整理:戴季国(Flink 社区志愿者)
校对:苗文婷(Flink 社区志愿者)
摘要:本文由腾讯高级工程师杜立分享,主要介绍腾讯实时计算平台针对 Flink SQL 所做的优化,内容包括:
- Flink SQL 现状
- 窗口功能的扩展
- 回撤流的优化
- 未来的规划
一、背景及现状
1. 三种模式的分析

Flink 作业目前有三种创建方式:JAR 模式、画布模式和 SQL 模式。不同的提交作业的方式针对的人群也是不一样的。
■ Jar 模式
Jar 模式基于 DataStream/DataSet API 开发,主要针对的是底层的开发人员。
- 优点:
· 功能灵活多变,因为它底层的 DataStream/DataSet API 是 Flink 的原生 API,你可以用它们开发任何你想要的算子功能或者 DAG 图;
· 性能优化方便,可以非常有针对性的去优化每一个算子的性能。
- 缺点:
· 依赖更新繁琐,无论扩展作业逻辑或是 Flink 版本的升级,都要去更新作业的代码以及依赖版本;
· 学习门槛较高。
■ 画布模式
所谓的画布模式,一般来讲会提供一个可视化的拖拉拽界面,让用户通过界面化的方式去进行拖拉拽操作,以完成 Flink 作业的编辑。它面向一些小白用户。
- 优点:
· 操作便捷,画布上可以很方便地定义 Flink 的作业所包含的各种算子;
· 功能较全,它基于 Table API 开发,功能覆盖比较完整;
· 易于理解,DAG 图比较直观,用户能够非常容易的去理解整个作业的运行流程。
- 缺点:
· 配置复杂:每一个算子都需要去逐个的去配置,如果整个 DAG 图非常复杂,相应的配置工作也会非常大;
· 逻辑重用困难:如果作业非常的多,不同的作业之间想去共享 DAG 逻辑的话非常困难。
■ SQL 模式
SQL 语言已经存在了很长时间了,它有自己的一套标准,主要面向数据分析人员。只要遵循既有的 SQL 标准,数据分析人员就可以在不同的平台和计算引擎之间进行切换。
- 优点:
· 清晰简洁,易于理解和阅读;
· 与计算引擎解耦,SQL 与计算引擎及其版本是解耦的,在不同的计算引擎之间迁移业务逻辑不需要或极少需要去更改整段 SQL。同时,如果想升级 Flink 版本,也是不需要去更改 SQL;
· 逻辑重用方便,可以通过 create view 的方式去重用我们的 SQL 逻辑。
- 缺点:
· 语法不统一,比如说流与维表 Join,Flink 1.9 之前使用 Lateral Table Join 语法,但是在 1.9 之后,更改成了 PERIOD FOR SYSTEM_TIME 语法,这种语法遵循了 SQL ANSI 2011 标准。语法的变动使得用户有一定的学习成本;
· 功能覆盖不全:Flink SQL 这个模块存在的时间不是很长,导致它的功能的一个覆盖不是很全。
· 性能调优困难:一段 SQL 的执行效率主要由几个部分来决定,一个就是 SQL 本身所表达的业务逻辑;另一部分是翻译 SQL 所产生的执行计划的一个优化;第三部分的话,在产生最优的逻辑执行计划之后,翻译成本地的 native code 的时候方案也决定了 SQL 的执行效率;对于用户来讲的,他们所能优化的内容可能只局限于 SQL 所表达的业务逻辑。
· 问题定位困难:SQL 是一个完整的执行流程,如果我们发现某些数据不对,想针对性地去排查到底是哪个算子出了问题,是比较的困难的。一般来讲,我们想定位 Flink SQL 的问题,只能先不断的精简我们的整个 SQL 逻辑,然后不断地去尝试输出,这个成本是非常高的。腾讯实时计算平台后期会针对这个问题,增加 trace 日志和 metrics 信息,输出到产品侧以帮助用户定位 Flink SQL 使用上的问题。
2. 腾讯实时计算平台目前的工作
■ 扩展语法
定义了 window table-valued function 语法,以帮助用户实现基于窗口的流 Join 和交并差操作。另外,实现了自己的流与维表 Join 的语法。
■ 新增功能
新增的一些功能,包括两个新的 Window 的类型,Incremental Window(增量窗口)和 Ehanced Tumble Window(增强窗口)。实现了 Eventtime Field 与 Table Source 的解耦,很多时候 Eventtime Field 并不能通过 Table Source 字段定义出来,比如 Table Source 是一个子查询或者某个时间字段是由函数转换得出,想要用这些中间生成的时间字段作为 Eventtime Field 目前是做不到的,我们目前的方案是,让用户可以选择物理表中任意的时间字段来定义 Window 的时间属性并输出 WaterMark。
■ 性能调优
- 回撤流优化;
- 内联 UDF,如果相同的 UDF 既出现在 LogicalProject 中,又出现在 Where 条件中,那么 UDF 会进行多次调用。将逻辑执行计划中重复调用的 UDF 提取出来,将该 UDF 的执行结果进行缓存,避免多次调用;
■ Bucket Join
流表维表 Join 中存在数据冷启动问题,如果 Flink 任务在启动时大量加载外部数据,很容易造成反压。可以在启动时利用 State Processor API 等手段将全部数据预加载到内存中。但这种方案存在一种问题,维表数据加载到所有的 subtask 里面会造成较大的内存消耗。因此我们的解决方案是,在维表的定义中指定一个 bucket 信息,流与维表进行 Join 的时候会基于 bucket 信息去加载维表中对应分片的数据,同时在翻译执行计划的时候流表拿到 bucket 信息,以保证流与维表的数据都会基于同一个 bucket 信息进行 Join。这种方式能大大减少全量维表数据预加载带来的内存消耗问题。
二、 窗口功能扩展
腾讯实时计算平台基于现有 Flink SQL 语法进行了一些扩展,并另外定义了两种新的 Window 类型。
1. 新的窗口操作
现有如下需求,需要在两条流上针对某个时间窗口做 Join 操作或者交并差操作。
使用 Flink SQL 基于某个 Window 去做双流 Join,现有的方案有两种,第一种方案就是先做 Join 再做 Group By,第二种就是 Interval Join。首先来分析一下第一种方案能否满足需求。
■ 1.1 先 Join 再开窗

