聊一聊Flink 写 Hive 的小文件问题
背景
Flink 1.11 引入了写Hive的功能后,已经在上线了一段时间。下面就聊聊我自己对Flink 写Hive 小文件的一些问题和看法。
问题1:
1.Flink 写 Hive 可能会产生小文件吗?
简单的说,答案是会。
简单总结下Flink 读kafka写Hive的流程
1.Flink 将kafka数据根据设置的分区策略,实时写入对应分区hdfs 目录的临时文件 inprogress,如下图所示。

在inprogress文件的数据,通过hive是无法查询到的。
2.打checkpoint时,将inprogress文件的数据刷到正式文件中,并提交kafka offset。
这里有一个关键的点:Flink中一个写hive的并行度,同一时间只能写一个hdfs文件
那么就有一个问题,如果我设置3个并行度,一个checkpoint周期是不是会生成3个文件呢?
这里有一个关键的参数:'sink.shuffle-by-partition.enable'
以上图hive表为例,一级分区为年月日,二级分区为小时,按照数据的event时间分区。
'sink.shuffle-by-partition.enable'=false
设置3个并行度,如下图所示
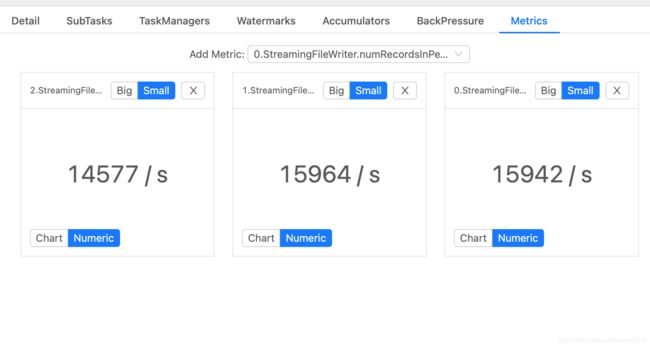
我们看到,3个并行度都有数据在写,那么hdfs上对应就有3个inprogress文件,checkpoint后会有对应的3个hdfs文件。(1.12的小文件合并功能下面再讨论)
'sink.shuffle-by-partition.enable'=true

我们可以看到,即使设置了3个并行度,也只有一个并行度有数据在写。这样的话,一个checkpoint周期中,只会生成一个hdfs文件。
但是这里有一个前提,当前所有数据都落在统一分区中,即当前小时,也就是说没有跨小时的延迟。
如果正好是跨小时的时候,由于我们使用的是eventtime 作为分区,例如10:00:01s时,既有10点的数据,也有9点的数据,那么就会有多个并行度有数据在写,这也很容易理解,因为不同分区,肯定是不同的hdfs文件。
通过这个特点,在'sink.shuffle-by-partition.enable'=true的情况下,我们也很容易看出,数据落地hive是否有延迟。
那么问题又来了。如果考虑到小文件的问题,什么情况下需要将'sink.shuffle-by-partition.enable' 设置为False?
我的答案是,当单个分区的写入速度超过单个并行度写入hive速度极限时,因为如果这时还设置为true,则会永远反压,消费的速度跟不上生产的速度。不过好在flink写hive在1.11.3版本之后,性能还是不错的。所以大部分情况,建议设置为true。
| 任务编号 | 业务数据量 | 写Hive单个并行度极限 | 并行度 | sink.shuffle-by-partition.enable |
| 1 | 10w/s | 4w/s | 3+ | flase |
| 2 | 3w/s | 4w/s | 2+ | true |
任务1: 10w数据会被平均分配到3个hdfs文件中,每个文件数据行数为3.3w/s*checkpoint周期。
任务2:在数据不跨小时延迟的情况下,3w数据会在1个hdfs文件中,每个文件数据行数为3w/s*checkpoint周期。
再通过设置checkpoint周期,我们可以大大减少小文件产生的概率。
但是如果时间到了凌晨,数据量很少的情况
| 任务编号 | 业务数据量 | 写Hive单个并行度极限 | 并行度 | sink.shuffle-by-partition.enable |
| 1 | 1k/s | 4w/s | 3+ | flase |
| 2 | 1k/s | 4w/s | 2+ | true |
任务1: 1k数据会被平均分配到3个hdfs文件中,每个文件数据行数为0.33k/s*checkpoint周期。
任务2:在数据不跨小时延迟的情况下,1k数据会在1个hdfs文件中,每个文件数据行数为1k/s*checkpoint周期。
这种情况下任务1的小文件会是任务2的3倍。这也是为什么我建议在性能更得上时,将sink.shuffle-by-partition.enable设置为true。
关于Flink 1.12的小文件自动合并。
官方链接:
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/table/connectors/filesystem.html#file-compaction
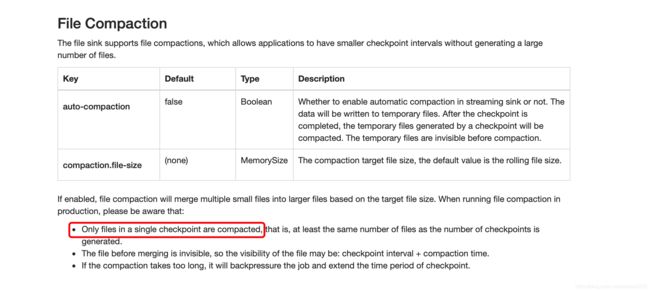
参数很简单,就是按照设置的文件大小合并。我想着重说下的是Only files in a single checkpoint are compacted 这句话,只有同一个checkpoint周期的文件会合并。
所以对于数据量少的凌晨,任务1的小文件数量会改善到任务2的水平,但是也无法完全避免小文件的存在。
结论
为了减少Flink 写Hive的小文件
1.性能满足的情况下,尽量设置'sink.shuffle-by-partition.enable'=true
2.如果设置了'sink.shuffle-by-partition.enable'=false,建议使用Flink 1.12版本的自动合并小文件功能。
3.设置合理的checkpoint周期,业务允许的情况下,可以加大checkpoint周期,减少生成文件的数量。
4.可以最大限度降低Flink产生小文件的情况,但是无法完全避免,根据实际情况定期合并小文件。
附上使用spark3 合并 小文件的攻略。
https://blog.csdn.net/xiaokan0230/article/details/114676638