flink源码阅读之JobGraph的生成过程
flink源码阅读之JobGraph的生成过程
本文flink版本为flink1.11
flink job在最初会生成一个StreamGraph,然而StreamGraph只是程序初步得到的一个数据链路,根据算子的并行度等因素还能优化成为JobGraph。JobGraph的存在主要是为了兼容batch process,Streaming process最初产生的是StreamGraph,而batch process产生的则是OptimizedPlan,他们最后都会转化为JobGraph。
生成JobGraph的整体流程
从StreamGraph到JobGraph的转化步骤
-
设置调度模式,Eager 所有节点立即启动。
-
广度优先遍历 StreamGraph,为每个 streamNode 生成 byte 数组类型的 hash 值。
-
从 source 节点开始递归寻找嵌到一起的 operator,不能嵌到一起的节点单独生成 jobVertex,能够嵌到一起的开始节点生成 jobVertex,其他节点以序列化的形式写入到 StreamConfig,然后 merge 到 CHAINED_TASK_CONFIG,再通过 JobEdge 链接上下游 JobVertex。
-
将每个 JobVertex 的入边(StreamEdge)序列化到该 StreamConfig。
-
根据 group name 为每个 JobVertext 指定 SlotSharingGroup。
-
配置 checkpoint。
-
将缓存文件存文件的配置添加到 configuration 中。
-
设置 ExecutionConfig。
如果以local model执行flink任务,源码层面的方法调用流程如下所示
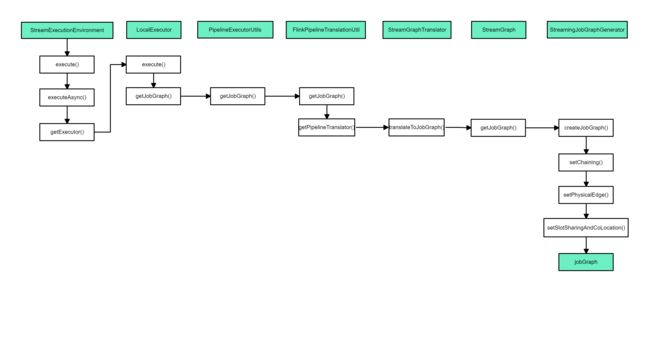
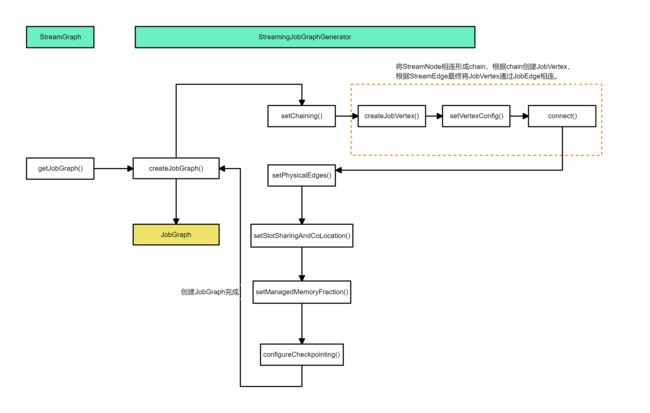
StreamGraph转化为JobGraph的重点步骤主要在StreamingJobGraphGenerator文件中,这一部分的方法调用流程如下
看一下源码
private JobGraph createJobGraph() {
preValidate();
// make sure that all vertices start immediately
jobGraph.setScheduleMode(streamGraph.getScheduleMode());
// Generate deterministic hashes for the nodes in order to identify them across
// submission iff they didn't change.
