抽空读完了《k8s权威指南》一书,对k8s的总算有了较为系统的认知。
好记忆不如多写字,以下是读书笔记
第一章 k8s入门
k8s是什么: 一个开源的容器集群管理平台,可提供容器集群的自动部署,扩缩容,维护等功能。分为管理节点Master和工作节点Node
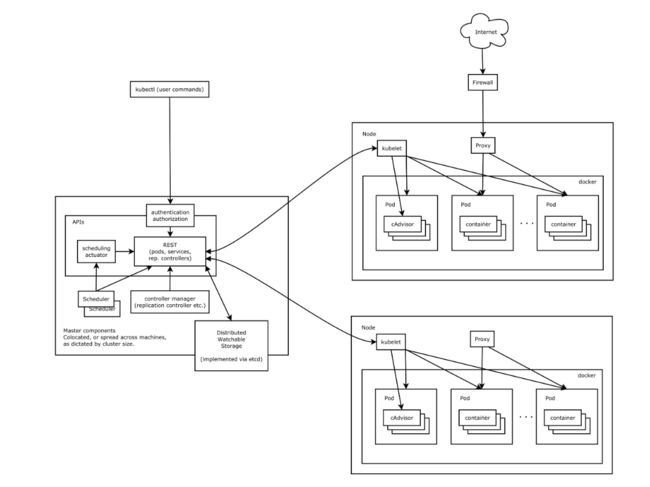
核心组件:
- etcd保存了整个集群的状态;
- apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
- controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
- kubelet负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
- Container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
- kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
分层架构:
- 核心层:k8s最核心的功能,对外提供API构建高层应用,对内可提供插件式的应用执行环境。
- 应用层:部署和路由
- 管理层:策略管理,自动化管理,以及系统度量。
- 接口层:kubectl命令行工具。
- 生态系统:外部:日志、监控、配置管理、CI、CD等 内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等。
第二章 实践指南
2.1 基本配置
apiVersion : v1 用来标识版本
kind : Pod/Service 类型可选Pod Service等
metadata: name: nameSpace:
2.4 Pod
- pod中的容器要求启动命令必须以前台命令作为启动命令【避免k8s 监控到pod运行结束 销毁,根据配置的RC副本数量重新启动,从而进入死循环】
- pod 可以由一个或者多个容器组合而成。
- pod中的多个容器只需要localhost就可以相互访问。
2.4.3 静态pod
静态pod 是由kubelet进行管理创建的只存在于特定Node上的Pod,kubelet无法对其进行静态检查,且一般只存在于kubelet所在的节点上。
且无法通过API server进行管理,也不会和ReplicationController Deployment产生关联。
创建方式: yml文件【配置文件】或者http请求
如何删除: 无法通过API server进行管理,所以Master无法对静态pod进行删除【状态更新为pending】。删除只能通过所在的node节点删除配置文件
2.4.4 容器共享volume
在同一个pod内的容器可以共享pod级别的volume
2.4.5 pod配置管理
pod可以通过k8s提供的集群化配置管理方案 configMap来实现配置信息和程序分离。
创建方式: yaml文件
2.4.6 生命周期和重启策略
生命周期 在系统内被定义为各种状态。可以分为 Pending Running Succeeded Failed Unknow
- Pending : API Server 已经创建好Pod,但是Pod内还有一个或者多个容器的镜像没创建,包括正在下载的镜像。
- Running : Pod内所有的容器已经创建成功,至少有一个容器处于运行,正在启动或者重启状态。
- Succeeded : Pod内的所有容器均成功执行退出,且不会再重新启动。
- Failed : 所有容器都已退出,至少有一个容器为退出失败状态。
- Unknow: 无法获取到Pod的状态。
重启策略 应用于Pod内的所有容器,并由Pod所在node节点上的kubelet进行状态判断和重启。当容器异常退出或者健康检查状态失败的时候,kubelet会根据所设置的重启策略重新启动该container
- always : 当容器失效时,有kubelet自动重启改容器。
- OnFailure : 容器运气终止且状态码不为0的时候。
- Never :无论状态如何都不重启该容器。
重启的间隔时间以设定的间隔时间的2n来计算,且在成功重启的10分钟后重置该时间。
不同的控制器对Pod的重启策略的要求是不一样的:
- RC和DaemonSet: 这2类控制器要求所管理的Pod 必须设置为Always,才能保障整个k8s周期内,提供服务的副本数量是满足要求的。
- Job: 这类控制器可根据需求灵活设定OnFailure 或者Never
- Kubelet: 由kubelet管理的一般是静态Pod,kubelet不会对其进行健康检查,Pod失效就回进行重启。和设置的重启策略没有关联。
2.4.7 健康检查
pod的健康检查可使用2类探针: LivenessProbe 和ReadinessProbe
