第一部分 算法原理及推导
1.1 算法原理介绍
背景介绍:ALS是交替最小二乘的简称,在机器学习上下文中,ALS特指使用交替最小二乘求解的一个协同过滤推荐算法。它通过观察到的所有用户给物品的打分,来推断每个用户的喜好并向用户推荐合适的物品。
核心假设:打分矩阵是近似低秩的,也就是说一个mn阶的打分矩阵 Rmn 可以用两个小矩阵Xkm和 Ykn的乘积来近似,即:

其中 k << min(m, n)
假设的合理性:描述一个人的喜好通常是在一个抽象的低维空间进行的,并不需要一一列出其具体喜好的事物,比如说一个人喜欢悬疑类电影,民谣歌曲.....
为了找到使得矩阵X和Y的乘积尽可能地逼近R,采用最小化平方误差损失函数:
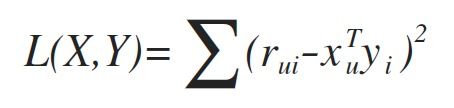
其中,rui 表示第u个用户对第 i 个物品的评分,xu (k 1阶)表示用户 u 的偏好隐含特征向量 1<= u <= m,yi (k1阶) 表示商品 i 的隐含特征向量 1<= i <= n,用户 u 对物品 i 的评分近似为:

为了防止过拟合,加入正则化项:

至此,协同过滤问题转化为一个优化问题,但是由于xu和yi耦合在一起,并不好求解,故引用ALS:先固定Y,由上式求解X,然后再固定求得的X,求解Y,如此交替执行直到误差满足阈值条件或者到达迭代次数上限。
1.2 推导过程
推导过程: 先随机生成Y,固定之,对损失函数L(X, Y)在xu上求偏导,并令其导数=0:

同理,由对称性得:
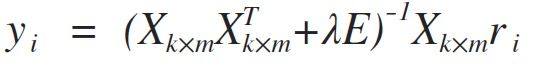
1.3 隐式反馈
以上针对显式反馈,对于隐式反馈的情形,损失函数如下:
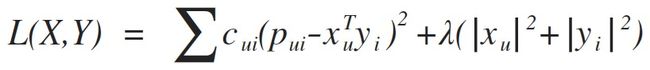

其中rui表示动作的频率,比如购买、加购物车、收藏、点击的次数,或者观看/收听视频/音频的时长等等,α是置信度系数,cui表示信任度,按照这种方式,我们存在最小限度的信任度,并且随着我们观察到的正偏向的证据越来越多,信任度也会越来越大。
推导过程类似显式反馈的公式推导,结果如下:

1.4 伪代码
1.4 伪代码
评分矩阵R(mn),最大迭代次数K,均方根误差阈值a,正则化系数lambda
随机初始化X(km), Y(kn), i = 0
While i < K and delta>=a
#计算每一个用户的隐含特征向量
for u = 1,2.......m do
#计算中间结果矩阵tmp01
tmp01 = YY.T + lambdaE
#对中间结果矩阵tmp01求逆
tmp02 = tmp01.I*
#计算中间结果矩阵tmp03
tmp03 = tmp02Y
#计算用户 u 的隐含特征向量, Ru为用户对每个物品的 n 维评分向量
xu = tmp03Ru
end for
#更新用户隐含特征向量
X(km) = (x1,x2,.....xm)
#计算每一个物品的隐含特征向量
for j = 1,2.......n do
#计算中间结果矩阵tmp01
tmp01 = XX.T + lambdaE
#对中间结果矩阵tmp01求逆
tmp02 = tmp01.I*
#计算中间结果矩阵tmp03
tmp03 = tmp02X
#计算物品 j 的隐含特征向量,Rj为所有用户对该物品的 m 维评分向量
yj = tmp03Rj
end for
#更新物品隐含特征向量
Y(kn) = (y1,y2,.....yn)
#迭代次数 +1
i = i + 1
#计算本次迭代之后实际评分矩阵与XY的近似评分矩阵之间的均方根误差
sum = 0
for p =1,2.....m
for q = 1,2,.....n
tmp = Rpq - Xp.TYq
sum = sum + tmptmp
delta = sqrt(sum/m*n)
Return X, Y
1.5 预测评分
通过1.3的伪代码实现之后得到Xkm和 Ykn
若预测所有用户对所有物品的评分,即:Predict_All = X(km).T * Y(kn)
若预测某一用户 i 对所有物品的评分,即:Predict_User = X(ki).T * Y(kn)
若预测所有用户对某一物品 j 的评分,即:Predict_User = X(km).T * Y(kj)
若预测某一用户 i 对某一物品 j 的评分,即:Predict_User = X(ki).T * Y(kj)
第二部分 Spark实现
2.1 实现关键点
Spark MLlib实现ALS的关键点:通过合理的分区设计和RDD缓存来减少节点间的数据交换
首先,Spark会将每个用户的评分数据 u 和每个物品的评分数据 v 按照一定的分区策略分区存储,如下图:u1和u2在P1分区,u3在P2分区,v1和v2在Q1分区。

ALS求解过程中,如通过U求V,在每一个分区中 u 和 v 通过合理的分区设计使得在同一个分区中计算过程可以在分区内进行,无需从其他节点传输数据,生成这种分区结构分两步:
第一步、在P1中将每一个U发送给需要它的Q, 将这种关系存储在该块中,称作OutBlock
第二步、在Q1中需要知道每一个V和哪些U有关联及其对应的打分,这部分数据不仅包含原始打分数据,还包含从每个用户分区收到的向量排序信息,称作InBlock。
所以,从U求解V,我们需要通过用户的OutBlock信息把用户向量发送给物品分区,然后通过物品的InBlock信息构建最小二乘问题并求解。同理,从V求解U,我们需要物品的OutBlock信息和用户的InBlock信息。
对于OutBlock和InBlock只需扫描一次建立好信息并缓存,在以后的迭代计算过程中可以直接计算,大大减少了节点之间的数据传输。
2.3 Spark实现与1.4 伪代码区别
1.4 中的伪代码实现属于单机简化实现,在Spark的MLlib中实现的分布式并行版本所做的主要调整和过程如下:
1、将数据分为若干个区,每个分区都只包含用户和物品的一部分数据块,通过分区实现并行更新用户或者物品的每个隐含特征向量
2、在每个分区中更新隐含特征向量时需要构建最小二乘法的两部分信息,一部分是用户/物品特征矩阵,一部分是用户/物品评分向量;第二部分信息通过2.1中介绍的实现关键点构建用户/物品的InBlock和OutBlock信息获得。
3、 在每一步迭代过程中,每一个分区都会计算所在分区的用户或者物品物品特征向量,然后去更新对应用户或者物品的特征向量,从而实现并行。