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
// Generate legacy version hashes for backwards compatibility
List<Map<Integer, byte[]>> legacyHashes = new ArrayList<>(legacyStreamGraphHashers.size());
for (StreamGraphHasher hasher : legacyStreamGraphHashers) {
legacyHashes.add(hasher.traverseStreamGraphAndGenerateHashes(streamGraph));
}
// 方法将可以 Chain 到一起的 StreamNode Chain 在一起,这里会生成相应的 JobVertex 、JobEdge 、 IntermediateDataSet 对象,JobGraph 的 Graph 在这一步就已经完全构建出来了;
setChaining(hashes, legacyHashes);
// 方法会将每个 JobVertex 的入边集合也序列化到该 JobVertex 的 StreamConfig 中 (出边集合已经在 setChaining 的时候写入了);
setPhysicalEdges();
// 方法主要是 JobVertex 的 SlotSharingGroup 和 CoLocationGroup 设置;
setSlotSharingAndCoLocation();
//
setManagedMemoryFraction(
Collections.unmodifiableMap(jobVertices),
Collections.unmodifiableMap(vertexConfigs),
Collections.unmodifiableMap(chainedConfigs),
id -> streamGraph.getStreamNode(id).getMinResources(),
id -> streamGraph.getStreamNode(id).getManagedMemoryWeight());
// 方法主要是 checkpoint 相关的设置。
configureCheckpointing();
jobGraph.setSavepointRestoreSettings(streamGraph.getSavepointRestoreSettings());
JobGraphUtils.addUserArtifactEntries(streamGraph.getUserArtifacts(), jobGraph);
// set the ExecutionConfig last when it has been finalized
try {
jobGraph.setExecutionConfig(streamGraph.getExecutionConfig());
}
catch (IOException e) {
throw new IllegalConfigurationException("Could not serialize the ExecutionConfig." +
"This indicates that non-serializable types (like custom serializers) were registered");
}
return jobGraph;
}
为每个operator生成hash值
在createJobGraph()方法中,traverseStreamGraphAndGenerateHashes()方法为每个operator生成hash
Map<Integer, byte[]> hashes = defaultStreamGraphHasher.traverseStreamGraphAndGenerateHashes(streamGraph);
如果用户对节点指定了一个散列值,则基于用户指定的值能够产生一个长度为 16 的字节数组。如果用户没有指定,则根据当前节点所处的位置,产生一个散列值。
为每个operator生成hash的原因
Flink 任务失败的时候,各个 operator 是能够从 checkpoint 中恢复到失败之前的状态的,恢复的时候是依据 JobVertexID(hash 值)进行状态恢复的。相同的任务在恢复的时候要求 operator 的 hash 值不变,因此能够获取对应的状态。
setChaining() —判断算子能否chain在一起
setChaining()方法用来将StreamNode chain一起,该方法最终会调用createChain()方法,先分析源码,再解析具体步骤
private void setChaining(Map<Integer, byte[]> hashes, List<Map<Integer, byte[]>> legacyHashes) {
for (Integer sourceNodeId : streamGraph.getSourceIDs()) {
createChain( // 处理每个source StreamNode
sourceNodeId,
0,
new OperatorChainInfo(sourceNodeId, hashes, legacyHashes, streamGraph));
}
}
private List<StreamEdge> createChain(Integer currentNodeId, int chainIndex, OperatorChainInfo chainInfo) {
Integer startNodeId = chainInfo.getStartNodeId();
if (!builtVertices.contains(startNodeId)) {
// 当前operator chain的最终的输出边,不包括内部的边
List<StreamEdge> transitiveOutEdges = new ArrayList<StreamEdge>();
// 以Edge为粒度,计算上下游能chain在一起的Edge
List<StreamEdge> chainableOutputs = new ArrayList<StreamEdge>();
List<StreamEdge> nonChainableOutputs = new ArrayList<StreamEdge>();
// 获得当前要处理的StreamNode
StreamNode currentNode = streamGraph.getStreamNode(currentNodeId);
// 遍历当前StreamNode的输出节点,判断哪些输出节点能chain
for (StreamEdge outEdge : currentNode.getOutEdges()) {
if (isChainable(outEdge, streamGraph)) {
chainableOutputs.add(outEdge);
} else {
nonChainableOutputs.add(outEdge);
}
}
// 对于chainable的输出边,递归调用,找到最终的输出边并加入到输出列表中