- LivenessProbe :用来判断容器是否存活【running状态】若容器不处于running状态,则会有kubelet对容器根据设定的重启策略进行操作。若容器内不存在LivenessProbe探针,kubelet会认为容器的状态是succeed
- ReadinessProbe :用来判断容器是否是ready状态【这个状态下可以正常接收请求 处理任务】若ReadinessProbe 探针检查失败,EndPoint controller 会从service的endPoint中删除包含该容器所在Pod的endPoint不让该容器对外提供服务。
LivenessProbe 探针的实现方法
- ExecAction 在容器内执行命令若返回状态码为0 表示容器正常。
- TcpSocketAction 成功建立Tcp连接表示状态正常。
- HttpGetAction 对容器路径内调用httpGet方法若返回的状态码在200-400之间表示容器状态正常。
2.4.8 Pod的调度方式
1 RC Deployment
全自动调度,用户配置好应用容器的副本数量后RC会自动调度+持续监控始终让副本数量为此在规定的个数当中。
调度算法 系统内置的调度算法/NodeSelector/NodeAffinity
- 内置调度算法: 对外无感知,无法预知会调度到那个节点上,系统内完成的。
- NodeSelector 定向调度:在Pod上如果设置了NodeSelector属性 Scheduler会将该节点调度到和NodeSelector属性一致的带有Label的特定Node上去。【NodeSelector和Node Label精确匹配】
- NodeAffinity 亲和性调度: 在NodeSelector的基础上做了一些改进,可以设置在Node不满足当前调度条件时候,是否移除之前调度的Pod,以及在符合要求的Node节点中那些Node会被优先调度。
2 DaementSet
和RC类似,不同之处在于DaementSet控制每一台Node上只允许一个Pod副本实例,适用于需要单个Node运行一个实例的应用:
- 分布式文件存储相关 在每台Node上运行一个应用实例如GlusterFS Ceph
- 日志采集程序 logStach
- 每台Node上运行一个健康程序,来读当前Node的健康状态进行采集。
3 Job 批处理任务调度
批处理模型
- Job Template Expansion : 一个待处理的工作项就对应一个Job,效率较低。
- Queue with Per Pod Work Item : 使用队列存储工作项,一个Job作为消费者消费队列中的工作项,同时启动和队列中work Item数量对应的Pod实例。
- Queue with Variable Pod Work Item : 同per Pod 模式,不同之处在于Job数量是可变的。
这里在项目中的具体应用待更新,现在项目所用的k8s 调度模型【后续会单独写篇文章更新】
2.4.9 Pod的扩缩容
手动更新 kubectl scale命令更新RC的副本实例数量
自动更新 使用HAP控制器,基于在controller-manager设置好的周期,周期性的对Pod的cup占用率进行监控,自动的调节RC或者Deployment中副本实例进行调整来达到设定的CPU占用率。
2.5 service
service可以为一组具有相同功能的容器提供一个统一的入口地址,并将请求负载进行分发到后端各个容器应用上。
2.5.2 service的基本使用
直接使用RC创建多个副本和创建SVC提供服务的异同
直接创建RC

- 先定义RC yaml文件,如上所示
- 执行创建命令
kubectl create -f name.yaml - 查看提供服务的Pod地址
kubectl get pods -l app=webapp -o yaml | grep podIP
因为RC配置的副本实例数量为2 所以可得2个可用的Pod EndPoint 分别为172.17.172.3:80 172.17.172.4:80 无论任何一个Pod出现问题,kubelet 会根据重启策略对Pod进行重新启动,再次查询PodIP会发现PodIP发生变化
使用SVC
因为Pod的不可靠,重新启动被k8s调度到其他Node上会导致实例的endpoint不一样。且在分布式部署的情况下,多个容器对外提供服务,还需要在Pod前自己动手解决负载均衡的问题,这些问题都可通过SVC解决。
创建方式 : kubectl expose命令/配置文件
kubectl expose命令
- 创建SVC
kubectl expose rc webapp此时端口号会根据之前RC设置的containerPort 来进行设置 - 查看SVC
kubectl get SVC
配置文件方式启动
定义的关键在于 selector 和ports


