论文学习笔记 - YOLOv4
『写在前面』
YOLO x 新奇tricks大礼包,带领YOLO重回巅峰。
文章标题:《YOLOv4: Optimal Speed and Accuracy of Object Detection》
作者机构:Alexey Bochkovskiy等.
原文链接:https://arxiv.org/abs/2004.10934v1
相关repo:https://github.com/AlexeyAB/darknet
目录
摘要
1 目标检测模型结构拆解
2 相关工作
2.1 目标检测模型
2.2 BoF(Bag of freebies)
2.3 BoS(Bag of specials)
3 方法论
3.1 模型结构选择
3.2 其他改进
Mosaic
Self-Adversarial Training (SAT)
Selection of hyper-parameters
Cross mini-Batch Normalization (CmBN)
Spatial-wise attention (SAM)
Modified PAN
3.3 YOLOv4
摘要
通过加入很多利于提高检测模型效果的trick(个别trick做了一定调整),YOLOv4在speed和accuracy上较YOLOv3均提升了一大截。并且,与现在表现较好的其他模型相比,如EfficientDet,在AP相当的情况下,速度提升将近一倍。各模型对比情况如下图所示。

1 目标检测模型结构拆解
下图通过一组图片概况了所有目标检测模型的基本组成:

- Input:输入部分,大部分时候是原始图像,还有的模型选择使用图像金字塔作为输入
- Backbone:网络主干部分,负责特征抽取
- Neck:早期并没有,从FPN开始掀起的一股风潮,旨在对不同层次(尺度)的特征进行聚合和加强,现在主流的检测模型基本上都会使用
- Head:检测头部分,根据Dense Prediction / Sparse Prediction可以将检测模型分为two-stage型和one-stage型
2 相关工作
2.1 目标检测模型
当下流行的目标检测模型对应上述各个组成部分常见的选择:
- Input:图像,图像块,图像金字塔
- Backbone:VGGNet, ResNet, SpineNet, EfficientNet, CSPResNeXt50, CSPDarknet53
- Neck:
- 额外的blocks:SPP, ASPP, RFB, SAM
- 路径聚合blocks:FPN, PAN, NAS-FPN, FC FPN, BiFPN, ASFF, SFAM
- Heads:
- Dense Prediction(one-stage):
- anchor based: RPN, SSD, YOLO, RetinaNet
- anchor free: CornerNet, CenterNet, MatrixNet, FCOS
- Sparse Prediction(two-stage):
- anchor based: Faster R-CNN, R-FCN, Mask R-CNN
- anchor free: RepPoints
- Dense Prediction(one-stage):
2.2 BoF(Bag of freebies)
Freebies:指在训练阶段引入的一些trick,仅会增加学习策略或训练开销,对inference无影响
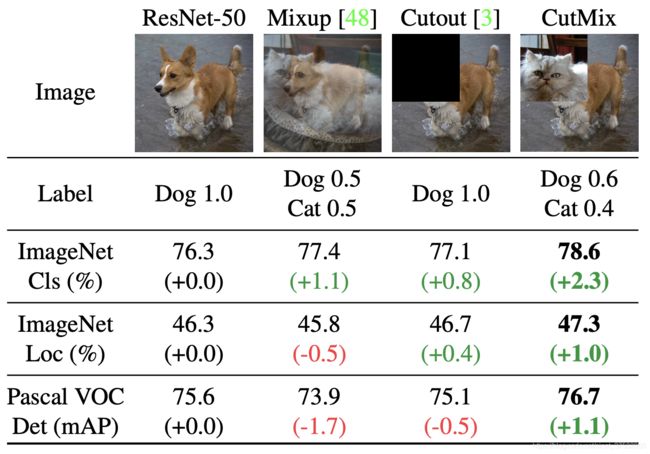
(1)数据增强方面:像随机擦除、CutOut、MixUp、CutMix等都是对训练图像进行处理,如果将这些做法应用在feature map的处理上,就是DropOut、DropConnect、DropBlock。
对比MixUp/ CutOut/ CutMix:
MixUp - 按比例分配包围框的概率
CutOut - 保持框分类结果不变,但随机cut掉部分区域
CutMix - Cut掉部分像素,并使用其他样本进行补充,分类结果按比例分配
(2)平衡正负样本方面:OHEM、Focal loss等
(3)表征不同类别间的内在联系:Label smoothing、知识蒸馏
(4)Box回归:各种基于IoU的loss(GIoU loss/ DIoU loss/ CIoU loss)
IoU类loss的好处是将包围框视为一个整体去考虑。同时因为IoU计算是尺度不变的,所以可以避免L1/L2因尺度而导致的变化范围大的问题。
2.3 BoS(Bag of specials)
Specials:指仅增加少量inference成本的一些trick,它们表现在增强模型的某些属性,如:扩大感受野、引入注意力机制、加强特征间联系,一些后处理方法等。
(1)增加感受野:SPP、ASPP、RFB
(2)注意力机制:SE layer (channel-wise attention,在GPU上latency+10%,常用于CPU);SAM(spatial attention,成本更低,适宜在GPU上运行)
(3)特征融合:SFAM、ASFF、BiFPN
(4)激活函数:LReLU、PReLU、ReLU6、SELU、Swish、hard-Swish、Mish
(5)后处理方法:NMS、soft-NMS、DIoU NMS
3 方法论
3.1 模型结构选择
很多实验结果表明,好的分类模型并非都是适合用于检测的模型。好的检测模型有如下几个特点:
1)较高的输入大小——利于小目标检测;
2)更多的层数——意味着更大的接受范围,以覆盖大的输入尺寸;
3)更多的参数——有利于模型从单个输入图像中检出多个不同尺寸目标的能力。
综上所述,我们倾向于选择一个接受范围大(大量3*3卷积)同时参数量也大的模型作为Backbone。
直接上结论,作者选择了CSPDarknet53作为YOLOv4的Backbone,CSPDarknet53拥有29个3*3卷积层,考虑input size为512*512的情况下,其接受范围大小为725*725,含27.6M个参数。
不同接受场大小的影响:
- 覆盖不同大小的目标——使模型具有观察整个目标物的能力
- 使模型具有查看目标周围上下文信息的能力
- 增加从图像点到最后激活层的连接数量
在CSPDarknet53基础上,为了进一步扩大接受场,作者添加了SPP块。SPP块在没有增加网络运算开销的情况下,有利于抽取出更重要的上下文特征。
另外,为了加强特征融合,作者还用了PANet中的聚合思想。
总而言之,YOLOv4的模型结构就是CSPDarknet53 Backbone + SPP module + PANet path-aggregation neck,然后再加上和YOLOv3相同的head结构(anchor based)。
3.2 其他改进
为了使模型更适于单GPU训练,还做了一些改进和设计:
Mosaic
一种数据增强方法,如下图所示,mix 4张训练图像,使模型可以检测出超出原本训练集中正常上下文的对象。此外,因为增强过后的一张图像包含了多张图像,故BN层在计算统计量时相当于在4张不同的图像上去计算(数值更稳定、鲁棒?),因此可以显著降低对batch size大小的要求。