for (StreamEdge chainable : chainableOutputs) {
transitiveOutEdges.addAll( // 递归调用,能chain在一起的话,chainIndex会+1
createChain(chainable.getTargetId(), chainIndex + 1, chainInfo));
}
for (StreamEdge nonChainable : nonChainableOutputs) {
transitiveOutEdges.add(nonChainable); // 这个边不管能不能连接,都应该添加到输出列表中
createChain(nonChainable.getTargetId(), 0, chainInfo.newChain(nonChainable.getTargetId()));
}
chainedNames.put(currentNodeId, createChainedName(currentNodeId, chainableOutputs)); // 记录chainedName
chainedMinResources.put(currentNodeId, createChainedMinResources(currentNodeId, chainableOutputs)); // 计算Chain之后node的minResources
chainedPreferredResources.put(currentNodeId, createChainedPreferredResources(currentNodeId, chainableOutputs)); // 计算Chain之后node的资源上限
// addNodeToChain 用于保存一个operator chain中所有operator的hash信息
OperatorID currentOperatorId = chainInfo.addNodeToChain(currentNodeId, chainedNames.get(currentNodeId));
if (currentNode.getInputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addInputFormat(currentOperatorId, currentNode.getInputFormat());
}
if (currentNode.getOutputFormat() != null) {
getOrCreateFormatContainer(startNodeId).addOutputFormat(currentOperatorId, currentNode.getOutputFormat());
}
// 如果当前节点为起始节点,直接创建JobVertex,如果不是,则先创建一个Stream Config
StreamConfig config = currentNodeId.equals(startNodeId)
? createJobVertex(startNodeId, chainInfo)
: new StreamConfig(new Configuration());
// 设置 JobVertex 的 StreamConfig, 基本上是将 StreamNode 中的配置设置到 StreamConfig 中
setVertexConfig(currentNodeId, config, chainableOutputs, nonChainableOutputs);
// 走到这里,说明chain已经完成
if (currentNodeId.equals(startNodeId)) {
config.setChainStart();
config.setChainIndex(0);
config.setOperatorName(streamGraph.getStreamNode(currentNodeId).getOperatorName());
config.setOutEdgesInOrder(transitiveOutEdges);
config.setOutEdges(streamGraph.getStreamNode(currentNodeId).getOutEdges());
for (StreamEdge edge : transitiveOutEdges) {
connect(startNodeId, edge);
}
// 将chain中所有子节点的StreamConfig写入的headOfChain节点的CHAINED_TASK_CONFIG 配置中
config.setTransitiveChainedTaskConfigs(chainedConfigs.get(startNodeId));
} else {
chainedConfigs.computeIfAbsent(startNodeId, k -> new HashMap<Integer, StreamConfig>()); // 如果是chain中子节点
config.setChainIndex(chainIndex);
StreamNode node = streamGraph.getStreamNode(currentNodeId);
config.setOperatorName(node.getOperatorName());
chainedConfigs.get(startNodeId).put(currentNodeId, config); // 将当前 StreamNode 的 config 记录到该 chain 的 config 集合中
}
config.setOperatorID(currentOperatorId);
if (chainableOutputs.isEmpty()) {
config.setChainEnd();
}
return transitiveOutEdges;
} else {
return new ArrayList<>();
}
}
在执行createChain方法时,它首先从会遍历这个 StreamGraph 的 source 节点,然后选择从 source 节点开始执行 createChain() 方法,在具体的实现里,主要逻辑如下:
createChain()当前要处理的节点是currentNodeId,先从 StreamGraph 中拿到这个 StreamNode 的 outEdge(currentNode.getOutEdges()),然后判断这个 outEdge 连接的两个 StreamNode 是否可以 Chain 在一起,判断方法是isChainable();- 紧接着会有一个递归调用:
- 对于可以 Chain 在一起的 StreamEdge(这个 Edge 连接两个 StreamNode 是可以 Chain 在一起),会再次调用
createChain()方法,并且createChain()中的startNodeId还是最开始的startNodeId(这个标识了这个 ChainNode 的开始 NodeId),而chainIndex会自增加 1; - 而对于不能 Chain 在一起的 StreamEdge,
createChain()中的startNodeId变成了这个 StreamEdge 的 target StreamNode(相当于如果 Chain 在一起,ChainNode 中的 startNodeId 会赋值为下一个节点的 NodeId,然后再依次类推),chainIndex又从 0 开始计; - 也就是说:
