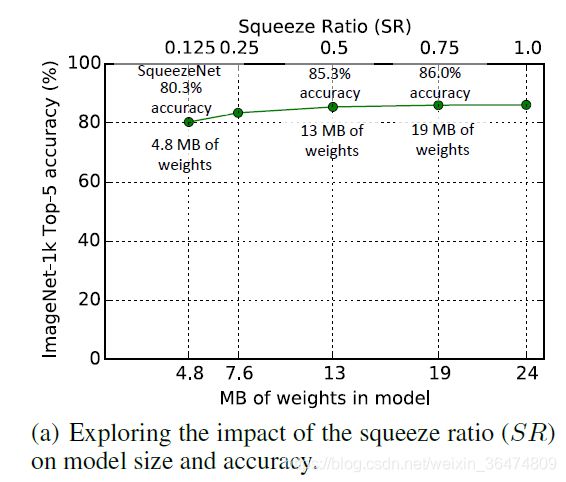
从此图看出,随着压缩率越来越压缩,则网络精度逐渐损失。小于0.25时准确率显著下降。
4.3 1x1与3x3滤波器的比例

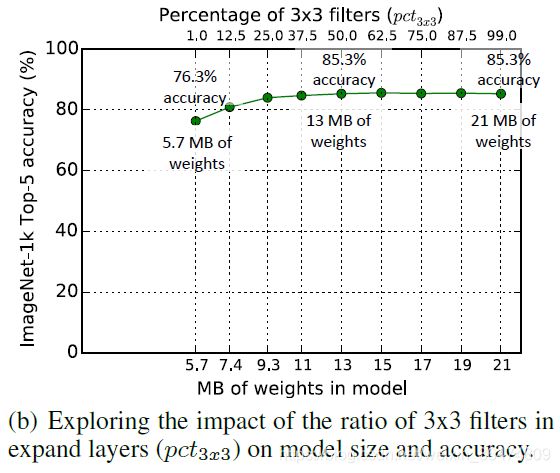
在3x3滤波器比例小于25%时,正确率开始显著下降,此时模型大小约为原先的44%。超过50%后,模型大小显著增加,但是正确率不再上升。
五、CNN宏结构
加入了旁路:

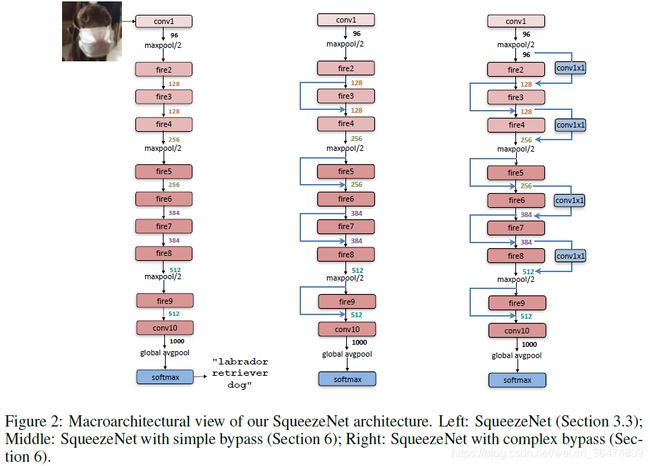

实验显示加入旁路能提升一定的准确率。
六、个人总结
此文唯一创新点是通过Fire module,先挤压,再扩张,从而降低模型参数量。