负载分发策略 RoundRobin/SessionAffinity/自定义实现
- RoundRobin : 轮询策略
- SessionAffinity : 基于客户端IP的回话保持策略,相同IP的会话,会落在后端相同的IP上面。
- 自定义实现: 不给SVC设置clusterIP 通过label selector拿到所有的实例地址,根据实际情况来选用。
2.5.3 集群外部访问SVC或者Pod
思路是把SVC或者pod的虚拟端口映射到宿主机的端口,使得客户端应用可以通过宿主机端口访问容器应用。
将容器应用的端口号映射到主机
1 容器级别 设置hostPort = prodNum yaml中的配置表为hostPort: 8081,指的是绑定到的宿主机端口。HostPort和containerPort可以不相等
2 Pod级别 设置hostNetWork = true 这时候设置的所有的containerPort 都会直接映射到宿主机相同的端口上。默认且必须是HostPort = containerPort,若显示的指定HostPort和containerPort不相等则无效。
将SVC端口号映射到主机
关键配置为 kind = service type = NodePort nodePort = xxxxx,同时在物理机上对防火墙做对应的设置即可。
2.5.4 搭建DNS
可以直接完成服务名称到ClusterIP的解析。由以下部分组成
- 1 etcd DNS信息存储
- 2 kube2sky 将k8sMaster中的 service注册到etcd
- 3 skyDNS 提供DNS解析
- 4 healthz 提供对skyDNS的健康检查
第三章 原理分析
3.1 API Server
主要提供了各类资源对象【SVC Pod RC】等的增删查改以及Watch等Http Rest接口,是各个模块之间的数据交互和通讯的枢纽。
Kubernetes API Server : 提供API接口来完成各种资源对象的创建和管理,本身也是一个SVC 名称为Kubernetes
Kubernetes Proxy API :负责把收到的请求转到对应Node上的kubelet守护进程的端口上,kubelet负责相应,来查询Node上的实时信息 包括node pod SVC等 多用于集群外想实时获取Node内的信息用于状态查询以及管理。 【kubelet也会定时和etcd 同步自身的状态,和直接查询etcd存在一定的差异,这里强调实时】
集群模块之间的通信: 都需要通过API Server 来完成模块之间的通信,最终会将资源对象状态同步到etcd,各个集群模块根据通过API Server在etcd定时同步信息,来对所管理的资源进行相应处理。
3.2 Controller Manager
集群内部的管理中心,负责集群内部的Node Pod Endpoint Namespace 服务账号(ServiceAccount)资源定额(ResourceQuota)等的管理。出现故障时候会尝试自动修复,达到预期工作状态。
3.2.1 Replication Controller
一般我们把资源对象 Replication Controller 简写为RC 是为了区别于Controller Manager 中的Replication Controller【副本控制器】,副本控制器是通过管理资源对象RC来达到动态调控Pod的
副本控制器Replication Controller的作用:
- 【重新调度】确保当前集群中存在N个pod实例,N是在RC中定义的Pod实例数量
- 【弹性扩容】通过调整RC中配置的副本实例个数在实现动态扩缩容。
- 【滚动升级】通过调整RC中Pod模板的镜像版本来实现滚动升级。
3.2.2 Node Controller
Node节点在启动时候,会同kubelet 主动向API Server汇报节点信息,API Server将节点信息存储在etcd中,Node Controller通过API Server获取到Node的相关信息对Node节点进行管理和监控。
节点状态包括:就绪 未就绪 未知三种状态
3.2.3 ResourceQuota Controller
资源配额管理,确保指定资源对象在任一时刻不会超量占用系统物理资源。支持以下维度的系统资源配额管理
- 容器级别可以CPU和Memory进行限制
- Pod级别可以对一个Pod内的所有容器进行限制。
- Namespace级别,可以对多租户进行限制,包括Pod数量,Replication Controller数量,SVC数量 ResourceQuota 数量等。
3.2.4 Namespace Controller
用户通过API server 设置的Namespace会保存在etcd中,Namespace Controller会定时的获取namespace状态,根据所得状态对不同的namespace进行相应的删除,释放namespace下对应的物理资源。