createChain()中的startNodeId表示了当前可以 Chain 之后 Node 的 startId,这里,会一直递归调用,直到达到 Sink 节点。
- 对于可以 Chain 在一起的 StreamEdge(这个 Edge 连接两个 StreamNode 是可以 Chain 在一起),会再次调用
- 然后在生成
StreamConfig对象时,判断当前的currentNodeId与startNodeId是否相等,如果相等的话,证明当前 Node 就是这个 ChainNode 的 StartNode,这里会调用createJobVertex()方法给这个 ChainNode 创建一个 JobVertex 对象,最后会返回一个 StreamConfig 对象,如果前面的 id 不相等的话,这里会直接返回一个 StreamConfig 对象(这个对象主要是记录当前 StreamNode 的一些配置,它会同步 StreamGraph 中相关的配置); - 最后还会分两种情况判断:
- 如果 id 相等,相当于这个 ChainNode 已经完成,先做一些相关的配置(比如:标识当前 StreamNode 为这个 JobVertex 的起始 node),最后再通过
connect()方法创建 JobEdge 和 IntermediateDataSet 对象,把这个 Graph 连接起来; - 如果 id 不相等,那么证明当前 StreamNode 只是这个 Chain的一部分,这里只是同步一下信息,并记录到缓存。
- 如果 id 相等,相当于这个 ChainNode 已经完成,先做一些相关的配置(比如:标识当前 StreamNode 为这个 JobVertex 的起始 node),最后再通过
判断两个StreamNode能否chain
判断两个StreamNode能够chain,需要符合以下几个条件
- 对应下游Vertex的入读只有1。
- 上游Vertex和下游Vertex在一个共享的slot中。
- edge 的分区函数是 ForwardPartitioner 的实例。ForwardPartitioner分区器要求上下游算子并行度一样。上下游Operator同属一个SubTasks。关于flink的8大分区,可以参考
- 任务不是流式任务
- 上下游算子并行度相同
- StreamGraph是否允许连接
public static boolean isChainable(StreamEdge edge, StreamGraph streamGraph) {
StreamNode upStreamVertex = streamGraph.getSourceVertex(edge);
StreamNode downStreamVertex = streamGraph.getTargetVertex(edge);
return downStreamVertex.getInEdges().size() == 1
&& upStreamVertex.isSameSlotSharingGroup(downStreamVertex)
&& areOperatorsChainable(upStreamVertex, downStreamVertex, streamGraph)
&& (edge.getPartitioner() instanceof ForwardPartitioner)
&& edge.getShuffleMode() != ShuffleMode.BATCH
&& upStreamVertex.getParallelism() == downStreamVertex.getParallelism()
&& streamGraph.isChainingEnabled();
}
createJobVertex()创建JobVertex
源码如下,根据chainInfo与StreamNode创建JobVertex
private StreamConfig createJobVertex(
Integer streamNodeId,
OperatorChainInfo chainInfo) {
JobVertex jobVertex;
StreamNode streamNode = streamGraph.getStreamNode(streamNodeId);
byte[] hash = chainInfo.getHash(streamNodeId);
if (hash == null) {
throw new IllegalStateException("Cannot find node hash. " +
"Did you generate them before calling this method?");
}
JobVertexID jobVertexId = new JobVertexID(hash);
List<Tuple2<byte[], byte[]>> chainedOperators = chainInfo.getChainedOperatorHashes(streamNodeId);
List<OperatorIDPair> operatorIDPairs = new ArrayList<>();
if (chainedOperators != null) {
for (Tuple2<byte[], byte[]> chainedOperator : chainedOperators) {
OperatorID userDefinedOperatorID = chainedOperator.f1 == null ? null : new OperatorID(chainedOperator.f1);
operatorIDPairs.add(OperatorIDPair.of(new OperatorID(chainedOperator.f0), userDefinedOperatorID));
}
}
if (chainedInputOutputFormats.containsKey(streamNodeId)) {
jobVertex = new InputOutputFormatVertex(
chainedNames.get(streamNodeId),
jobVertexId,
operatorIDPairs);
chainedInputOutputFormats
.get(streamNodeId)
.write(new TaskConfig(jobVertex.getConfiguration()));
} else {
jobVertex = new JobVertex(
chainedNames.get(streamNodeId),
jobVertexId,
operatorIDPairs);
}
for (OperatorCoordinator.Provider coordinatorProvider : chainInfo.getCoordinatorProviders()) {
try {
jobVertex.addOperatorCoordinator(new SerializedValue<>(coordinatorProvider));
} catch (IOException e) {