先 Join 再开窗的逻辑如上图所示,根据逻辑执行计划可以看到 Join 节点在 Window Aggregate 节点之下,所以会先进行流与流的 Join,Join 完了之后再去做Window Aggregate。
图中右侧的流程图也可以看出,首先两边的流会做一个 Connect,然后基于 Join Key 做 Keyby 操作,以此保证两条流中拥有相同 Join Key 的数据能够 Shuffle 到同一个 task 上。左流会将数据存到自己的状态中,同时会去右流的状态中进行 Match,如果能 Match 上会将 Match 后的结果输出到下游。这种方案存在以下两个问题:
- 状态无法清理:因为 Join 在开窗之前,Join 里面并没有带 Window 的信息,即使下游的 Window 触发并完成计算,上游两条流的 Join 状态也无法被清理掉,顶多只能使用基于 TTL 的方式去清理。
- 语义无法满足需求:原始的需求是想在两条流中基于相同的时间窗口去把数据进行切片后再 Join,但是当前方案并不能满足这样的需求,因为它先做 Join,使用 Join 后的数据再进行开窗,这种方式不能确保两条流中参与 Join 的数据是基于同一窗口的。
■ 1.2 Interval Join

Interval Join 相对于前面一种写法,好处就是不存在状态无法清理的问题,因为在扫描左右两条流的数据时可以基于某一确定的窗口,过了窗口时间后,状态是可以被清理掉的。
但是这种方案相对于第一种方案而言,数据准确性可能会更差一点,因为它对于窗口的划分不是基于一个确定窗口,而是基于数据进行驱动,即当前数据可以 Join 的另一条流上的数据的范围是基于当前数据所携带的 Eventtime 的。这种窗口划分的语义与我们的需求还是存在一定差距的。
想象一下现有两条速率不一致的流,以 low 和 upper 两条边界来限定左流可以 Join 的右流的数据范围,在如此死板的范围约束下,右流总会存在一些有效数据落在时间窗口 [left + low, left + upper] 之外,导致计算不够准确。因此,最好还是按照窗口对齐的方式来划分时间窗口,让两条流中 Eventtime 相同的数据落在相同的时间窗口。
■ 1.3 Windowing Table-Valued Function
腾讯扩展出了 Windowing Table-Valued Function 语法,该语法可以满足“在两条流上针对某个时间窗口做 Join 操作或者交并差操作”的需求。在 SQL 2016 标准中就有关于这一语法的描述,同时该语法在 Calcite1.23 里面就已存在。