3.2.5 SVC Controller& Endpoint Controller
Endpoints 表示一个svc对应的所有的pod的访问地址,Endpoint Controller是负责维护和生成所有endpoint对象的控制器。
每个Node对应的kube-proxy获取到svc对应的Endpoints来实现svc的负载均衡。
3.3 Scheduler
Scheduler 主要是接受controller Manager创建的pod为Pod选定目标Node,调度到合适的Node后,由Node中的kubelet负责接下来的管理运维。
过程中涉及三个对象 待调度的Pod列表,空闲的Node列表,调度算法和策略。
也就是根据调度算法和策略为待调度的每个Pod从空闲的Node中选择合适的。 随后kubelet通过API Server监听到Pod的调度事件,获取对应的Pod清单,下载Image镜像,并启动容器。
3.3.1 默认的调度流程如下:1&2
1【预选调度】遍历所有的Node节点,选出合适的Node
2优选策略确定最优节点
3.4 Kubelet
每个Node节点中都会启动一个Kubelet,该进程用于处理Master节点下发到本节点的任务,管理Pod以及Pod中的容器,每个Kubelet都会向API Server注册自身信息,定期和Master节点汇报Node节点资源使用情况。
容器健康检查
使用2类探针LivenessProbe 和ReadinessProbe
资源监控
使用cAdvisor
总结:kubelet 作为连接K8s Master节点机和Node机器的桥梁,管理运行在Node机器上的Pod和容器,同时从cAdvisor中获取容器使用统计信息,然后通过API Server上报资源使用信息。
3.5 Kube-Proxy
SVC是对一组提供相同服务Pod的抽象,会根据访问策略来访问这一组Pod。在每一个Node节点上都存在一个Kube-proxy,可以在任意Node上发起对SVC的访问请求。
SVC的ClusterIp和NodePort等概念是kube-proxy服务通过IPtables的NAT转换实现重定向到本地端口,再均衡到后端的Pod
3.6 集群安全机制
待补充
3.7 网络原理
k8s+docker 网络原理常常涉及到以下问题
- 1 k8s的网络模型是什么?
- 2 Docker的网络基础是什么?
- 3 Docker的网络模型和局限?
- 4 k8s的网络组件之间是如何通讯的?
- 5 外部如何访问k8s集群?
- 6 有那些开源组件支持k8s网络模型?
1 k8s的网络模型
IP-per-Pod:每个Pod都有自己独立的IP,无论是否处于同一个Node节点,Pod直接都可以通过IP相互访问。同时Pod内的容器共享一个网络堆栈【=网络命名空间 包括IP地址,网络设备,配置等】按照这个网络模型抽象出来的一个Pod对应一个IP也叫IP-per-Pod
Pod内部应用程序看到的自己的IP+port和pod外部的应用程序看到的IP+port是一致的,他们都是Pod实际分配的ip地址,从docker0上分配的。这样可以不用NAT来进行转换,设计的原则是为了兼容以前的应用 。
K8S对网络的要求:
- 所有容器在不通过NAT的方式下和其他容器进行通讯
- 所有节点在不使用NAT的方式下和容器相互通讯
- 容器的地址和外部看到的地址是同一个地址
2 Docker的网络基础是什么?
- Docker使用网络命名空间来达到不同容器之间的网络隔离【不同的网络命名空间内的 IP地址 网络设备 配置等是相互隔离不可见的】
- Docker 使用Veth设备对来达到2个不同的网络命名空间的相互访问。【Veth设备对可以直接将2个不同的网络命名空间连接起来,其中一端称为另一端的peer 从a端发送数据时候会直接触发b端的接受操作,从而达到不同容器之间相互访问的目的】
由于网络命名空间以及Veth设备对是建立在同一个linux内核的基础上。所以Docker的跨主机通讯处理的不够友好。
3 Docker的网络模型和局限?
- host模式 使用
--net= host指定 - container模式 使用
--net = container: Id_or_NAME指定 - none模式 使用
--net= none指定 - bridge模式 使用
--net = bridge指定
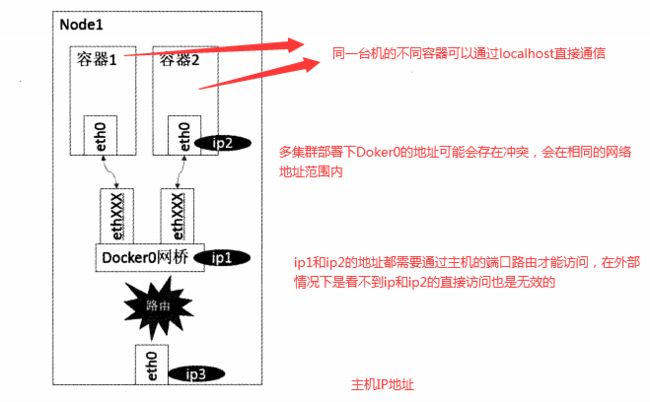
bridge模式 : 也是docker默认的网络模型,在这个模型下Docker第一次启动会创建一个新的网桥 大名鼎鼎的docker0,每个容器独享一个网络命名空间,且每一个容器具有一个Veth设备对,一端连接容器设备eth0一端连接网桥,docker0。如下图:
4 k8s的网络组件之间是如何通讯的?