throw new FlinkRuntimeException(String.format(
"Coordinator Provider for node %s is not serializable.", chainedNames.get(streamNodeId)));
}
}
jobVertex.setResources(chainedMinResources.get(streamNodeId), chainedPreferredResources.get(streamNodeId));
jobVertex.setInvokableClass(streamNode.getJobVertexClass());
int parallelism = streamNode.getParallelism();
if (parallelism > 0) {
jobVertex.setParallelism(parallelism);
} else {
parallelism = jobVertex.getParallelism();
}
jobVertex.setMaxParallelism(streamNode.getMaxParallelism());
if (LOG.isDebugEnabled()) {
LOG.debug("Parallelism set: {} for {}", parallelism, streamNodeId);
}
// TODO: inherit InputDependencyConstraint from the head operator
jobVertex.setInputDependencyConstraint(streamGraph.getExecutionConfig().getDefaultInputDependencyConstraint());
jobVertices.put(streamNodeId, jobVertex);
builtVertices.add(streamNodeId);
jobGraph.addVertex(jobVertex);
return new StreamConfig(jobVertex.getConfiguration());
}
connect()-将JobVertex与JobEdge连接在一起
-
JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
-
IntermediateDataSet:表示JobVertex的输出,即经过operator处理产生的数据集。producer是JobVertex,consumer是JobEdge。
-
JobEdge:代表了job graph中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
JobVertex与JobEdge的联系如下图所示

再看一下connect的源码
private void connect(Integer headOfChain, StreamEdge edge) {
// 记录StreamEdge
physicalEdgesInOrder.add(edge);
Integer downStreamVertexID = edge.getTargetId();
// 这里 headVertex 指的是 headOfChain 对应的 JobVertex(也是当前 node 对应的 vertex)
JobVertex headVertex = jobVertices.get(headOfChain);
JobVertex downStreamVertex = jobVertices.get(downStreamVertexID);
StreamConfig downStreamConfig = new StreamConfig(downStreamVertex.getConfiguration());
// 这个节点的输入数增加1
downStreamConfig.setNumberOfInputs(downStreamConfig.getNumberOfInputs() + 1);
StreamPartitioner<?> partitioner = edge.getPartitioner();
ResultPartitionType resultPartitionType;
switch (edge.getShuffleMode()) {
case PIPELINED:
resultPartitionType = ResultPartitionType.PIPELINED_BOUNDED;
break;
case BATCH:
resultPartitionType = ResultPartitionType.BLOCKING;
break;
case UNDEFINED:
resultPartitionType = determineResultPartitionType(partitioner);
break;
default:
throw new UnsupportedOperationException("Data exchange mode " +
edge.getShuffleMode() + " is not supported yet.");
}
// 开始创建jobEdge
JobEdge jobEdge;
if (isPointwisePartitioner(partitioner)) {
jobEdge = downStreamVertex.connectNewDataSetAsInput( // 这个方法会创建 IntermediateDataSet 对象
headVertex,
DistributionPattern.POINTWISE, // 上游与下游的消费模式,(每个生产任务的 sub-task 会连接到消费任务的一个或多个 sub-task)
resultPartitionType);
} else {
jobEdge = downStreamVertex.connectNewDataSetAsInput(
headVertex,
DistributionPattern.ALL_TO_ALL, // 每个生产任务的 sub-task 都会连接到每个消费任务的 sub-task
resultPartitionType);
}
// set strategy name so that web interface can show it.
jobEdge.setShipStrategyName(partitioner.toString());
if (LOG.isDebugEnabled()) {
LOG.debug("CONNECTED: {} - {} -> {}", partitioner.getClass().getSimpleName(),
headOfChain, downStreamVertexID);
}
}
执行完connect()方法之后,JobGraph基本已经创建完成。
reference
- 浅谈 Flink - JobGraph
- Flink Streaming 作业如何转化为 JobGraph
- Flink 源码阅读笔记(2)- JobGraph 的生成
- Flink作业调度
- Apache Flink 进阶(六):Flink 作业执行深度解析