MNIST在CPU、FPGA、ARM上的运行对比
MNIST在CPU、FPGA、ARM上的运行对比
- CPU与FPGA对比
-
- CPU
- FPGA
- CPU上进行MNIST推断
-
- 环境配置
- 实验代码
- 实验结果
- FPGA上进行MNIST推断
-
- 环境配置
- 实验代码
- 实验结果
CPU与FPGA对比
CPU
CPU是通用处理器,串行的执行指令。
CPU、GPU 都属于冯·诺依曼结构,指令译码执行、共享内存。冯氏结构中,由于执行单元(如 CPU 核)可能执行任意指令,就需要有指令存储器、译码器、各种指令的运算器、分支跳转处理逻辑。由于指令流的控制逻辑复杂,不可能有太多条独立的指令流,因此 GPU 使用 SIMD(单指令流多数据流)来让多个执行单元以同样的步调处理不同的数据,CPU 也支持 SIMD 指令。
FPGA
FPGA是硬件可重构体系,可以并行的进行运算,所以有强大的计算量,而且灵活性非常高。
FPGA 每个逻辑单元的功能在重编程(烧写)时就已经确定,不需要指令。FPGA 非常更适合做需要低延迟的流式处理,而像GPU 适合做大批量同构数据的处理。
FPGA在某些方面有优势在某些方面也有劣势,FPGA适合并行、低延迟计算,但CPU就适合处理数据信息。缺少指令同时也是 FPGA 的优势和软肋。每做一点不同的事情,就要占用一定的 FPGA 逻辑资源。如果要做的事情复杂、重复性不强,就会占用大量的逻辑资源,其中的大部分处于闲置状态。这时就不如用冯·诺依曼结构的处理器。因此FPGA 和 CPU 协同工作,局部性和重复性强的归 FPGA,复杂的归 CPU。
下面我们来对MNIST手写体识别在CPU和FPGA运行速度(只看推理速度)做个对比。
CPU上进行MNIST推断
环境配置
tensorflow = 1.14
keras = 2.2.5
numpy = 1.19
matplotlib = 3.3.4
CPU环境配置较为简单,直接在Anaconda Prompt通过pip安装tensorflow和keras即可,注意两者版本匹配。
实验代码
#####训练代码
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.core import Dense
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 读取并划分MNIST训练集、测试集
X_train = X_train.reshape(len(X_train), -1) # 二维变一维
X_test = X_test.reshape(len(X_test), -1)
X_train = X_train.astype('float32') # 转为float类型
X_test = X_test.astype('float32')
X_train = (X_train - 127) / 127 # 灰度像素数据归一化
X_test = (X_test - 127) / 127
y_train = np_utils.to_categorical(y_train, num_classes=10) # one-hot编码
y_test = np_utils.to_categorical(y_test, num_classes=10)
# 定义模型
model = Sequential() # Keras序列模型
model.add(Dense(20, input_shape=(784,), activation='relu')) # 添加全连接层(隐藏层),隐藏层数20层,激活函数为ReLU
model.add(Dense(10, activation='sigmoid')) # 添加输出层,结果10类,激活函数为Sigmoid
print(model.summary()) # 模型基本信息
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # 编译模型
# 训练
model.fit(X_train, y_train, epochs=20, batch_size=64, verbose=1, validation_split=0.05) # 迭代20次
# 评估
loss, accuracy = model.evaluate(X_test, y_test)
print('Test loss:', loss)
print('Accuracy:', accuracy)
# 保存
model.save('mnistmodel.h5')
#####推断代码
import random
import numpy as np
import time
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import load_model
# 加载训练好的模型
mymodel = load_model('.\mnistmodel.h5')
# 数据集
(_, _), (X_test, y_test) = mnist.load_data() # 划分MNIST训练集、测试集
while True:
# 随机数
index = random.randint(0, X_test.shape[0])
x = X_test[index]
y = y_test[index]
# 显示该数字
plt.imshow(x, cmap='gray_r')
plt.title("original {}".format(y))
plt.show()
# 预测
x.shape = (1, 784) # 变成[[]]
start = time.clock()
predict = mymodel.predict(x)
predict = np.argmax(predict) # 取最大值的位置
end = time.clock()
print('index:', index)
print('original:', y)
print('predicted:', predict)
print('Inference took %.2f microseconds' % ((end-start)*1000000))#计算运行时间
print('Classification rate: %.2f images per second' % (1/(end - start)))#计算每秒处理张数
print()
q = input('回车继续,q退出')