- 容器到容器之间的通讯
- Pod到Pod之间的通讯
- Pod到Service之间的通讯
- 集群外与内部组件之间的通讯
容器到容器之间的通讯
同一个Pod内的容器共享同一个网络命名空间,可以直接使用Localhost进行通讯,不同Pod之间容器的通讯可以理解为Pod到Pod OR Pod到SVC之间的通讯
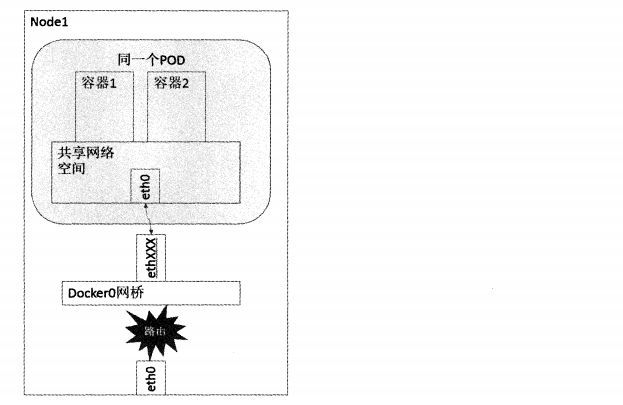
Pod到Pod之间的通讯
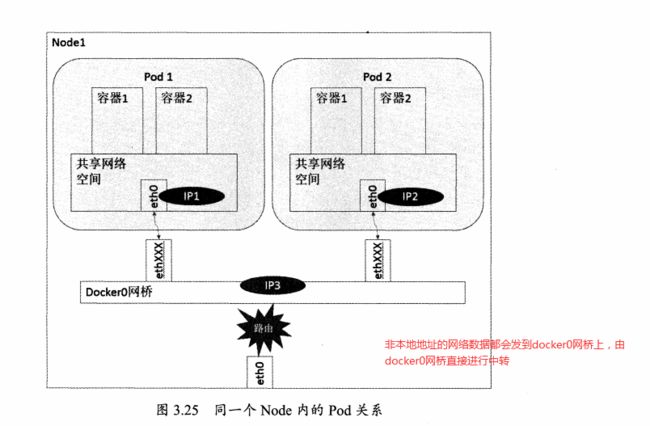
可以分为同一个Node内Pod之间的通讯&不同Node内Pod之间的通讯
同Node内Pod
同一Node中Pod的默认路由都是docker0的地址,由于它们关联在同一个docker0网桥上,地址网段相同,可以直接进行通讯。
不同Node的Pod
docker0网段和宿主机的网卡是2个不同的IP段,Pod地址和docker0处于同一网段。所以为了使不同Node之间的Pod可以通讯,需要将PodIP和所在Node的IP进行关联且保证唯一性。
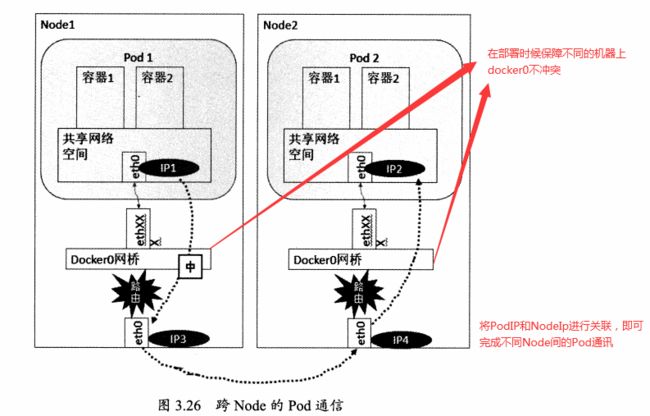
Pod到Service之间的通讯
SVC是对一组Pod服务的抽象,相当于一组服务的负载均衡。且对外暴露统一的clusterIP,所以Pod到SVC之间的通讯可以理解为Pod到Pod之间的通讯
集群外与内部组件之间的通讯
集群外和内部组件之间通讯,将Pod OR SVC端口绑定到物理机端口即可。