Windowing Table-Valued Function 语法中的 Source 可以把它整个的语义描述清楚,From 子句里面包含了 Window 定义所需要的所有信息,包括 Table Source、Eventtime Field、Window Size 等等。
从上图的逻辑计划可以看出,该语法在 LogiclTableScan 上加了一个叫 LogicalTableFunctionScan 的节点。另外,LogicalProject 节点(输出节点)多了两个字段叫作 WindowStart 和 WindowEnd,基于这两个字段可以把数据归纳到一个确定的窗口。基于以上原理,Windowing Table-Valued Function 语法可以做到下面这些事情:

- 在单流上面,可以像现有的 Group Window 语法一样去划分出一个时间窗口。写法如上图,Window 信息全部放到 From 子句中,然后再进行 Group By。这种写法应该更符合大众对于时间窗口的理解,比当前 Flink SQL 中的 Group Window 的写法更加直观一点。我们在翻译单流上的 Windowing Table-Valued Function 语法时做了一个讨巧,即在实现这段 SQL 的物理翻译时,并没有去翻译成具体的 DataStream API,而是将其逻辑执行计划直接变换到现在的 Group Window 的逻辑执行计划,也就是说共用了底层物理执行计划的代码,只是做了一个逻辑执行计划的等价。
另外,可以对 Window 里面的数据做一些 Sort 或者 TopN 的一些输出,因为 Windowing Table-Valued Function 语法已经提前把数据划分进了一个个确定的窗口。如上图所示,首先在 From 子句里面把窗口划分好,然后 Order By 和 Limit 紧接其后,直接表达了排序和 TopN 语义。
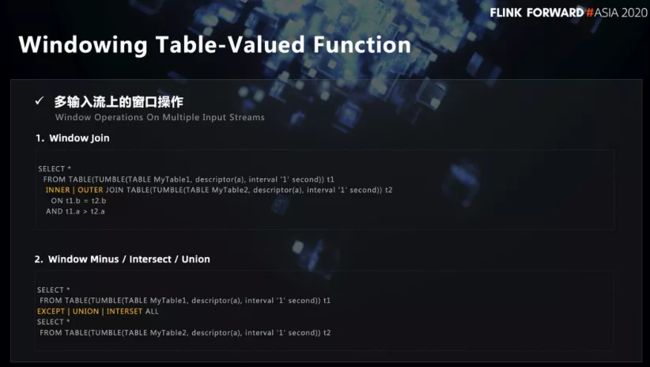
- 在双流上面,可以满足“在两条流上针对某个时间窗口做 Join 操作或者交并差操作”的原始需求。语法如上图,首先把两个窗口的 Window Table 构造好,然后利用 Join 关键字进行 Join 操作即可;交并差操作也一样,与传统数据库 SQL 的交并差操作无二。
■ 1.4 实现细节
下面简单介绍一下我们在实现 Windowing Table-Valued Function 语法时的一些细节。
1.4.1 窗口的传播
原始的逻辑计划翻译方式,先基于 LogicalTableScan,然后再翻译到 Windowing Table-Valued Function,最后再翻译到 OrderBy Limit 子句。整个过程会存储很多次状态,对于性能来讲会是比较大的一个消耗,因此做了如下优化,把多个 Logical Relnode 合并在一起去翻译,这样可以减少中间环节代码的产生,从而提高性能。
1.4.2 时间属性字段
可以看到 Windowing Table-Valued Function 的语法:
SELECT * FROM TABLE(TUMBLE(TABLE , DESCRIPTOR(), [, ])) table 不仅仅可以是一张表,还可以是一个子查询。所以如果定义 Eventtime Field 的时候,把时间属性和 Table Source 绑定,且 Table Source 恰好是一个子查询,此时就无法满足我们的需求。所以我们在实现语法的时候,把时间属性字段跟 Table Source 解耦,反之,用户使用物理表中的任意一个时间字段来作为时间属性,从而产生 watermark。
1.4.3 时间水印
Watermark 的使用逻辑与在其他语法中一样,两条流的所有的 Input Task 的最小时间水印,决定窗口的时间水印,以此来触发窗口计算。
1.4.4 使用约束
目前 Windowing Table-Valued Function 的使用存在一些约束。首先,两条流的窗口类型必须是一致的,而且窗口大小也是一样的。然后,目前还没有实现 Session Window 相关的功能。
2. 新的窗口类型
接下来的介绍扩展出两个新的窗口类型。
■ 2.1 Incremental Window
有如下需求,用户希望能够绘制一天内的 pv/uv 曲线,即在一天内或一个大的窗口内,输出多次结果,而非等窗口结束之后统一输出一次结果。针对该需求, 我们扩展出了 Incremental Window。
2.1.1 多次触发
基于 Tumble Window,自定义了 Incremental Trigger。该触发器确保,不仅仅是在 Windows 结束之后才去触发窗口计算,而是每个 SQL 中所定义的 Interval 周期都会触发一次窗口计算。