if q == 'q':
break
实验结果
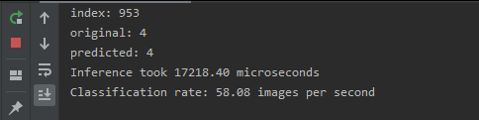
可以看到在CPU上识别一张28*28的手写体文本需要17218微秒,处理速度为:58images/s。
FPGA上进行MNIST推断
本方法采用PYNQ开发板,其中包括了PS-PL系统,PS系统是ARM驱动,PL是FPGA驱动,因此在该开发板上可以完成FPGA、ARM识别实验。
环境配置
PYNQ嵌入了强大的Python第三方库,但是本方法使用的是BNN(二值神经网络),在PYNQ上无法直接通过pip安装,但是Github上有开源的BNN网络,直接Git并安装即可。
BNN库Github链接:PYNQ-BNN
实验代码
#####数据处理
import bnn
print(bnn.available_params(bnn.NETWORK_LFC))
classifier = bnn.PynqBNN(network=bnn.NETWORK_LFC)
classifier.load_parameters("mnist")
from PIL import Image as PIL_Image
from PIL import ImageEnhance
from PIL import ImageOps
orig_img_path = 'image.jpg'
img = PIL_Image.open(orig_img_path).convert("L") # convert in black and white
#Image enhancement
contr = ImageEnhance.Contrast(img) #增强对比度
img = contr.enhance(3) # The enhancement values (contrast and brightness)
bright = ImageEnhance.Brightness(img) # depends on backgroud, external lights etc
img = bright.enhance(4.0)
#Adding a border for future cropping
img = ImageOps.expand(img,border=80,fill='white')
from PIL import Image as PIL_Image
import numpy as np
import math
threshold = 180
img = img.point(lambda p: p > threshold and 255) #图片二值化
immat = img.load()
(X, Y) = img.size
m = np.zeros((X, Y))
# Spanning the image to evaluate center of mass
for x in range(X):
for y in range(Y):
m[x, y] = immat[(x, y)] <= 250
m = m / np.sum(np.sum(m))
dx = np.sum(m, 1)
dy = np.sum(m, 0)
# Evalate center of mass
cx = math.ceil(np.sum(dx * np.arange(X)))
cy = math.ceil(np.sum(dy * np.arange(Y)))
img = img.crop((cx-80,cy-80,cx+80,cy+80))
from array import *
from PIL import Image as PIL_Image
# Resize the image and invert it (white on black)
smallimg = img.resize((28, 28))
smallimg = ImageOps.invert(smallimg)
data_image = array('B')
pixel = smallimg.load()
for x in range(0, 28):
for y in range(0, 28):
data_image.append(pixel[y, x])
# Setting up the header of the MNIST format file
hexval = "{0:#0{1}x}".format(1, 6)
header = array('B')
header.extend([0, 0, 8, 1, 0, 0])
header.append(int('0x' + hexval[2:][:2], 16))
header.append(int('0x' + hexval[2:][2:], 16))
header.extend([0, 0, 0, 28, 0, 0, 0, 28])
header[3] = 3 # Changing MSB for image data (0x00000803)
data_image = header + data_image
output_file = open('/home/xilinx/image.images-idx3-ubyte', 'wb')
data_image.tofile(output_file)
output_file.close()
#####Hardware推断测试(FPGA运行)
classifier.inference("/home/xilinx/image.images-idx3-ubyte")
#####Software推断测试(ARM运行)
classifier_sw3 = bnn.PynqBNN(network=bnn.NETWORK_LFC,runtime=bnn.RUNTIME_SW)
classifier_sw3.load_parameters("mnist")
classifier_sw3.inference("/home/xilinx/image.images-idx3-ubyte")
实验结果
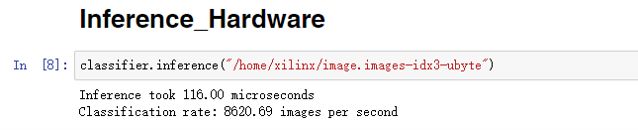
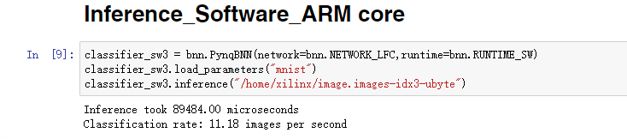
由以上结果可以看出,在FPGA上运行一张2828手写体识别只需116微秒,处理速度为:8621images/s;在ARM上运行一张2828手写体识别需89484微秒,处理速度为:11.18images/s