hadoop学习笔记6-sqoop
一.sqoop基础
1.sqoop也是apache的项目
2.sql-to-hadoop比如将mysql的数据导入到hdfs中,反过来也是
以前我老记不住sqoop是干嘛的,但是把他分解成sql-to-hadoop,就好记了
3.sqoop作业:用于定时执行。
数据导出导入,sqoop作业是重点
5.sqoop怎么和hadoop合作
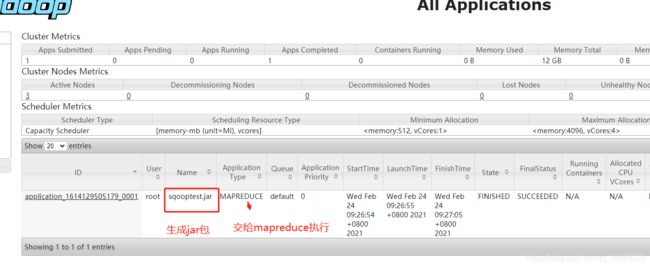
sqoop接到导入导出命令后,生成mapreduce代码,打成jar包,提交给hadoop

这个jar保命称,我执行过程中发现他是根据表名自动生成得
二.安装过程
1.下载
我是本地有压缩包直接上传的

2.修改环境变量
解压后修改环境变量
修改后记得source一下在echo输出验证一下
3.修改配置文件
修改bin下configure-sqoop,注释掉HCAT_HOME和ACCUMULO_HOME相关命令
我也不知道这步省略行不行,没试
4.验证
sqoop version
6.上传驱动包
把mysql-connector-java-5.1.27-bin.jar上传到sqoop的lib下
7.hdfs的配置(无需修改)
三.sqoop命令
1.全表导入
我才发现我没写端口号居然也执行成功了
sqoop import --connect jdbc:mysql://localhost/test --username root --password root
--table sqooptest -m 1
最后一个-m后边跟的1是因为现在sqoop是单机的 所以是1
导入成功之后 用hdfs命令查看
hdfs dfs -cat /user/root/sqooptest/* 注意那个/* 他导入之后会在文件夹下产生不止一个文件


2.指定导入列
--columns 列1,列2
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --table sqooptest
--columns sex -m 1
3.where条件
--where "条件"
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --table sqooptest
--where "sex='woman'" -m 1
4.columns和where结合使用
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --table sqooptest
--columns sex,name --where "sex='woman' or name='bdy'" -m 1
5.指定导入到hdfs的位置
--target-dir
之前没指定时候都是导入到默认位置
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --table sqooptest -m 1
--target-dir /user/xysqoop
6.query查询
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --target-dir /xy2 -m 1
--query "select * from sqooptest where sex='woman' and \$CONDITIONS"
有query就不用指定--table了
最后那个and \$CONDITIONS是必须要带着的
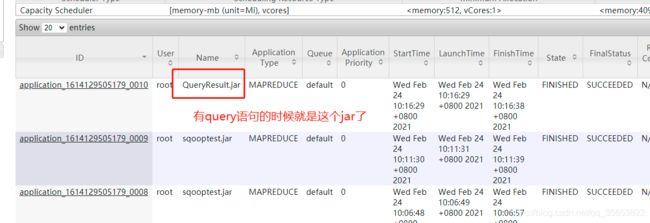
我执行过程中发现有query语句时,生成得jar包名称不太一样
四.增量导入
1.增量导入方式
1.1.append 只增加数据 不更新数据
需要有一个int型字段
1.2.lastmodified 更新
需要有一个时间字段
--append和--merge-key两种方式,下边执行命令时候会具体展开讲
以上几种 个人觉得lastmodified+--merge-key id更好
2.append增量导入
1.先全表导入
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --target-dir /xy3 -m 1 --table sqooptest
2.查看数据
hdfs dfs -cat /xy3/*
3.在表中添加数据

4.用append模式增量导入
sqoop import --connect jdbc:mysql://172.20.31.170/test --username root --password root --target-dir /xy3 -m 1 --table sqooptest
--check-column id(需要一个int型字段)
--incremental append(指定增量导入的模式)
--last-value 5(上次导入的最大值是5)
5.看日志

6.查看增量导入结果

3.lastmodified模式增量导入
1.先准备一张有时间字段得表,全表导入
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --target-dir /xy_lasttime -m 1 --table sqooptest
2.hdfs查看
3.lastmodified --append增量导入
sqoop import --connect jdbc:mysql://172.20.31.170/test --username root --password root --target-dir /xy_lasttime -m 1 --table sqooptest
--check-column update_time(需要一个时间型字段)
--incremental lastmodified(指定增量导入的模式)
--last-value "2021-02-23 10:38:00"(上次导入的最大值是5)
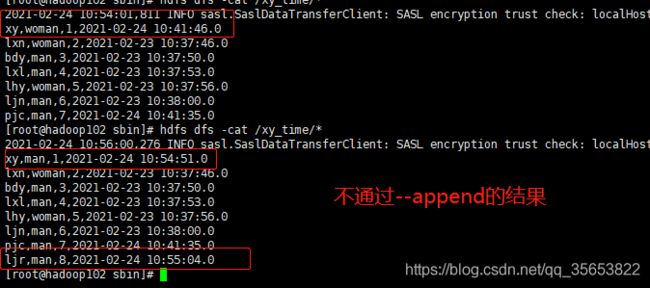
--append (更新且增加:比如我把xy的性别改为woman 然后我再通过lastmodified模式导入 会发现woman这条数据是添加过来了 但是man那条数据也还在)
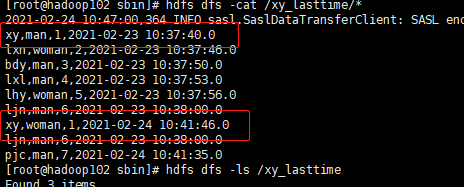
以下为运行截图:可以看到把修改后得记录新增过来了
通过lastmodified --append增量导入的结果
4.lastmodified --merge-key增量导入
把--append改为--merge-key 字段 通过merge-key指定一个唯一值字段 我指定的是主键 这样就不会在结果中出现两条数据了
而是通过这个唯一字段进行合并更新 执行命令如下
sqoop import --connect jdbc:mysql://localhost/test --username root --password root --target-dir /xy_time -m 1 --table sqooptest
--check-column update_time
--incremental lastmodified
--last-value "2021-02-24 10:41:35"
--merge-key id(唯一字段)
以下为运行截图:可以看到把修改后得字段更新了,并且把添加的记录也同步过来了