如上图中的 SQL 案例,总的窗口大小是一秒,且每 0.2 秒触发一次,所以在窗口内会触发 5 次窗口计算。且下一次的输出结果是基于上一次结果进行累计计算。
2.1.2 Lazy Trigger
针对 Incremental Window 做了一个名为 Lazy Trigger 的优化。在实际的生产过程中,一个窗口相同 Key 值在多次触发窗口计算后输出的结果是一样的。对于下游来讲,对于这种数据是没必要去重复接收的。因此,如果配置了 Lazy Trigger 的话,且在同一个窗口的同一个 Key 下,下一次输出的值跟上一次的是一模一样的,下游就不会接收到这次的更新数据,由此减少下游的存储压力和并发压力。
■ 2.2 Enhanced Tumble Window

有如下需求,用户希望在 Tumble Window 触发之后,不去丢弃迟到的数据,而是再次触发窗口计算。如果使用 DataStream API,使用 SideOutput 就可以完成需求。但是对于 SQL,目前是没办法做到的。因此,扩展了现有的 Tumble Window,把迟到的数据也收集起来,同时迟到的数据并不是每来一条就重新触发窗口计算并向下游输出,而是会重新定义一个 Trigger,Trigger 的时间间隔使用 SQL 中定义的窗口大小,以此减少向下游发送数据的频率。
同时,侧输出流在累计数据的时候也会使用 Window 的逻辑再做一次聚合。这里需要注意,如果下游是类似于HBase这样的数据源,对于相同的 Window 相同的 Key,前一条正常被窗口触发的数据会被迟到的数据覆盖掉。理论上,迟到的数据跟正常窗口触发的数据的重要性是一样的,不能相互覆盖。最后,下游会将收到的同一个窗口同一个 Key 下的正常数据和延迟数据再做一次二次聚合。
三、回撤流优化
接下来介绍一下在回撤流上所做的一些优化。
1. 流表二义性
回顾一下关于在 Flink SQL 中关于回撤流的一些概念。
首先介绍一下持续查询(Continuous Query),相对于批处理一次执行输出一次结果的特点,流的聚合是上游来一条数据,下游的话就会接收一条更新的数据,即结果是不断被上游的数据所更新的。因此,对于同一个 Key 下游能够接收到多条更新结果。
2. 回撤流

以上图的 SQL 为例,当第二条 Java 到达聚合算子时,会去更新第一条 Java 所产生的状态并把结果发送到下游。如果下游对于多次更新的结果不做任何处理,就会产生错误的结果。针对这种场景,Flink SQL 引入了回撤流的概念。
所谓回撤流的话,就是在原始数据前加了一个标识位,以 True/False 进行标识。如果标识位是 False,就表示这是一条回撤消息,它通知下游对这条数据做 Delete 操作;如果标识位是 True,下游直接会做 Insert 操作。
■ 2.1 什么时候产生回撤流
目前,Flink SQL 里面产生回撤流有以下四种场景:
- Aggregate Without Window(不带 Window 的聚合场景)
- Rank
- Over Window
- Left/Right/Full Outer Join
解释一下 Outer Join 为什么会产生回撤。以 Left Outer Join 为例,且假设左流的数据比右流的数据先到,左流的数据会去扫描右流数据的状态,如果找不到可以 Join 的数据,左流并不知道右流中是确实不存在这条数据还是说右流中的相应数据迟到了。为了满足 Outer join 的语义的话,左边流数据还是会产生一条 Join 数据发送到下游,类似于 MySQL Left Join,左流的字段以正常的表字段值填充,右流的相应字段以 Null 填充,然后输出到下游,如下图所示:

(图片来源于云栖社区)
后期如果右流的相应数据到达,会去扫描左流的状态再次进行 Join,此时,为了保证语义的正确性,需要把前面已经输出到下游的这条特殊的数据进行回撤,同时会把最新 Join 上的数据输出到下游。注意,对于相同的 Key,如果产生了一次回撤,是不会再产生第二次回撤的,因为如果后期再有该 Key 的数据到达,是可以 Join 上另一条流上相应的数据的。
■ 2.2 如何处理回撤消息

