hadoop的HA安装
下载安装的hadoop安装包地址:https://archive.apache.org/dist/hadoop/common/
1.将下载的安装包解压;tar -zxvf hadoop-2.7.5.tar.gz
2.修改环境变量 vi /etc/profile
export HADOOP_HOME=/data/hadoop/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin修改之后记得要 source /etc/profile
3.修改配置文件 hadoop-evn.sh 添加java的环境变量 (文件路径:/data/hadoop/hadoop-2.7.5/etc/hadoop)
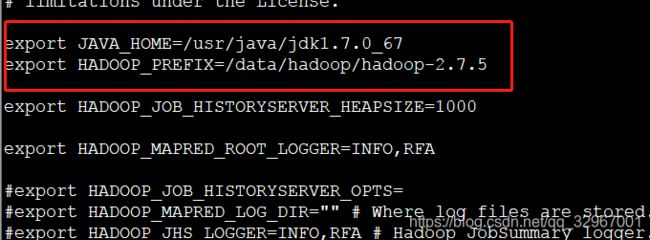
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_PREFIX=/data/hadoop/hadoop-2.7.5

4.修改配置文件 mapred-env.sh 添加java的环境变量
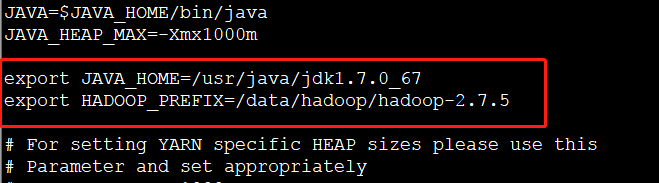
5.修改配置文件 yarn-env.sh 添加java的环境变量
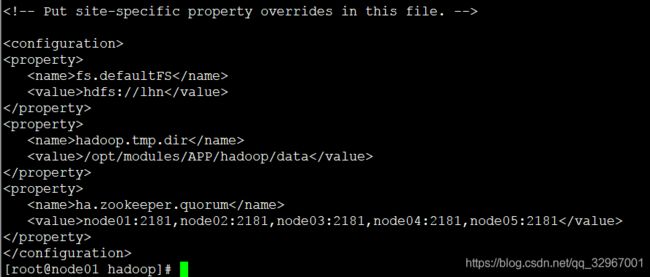
6.修改core-site.xml文件
7.修改hdfs-site.xml文件
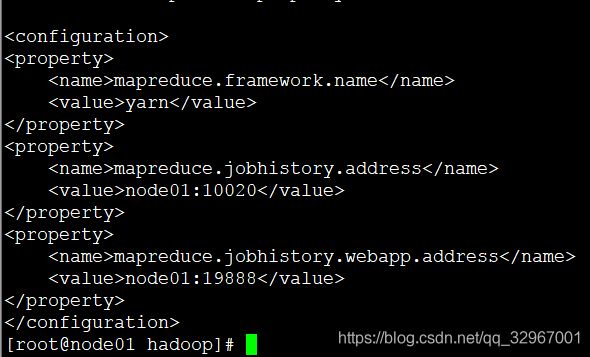
8.修改mapred-site.xml.template名称为mapred-site.xml并修改
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node01:10020
mapreduce.jobhistory.webapp.address
node01:19888
9.配置 yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmcluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
node01
yarn.resourcemanager.hostname.rm2
node02
yarn.resourcemanager.zk-address
node01:2181,node02:2181,node03:2181,node04:2181,node05:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
10.配置slaves
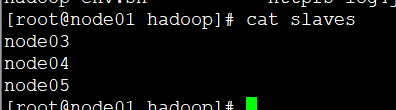
scp hadoop到其他四台机器,node02----node05
11.在node01的yarn-site.xml上添加:
yarn.resourcemanager.ha.id
rm1
12..在node02的yarn-site.xml上添加:
yarn.resourcemanager.ha.id
rm2
13.启动zookeeper之后启动集群