Self-Adversarial Training (SAT)
自对抗训练,一种数据增强方法,分为两个阶段:1)网络改变输入图像,模拟对自身进行攻击,产生画面中无目标的假象;2)第二个阶段在被修改的训练图像上执行常规检测。
Selection of hyper-parameters
借助遗传算法选择最优超参数
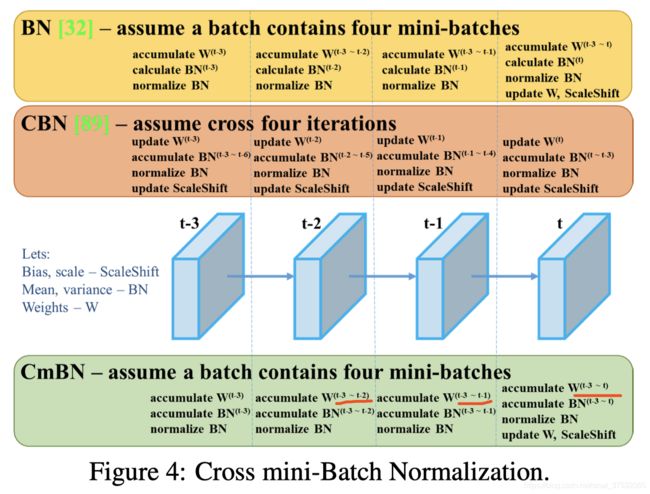
Cross mini-Batch Normalization (CmBN)
CBN的修改版,细节见下图。
Spatial-wise attention (SAM)
在原版SAM的基础上,如下图所示,将spatial-wise attention转为point-wise attention(去掉了2*pooling)。

Modified PAN
将原版PANet中的加法操作替换为拼接操作,目的应该是为了提速。

3.3 YOLOv4
最终定型YOLOv4模型细节汇总如下,其中红色字体标注的文章中并未详细描述:
| Components | Backbone | CSPDarknet53 |
| Neck | SPP | |
| PAN | ||
| Head | YOLOv3 | |
| Tricks | BoF for backbone | CutMix |
| Mosaic | ||
| DropBlock | ||
| Label smoothing | ||
| BoS for backbone | Mish | |
| CSP | ||
| MiWRC | ||
| BoF for detector | CIoU-loss | |
| CmBN | ||
| DropBlock | ||
| Mosaic | ||
| SAT | ||
| Eliminate grid sensitivity | ||
| Multiple anchors | ||
| Cosine annealing scheduler | ||
| Optimal hyperparameters | ||
| Random training shapes | ||
| BoS for detector | Mish | |
| SPP block | ||
| SAM block | ||
| PAN block | ||
| DIOU-NMS |