下面介绍 Flink 中处理回撤消息的逻辑。
对于中间计算节点,通过上图中的 4 个标志位来控制,这些标识位表示当前节点是产生 Update 信息还是产生 Retract 信息,以及当前节点是否会消费这个 Retract 信息。这 4 个标识位能够决定整个关于 Retract 的产生和处理的逻辑。
对于 Sink 节点,目前 Flink 中有三种 sink 类型,AppendStreamTableSink、RetractStreamTableSink 和 UpsertStreamTableSink。AppendStreamTableSink 接收的上游数据是一条 Retract 信息的话会直接报错的,因为它只能描述 Append-Only 语义;RetractStreamTableSink 则可以处理 Retract 信息,如果上游算子发送一个 Retract 信息过来,它会对消息做 Delete 操作,如果上游算子发送的是正常的更新信息,它会对消息做 Insert 操作;UpsertStreamTableSink 可以理解为对于RetractStreamTableSink 做了一些性能的优化。如果 Sink 数据源支持幂等操作,或者支持按照某 key 做 Update 操作,UpsertStreamTableSink 会在 SQL 翻译的时候把上游 Upsert Key 传到 Table Sink 里面,然后基于该 Key 去做 Update 操作。
■ 2.3 相关优化
我们基于回撤流做以下优化。
2.3.1 中间节点的优化

产生回撤信息最根本的一个原因是不断地向下游多次发送更新结果,因此,为了减少更新的频率并降低并发,可以把更新结果累计一部分之后再发送出去。如上图所示:
- 第一个场景是一个嵌套 AGG 的场景(例如两次 Count操作),在第一层 Group By 尝试将更新结果发送到下游时候会先做一个 Cache,从而减少向下游发送数据频率。当达到了 Cache 的触发条件时,再把更新结果发送到下游。
- 第二个场景是 Outer Join,前面提到,Outer Join 产生回撤消息是因为左右两边数据的速率不匹配。以 Left Outer Join 为例,可以把左流的数据进行 Cache。左流数据到达时会去右流的状态里面查找,如果能找到可以与之 Join的数据则不作缓存;如果找不到相应数据,则对这条 Key 的数据先做缓存,当到达某些触发条件时,再去右流状态中查找一次,如果仍然找不到相应数据,再去向下游发送一条包含 Null 值的 Join 数据,之后右流相应数据到达就会将 Cache 中该 Key 对应的缓存清空,并向下游发送一条回撤消息。
以此来减小向下游发送回撤消息的频率。
2.3.2 Sink 节点的优化

针对 Sink 节点做了一些优化,在 AGG 节点和 Sink 节点之间做了一个 Cache,以此减轻 Sink 节点的压力。当回撤消息在 Cache 中再做聚合,当达到 Cache 的触发条件时,统一将更新后的数据发送到 Sink 节点。以下图中的 SQL 为例:

参考优化前后的输出结果可以看到,优化后下游接收到的数据量是有减少的,例如用户 Sam,当回撤消息尝试发送到下游时,先做一层 Cache,下游接收到的数据量可以减少很多。
四、未来规划

下面介绍一下我们团队后续的工作规划:
- Cost-Based Optimization:现在 Flink SQL 的逻辑执行计划的优化还是基于RBO(Rule Based Optimization)的方式。我们团队想基于 CBO 所做一些事,主要的工作还是统计信息的收集。统计信息不仅仅来自 Flink SQL 本身,可能还会来自公司内其他产品,例如元数据,不同 Key 所对应的数据分布,或者其他数据分析结果。通过跟公司内其他产品打通,拿到最准的统计数据,产生最优的执行计划。
- More New Features(CEP Syntax etc.):基于 Flink SQL 定义一些 CEP 的语法,以满足用户关于 CEP 的一些需求。
- Continuous Performance Optimization(Join Operator etc.):我们团队在做的不仅仅是执行计划层的优化,也在做 Join Operator 或者说数据 Shuffle 的一些细粒度的优化。
- Easier To Debug:最后是关于 Flink SQL任务的调试和定位。目前 Flink SQL在这方面是比较欠缺的,特别是线上关于数据对不齐的问题,排查起来非常的棘手。我们目前的思路是通过配置的方式,让 SQL 在执行的过程中吐出一些 Trace 信息或者一些 Metrics 信息,然后发送到其他平台。通过这些 Trace 信息和 Metric 信息,帮助用户定位出问题的算子。